集成学习③——Sklearn-Adaboost库参数及实战
一、Adaboost库参数介绍
Adaboost库分为AdaBoostClassifier(分类)和AdaBoostRegressor(回归),两者的参数相近,均包括Adaboost框架参数和使用的弱学习器参数,详细如下:
1、框架参数
① base_estimator: 弱学习器,AdaBoostClassifier和AdaBoostRegressor都有。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。常用的一般是CART决策树或者神经网络MLP。如果选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
② n_estimators: 弱学习器数量,两者都有,一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50。在实际调参的过程中,常常将n_estimators和下面介绍的参数learning_rate一起考虑。
③ learning_rate:弱学习器的权重缩减系数,取值范围为0~1。对于同样的训练集拟合效果,较小的ν意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的ν开始调参,默认是1。
④algorithm:分类算法,AdaBoostClassifier才有,可选SAMME和SAMME.R。两者的区别是弱学习器权重的度量,SAMME使用分类器的分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此默认是用SAMME.R。一般直接使用默认,注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
⑤ loss:误差的计算函数,只有AdaBoostRegressor有,可选线性‘linear’, 平方‘square’和指数 ‘exponential’, 默认是线性,一般使用线性就足够了。这个值的意义在原理篇我们也讲到了,它对应了我们对第k个弱分类器的中第i个样本的误差的处理,即:如果是线性误差,则eki=|yi−Gk(xi)|Ek;如果是平方误差,则eki=(yi−Gk(xi))2E2k,如果是指数误差,则eki=1−exp(−yi+Gk(xi))Ek),Ek为训练集上的最大误差Ek=max|yi−Gk(xi)|i=1,2…m
2、弱分类器参数
弱分类器参数要根据所选弱分类器而定,一般使用CART决策树,参数如下:
① criterion: 特征选取方法,分类是gini(基尼系数),entropy(信息增益),通常选择gini,即CART算法,如果选择后者,则是ID3和C4,.5;回归是mse或mae,前者是均方差,后者是和均值的差的绝对值之和,一般用前者,因为前者通常更为精准,且方便计算
② splitter: 特征划分点选择方法,可以是best或random,前者是在特征的全部划分点中找到最优的划分点,后者是在随机选择的部分划分点找到局部最优的划分点,一般在样本量不大的时候,选择best,样本量过大,可以用random
③ max_depth: 树的最大深度,默认可以不输入,那么不会限制子树的深度,一般在样本少特征也少的情况下,可以不做限制,但是样本过多或者特征过多的情况下,可以设定一个上限,一般取10~100
④ min_samples_split:节点再划分所需最少样本数,如果节点上的样本树已经低于这个值,则不会再寻找最优的划分点进行划分,且以结点作为叶子节点,默认是2,如果样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定
⑤ min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数,可以输入一个具体的值,或小于1的数(会根据样本量计算百分比)
⑥ min_weight_fraction_leaf: 叶子节点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是0,就是不考虑权重问题。这个一般在样本类别偏差较大或有较多缺失值的情况下会考虑
⑦ max_features: 划分考虑最大特征数,不输入则默认全部特征,可以选 log2N,sqrt(N),auto或者是小于1的浮点数(百分比)或整数(具体数量的特征)。如果特征特别多时如大于50,可以考虑选择auto来控制决策树的生成时间
⑧ max_leaf_nodes:最大叶子节点数,防止过拟合,默认不限制,如果设定了阈值,那么会在阈值范围内得到最优的决策树,样本量过多时可以设定
⑨min_impurity_decrease/min_impurity_split: 划分最需最小不纯度,前者是特征选择时低于就不考虑这个特征,后者是如果选取的最优特征划分后达不到这个阈值,则不再划分,节点变成叶子节点
二、AdaBoostClassifier 应用
以sklearn库自带的手写数据集来分类
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
# ① 分类
digits = load_digits()
data = digits.data
target = digits.target
print(data.shape,target.shape)
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.1)
# 单棵决策树
clf = DecisionTreeClassifier(max_depth=5)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print("单棵决策树分类结果如下:")
print("混淆矩阵:")
print(confusion_matrix(y_pred,y_test))
print("训练集分数:",clf.score(x_train,y_train))
print("验证集分数:",clf.score(x_test,y_test))
# Adaboost分类器(多棵决策树)
clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=5),n_estimators=40)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print("Adaboost分类器(多棵决策树)分类结果如下:")
print("混淆矩阵:")
print(confusion_matrix(y_pred,y_test))
print("训练集分数:",clf.score(x_train,y_train))
print("验证集分数:",clf.score(x_test,y_test))
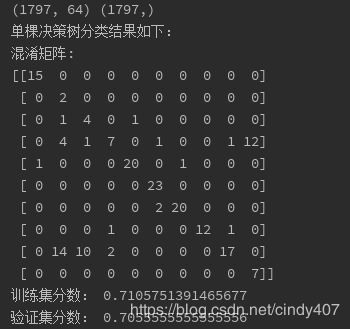

从分类效果看,Adaboost只有9个样本分错,而单个弱分类器(单棵决策树分错了51个,从模型评分看,Adaboost训练集达到99%的精度,并且在验证集也达到了95%,有较强的泛化能力,而单个分类器仅达到70%左右。
三、AdaBoostRegressor应用
以sklearn库自带的波士顿房价数据集来预测
#② 回归
from sklearn.datasets import load_boston
from sklearn.tree import DecisionTreeRegressor
from sklearn import metrics
from sklearn.ensemble import AdaBoostRegressor
from sklearn.model_selection import train_test_split
data,target = load_boston(return_X_y=True)
print(data.shape,target.shape)
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.1)
# 单棵回归树
clf = DecisionTreeRegressor(max_depth=5)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print("单棵回归树结果如下:")
print("训练集分数:",clf.score(x_train,y_train))
print("验证集分数:",clf.score(x_test,y_test))
print("均方误差:",metrics.mean_squared_error(y_test,y_pred))
# Adaboost回归学习器(多棵回归树)
clf = AdaBoostRegressor(DecisionTreeRegressor(max_depth=5),n_estimators=40)
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
print("Adaboost回归学习器(多棵回归树)结果如下:")
print("训练集分数:",clf.score(x_train,y_train))
print("验证集分数:",clf.score(x_test,y_test))
print("均方误差:",metrics.mean_squared_error(y_test,y_pred))
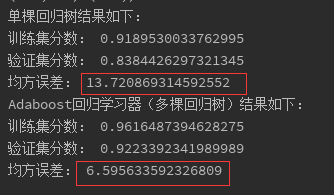
与单棵回归树相比,Adaboost的均方误差减少了一半,且模型分数也要更高。从分类和回归对比,可见集成学习器的强大之处,真的是三个臭皮匠顶个诸葛亮了