【笔记1-2】基于维基百科的开放域问题问答系统DrQA
Reading Wikipedia to Answer Open-Domain Questions
- (一)论文概述(摘要+简介)
- