对于同级别的CPU产品而言,AMD CPU的单核性能(甚至总体性能)比Intel CPU的差,甚至差距不小,这是不争的事实。然而,几乎没有人问一句为什么如此,或者只是略知一二(包括我)。本文就用尽量浅显的语言探讨一下这个实际上极为复杂的问题。
鉴于Intel和AMD都没有披露新品的whitepaper的习惯,所以我用信息比较充足的有点久远的型号进行讲解,就是Intel的Sandy Bridge/Ivy Bridge(第2、3代酷睿)和AMD的Bulldozer/Piledriver(推土机、打桩机)微架构。目前来讲,两家的微架构设计都大体稳定,从比较新的Broadwell和Steamroller的各方面信息来看,它们仍然基本沿用了从Sandy Bridge和Bulldozer以来的方案,没有本质的变化。
(因此农企想要翻身,只能把希望寄托在遥不可及的Zen微架构上了)
首先来说基础知识,就是CPU是如何工作的。学习计算机科学的童鞋可能对下面的这些东西比较了解。
CPU之所以能完成这么多的事情,是因为它在时时都在执行着很多的指令(instructions)。指令就是我们所运行的操作系统和各种程序发送给CPU的命令,CPU根据这些指令来做出各种响应。
CPU能够执行的所有指令的集合就叫做指令集(instruction set)。目前我们最常见的Intel和AMD CPU,其都采用最经典的CISC x86指令集,以及在x86指令集上的某些扩展,也就是说绝大部分是相同的。
另外,CPU中还有两个重要的部件,分别为寄存器(register)和缓存(cache,为了方便简写为$),它们都担负着暂存指令或者数据的作用。
寄存器处于CPU内部,有很多组,是最高速的存储单元,容量非常小。缓存可以处于CPU内部或外部,其存储速度比寄存器慢,但比内存快得多,并且容量可以用KB或MB来衡量。另外,缓存可以分级,离CPU核心最近的叫做一级缓存(L1$),次近的叫做二级缓存(L2$),以此类推。
只有指令没有用,必须还要有一套方法来驱动CPU做事情,否则不过是空壳而已。这套方法就叫做流水线(pipeline)。
这个概念并不抽象,大家可以把它想象成工厂装配车间里的流水线:从一堆零部件开始,经过流水线上十几位工人的组装,最后出来的时候就变成了一台可以使用的设备。并且,工厂里肯定不只有一条流水线,可能有数十条,也就是上百甚至上千位工人同时工作,生产效率就会变得非常高。
从上世纪90年代的奔腾时代之前,CPU中就引入了流水线的概念。当时的5段流水线模型十分经典,其设计经过逐代扩充,目前仍然在用。这个经典的模型就是:
取指(Instruction Fetch)→译码(Instruction Decode)→执行(EXecute)→写回(Write Back)
分别简称为IF、ID、EX和WB,其中ID阶段有两段,分别称为ID1和ID2,所以一共5段。
顾名思义,这条流水线的逻辑就是:从缓存或者内存中取得指令→对指令进行翻译,变成CPU能够理解的具体功能→按照翻译结果,执行运算动作→将运算结果写回存储器中。很容易理解吧。
大家都知道,CPU的运作是靠时钟信号来驱动的,这个信号的频率就叫CPU的主频(main frequency),频率的倒数当然就是周期了。一般来讲,每个流水线阶段的执行需要花费1个时钟周期(clock cycle,为了方便简写为CC)。
因此,如果这样的流水线执行4条指令,那么它的执行时空图就如下。
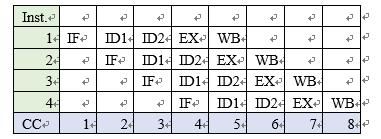
也就是说,采用这种流水线只需要8CC就可以执行4条指令,效率非常高。到了奔腾时代之后,更出现了超标量流水线(superscalar pipeline),也就是CPU中有多条流水线同时执行指令,效率几乎翻倍提高。另外,还出现了超流水线(super pipeline),也就是流水线的级数大大增加,规模明显提升。分别的示意图如下。

但是,这样的流水线设计也存在问题,具体来讲有二。
第一,考虑同一流水线中先后执行的两条指令1:add a,b和2:xor c,a,也就是说2需要1的计算结果,这种关系叫做相关性。当指令2执行到上表中第5个CC时,无法进入EX阶段,因为此时指令1的结果还未写回寄存器,也就是说指令2的EX阶段必须拖到第6个CC才可以执行,浪费了一个CC的时间,这叫做流水线的阻塞(stall)。超流水线级数越多,这种现象就越发明显,效率就越低。如下图。
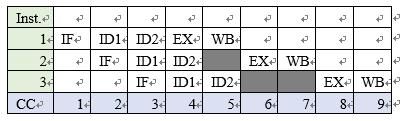
第二,考虑超标量流水线中,不同流水线中执行的两条指令。如果排在前面的指令执行速度太慢(比如涉及耗时严重的访存操作),那么会造成后面早已执行完毕的指令不得不等待,造成更严重的性能问题。
也就是说,基于线性通路的流水线,对于目前的复杂的微处理器而言是并不适用的。因此,Intel早早就提出了“乱序执行”(out-of-order execution, OOO EX)的概念,采用非完全线性的通路来规避这个问题。也就是这样的。
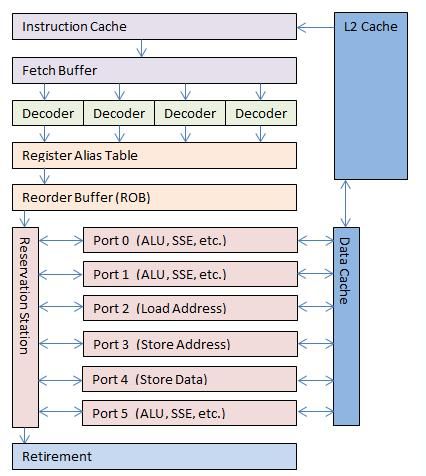
我借助这个图粗略讲一下现代处理器的执行过程。
上图是一个四发射、乱序执行的流水线框图,从1995年以来的Intel处理器基本都采用类似的设计方案。所谓多发射(multiple issue),就是处理器能够同时获取并译码多条指令,目前的处理器几乎都是四发射设计。
首先,在取指过程中,会多出一个分支预测(branch prediction, BP)的阶段,图中未明确示出。分支预测器能检测诸如跳转、返回等动作的大致发生时机,并提前把跳转目的地的指令加载到指令缓存(I$)中,以提高效率。
然后,经过多个译码器的译码,指令被分解成为上文所述的CPU能够理解的操作,这些叫做微操作(μop)。微操作被送入寄存器别名表(RAT),进行重命名,以防止多条指令共用一个对程序猿非透明的寄存器时产生的相关性,简单来讲,就是用内部的临时寄存器来替代一般我们能见到的寄存器来进行操作。重命名完毕后,微操作进入后面的重排序缓存(ROB)中,进行重新排列。
然后就是乱序执行的重点了。微操作从保留站(reservation station, RS)中,分别打入不同的执行端口(port),同时执行。每个端口都是全速运行的,只要微操作准备就绪,并且有空闲的对应端口,那么它就可以立即被执行,而不用关心其他微操作的执行状态,也就是可以跳过任何还没有准备就绪的微操作。这样,流水线产生阻塞的可能性就大大地降低了。每个port都可以负责一种或多种事务,如整数运算、浮点运算、存数据、取地址等。
当一条指令分解成的所有微操作被执行完毕之后,它们会返回保留站,并通知各自的地址,通过地址可以将微操作重新聚合为一条完整的指令。完成的指令排成一个队列,并退出流水线。也就是说,尽管所有指令的碎片是乱序执行的,但从流水线中出来时,它们仍然是顺序的,就跟自然而然的一样。
基础知识讲完了,下面开始对比,看看农企为何不太给力。这方面的内容非常多而且繁杂,我会打一些草稿,因此本帖更新会持续到明天,请大家见谅。
为了描述方便,后面用SNB/IVB代表Sandy Bridge/Ivy Bridge,BDZ/PDV代表Bulldozer/Piledriver。
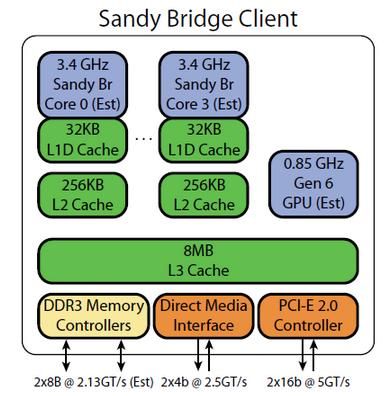
首先看SNB和BDZ的简单框图。下面的是以i7 2600为例。
下面的则是以八核心Opteron为例,毕竟图上写了个Interlagos Node,反正是推土机就好了,你们可以把它当成FX-8150之类的。
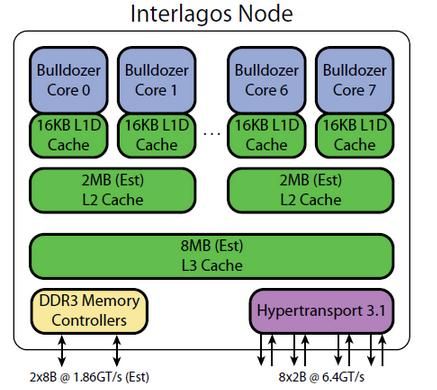
我们都知道,Intel的CPU采用超线程(hyper threading, HT)技术,使得一个物理核心对高层而言看起来像是两个核心一样,这种逻辑的、虚拟的核心在Intel的概念内叫做线程。而AMD的CPU采用模块化设计,就是每两个物理核心集合为一个模块,AMD将它命名为计算单元(compute unit, CU),一个CU中的两个核心协同完成事务。也就是说,i7是四核心、八线程,FX是四模块、八核心,本质上可以近似认为是一样的。
另外,从图中还可以看到内存控制器、显示控制器、HyperTransport控制器等,并且还能大致观察到它们的缓存结构,下面当然也会细说。
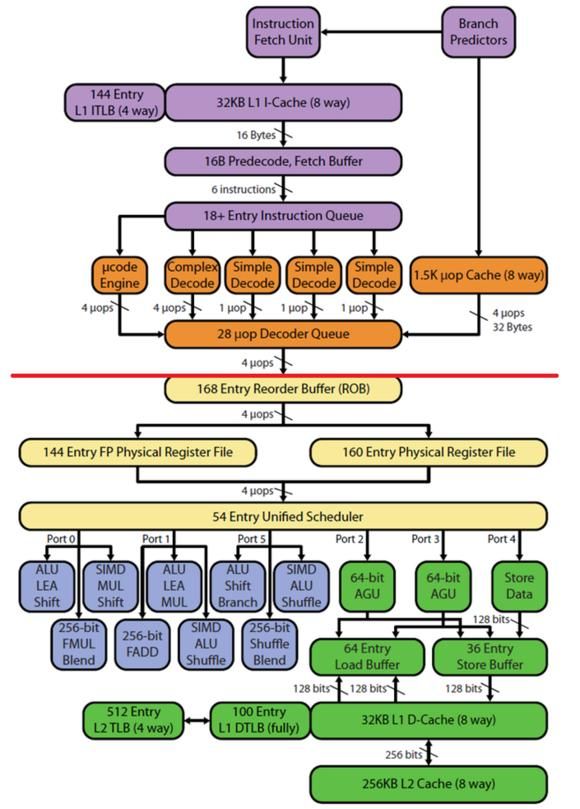
下面给出SNB/IVB架构的全图。
下面给出BDZ/PDV架构的全图。
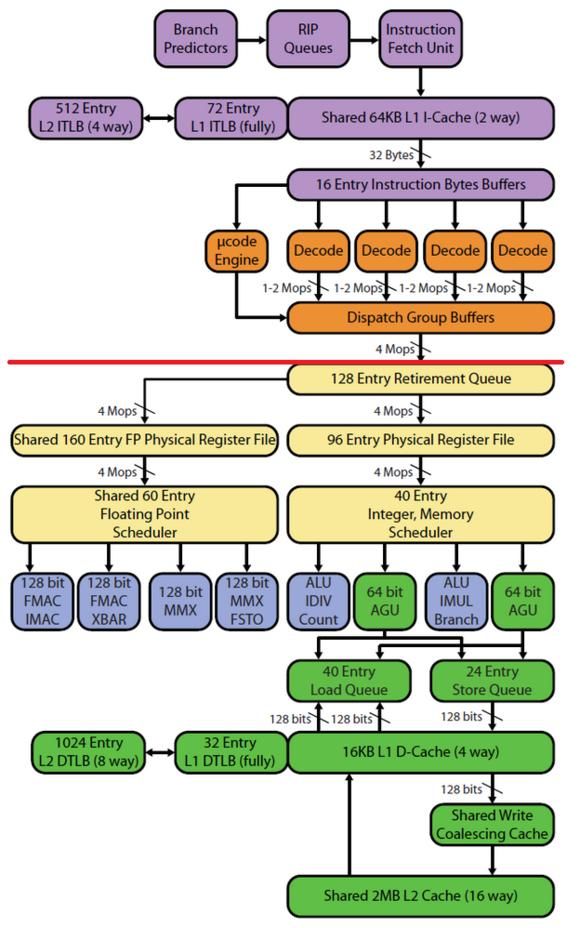
可以看到,上面的两张图被中间的一条红线分为两个区域。红线上面的部分叫处理器前端(processor front-end),下面的部分叫处理器后端(processor back-end)。
另外,图中的方框也被五种颜色区分开了。前端部分包括紫色和橙色,紫色的为取指(IF)和分支预测(BP)模块,橙色的为译码(ID)模块。后端部分包括黄、蓝、绿三种颜色,黄色的为调度和保留站(RS)模块,蓝色的为执行(EX)模块,绿色的为存储(MEM)模块。我们逐个来讨论。
首先看取指和分支预测模块。下图是SNB/IVB的该模块。
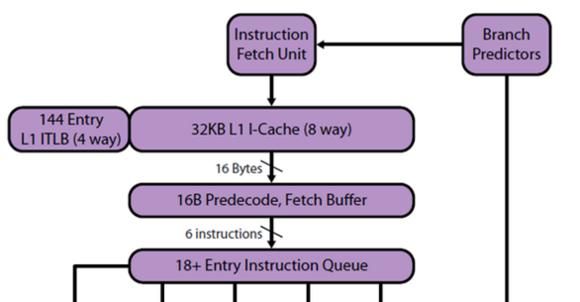
下图是BDZ/PDV的该模块。
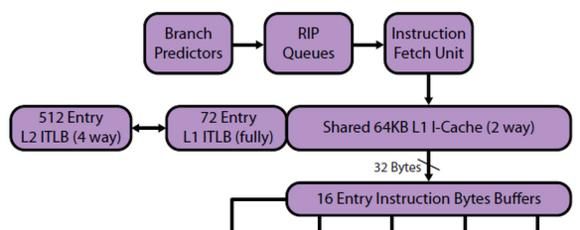
我们来比较分支预测机制,就是图中的Branch Predictors。
SNB/IVB的分支预测器有两级,每个核心有一个。第一级预测器很小,但速度极快,可以在1CC内完成一次分支预测。第二级则大得多,作为一个后备。预测器的成分包括:简单的2-bit预测器、全局历史预测器、循环退出预测器。Intel在内部自建有一套算法,用于判断当前哪个预测器的准确度较高,并选用之。
SNB/IVB的分支目标缓存(branch target buffer, BTB)结构目前大多认为是1层,具体细节未知,但基本上会有多达8K甚至16K条条目(”reasonably large”)。对于每16个字节长的代码段,它能hold住最多4条跳转指令。另外,返回栈的缓存有16条。
当然,如果预测错误的话,必然会造成时间损失(因为流水线几乎会被flush掉),这叫做误预测罚时(misprediction penalty)。SNB/IVB的罚时大约为15~17CC。
BDZ/PDV的分支预测器则是每个模块有一个,由两个核心共享,采用本地预测+全局预测的混合预测方式。AMD在其内部使用了感知器(perceptron),像神经元一样跟随并记忆分支结果,因此在经过一段时间的训练过程后,对较长的跳转有较好的表现。但其内部并无循环计数器,因此对于嵌套较深的循环表现比较差。
BDZ/PDV的BTB结构是两层组相连的缓存。L1 BTB有128组*4路=512条,L2 BTB有1024组*5路=5120条。返回栈的缓存则是有24条。误预测罚时大约为20~25CC。
我们大致需要知道的是:BP的误预测率越高,误预测罚时越长,那么整个BP模块的效率就越低。AMD宣称BDZ/PDV的BP效率较其上一代的K10(Barcelona/Magny-Cours)架构为高,但实际上是相反的。K10的误预测罚时只有12~15CC(当然,K10是没有采用比较先进的模块化设计的),也就是说,在同频率下,对于那些风险比较大的分支,BDZ必须要比K10达到40%以上的正确预测率的提升,才能弥补罚时的损失,但这是不可能的事情。相对而言,SNB/IVB的BP效率比较高,预测器中的一个bit可以对应多条分支,并且有了黑科技μop$的加成(下面会提到),误预测带来的损失会更小。
上面有大神在回复中提到说,推土机有些像奔腾4时代的NetBurst架构。这种说法还是比较中肯的。BDZ虽然没有NetBurst那么恐怖的流水线级数(比如Prescott的39级流水线),但仍然比较长,有18~20级,并且分支预测的时间损失都比较大,都没有实现“通过提高主频就可以简单地提升性能”的设想。
下面来看取指过程。
对于SNB/IVB而言,当下一条指令的地址确定之后,就会同时查询L1I$和μop$(下面就提到),一次可以从I$取得16B的代码段。然后,取得的指令会被放入下面的预译码缓存中。预译码器会划分这些指令的边界,并对指令前缀进行译码。随后,经过预译码的指令以每个CC 6条的速度,送入下面的指令队列中,准备接受译码。SNB/IVB的指令队列长度未知,但由于早在Merom架构时,其长度就达到了18条,因此几乎可以肯定这里的指令队列长于18条。
对于BDZ/PDV而言,取指模块仍然是由两个核心共享的。在两个核心都活动的情况下,它最多可以一次从I$取得32B的代码段;在一个核心活动的情况下,则是最多20B的代码段。当代码没有对齐时,取指的速率会有降低。指令在I$中划分边界,然后以32B/CC的速率,进入16个条目的指令码缓存,作用和Intel的指令队列是相同的。
转—笔吧/坎达拉克沙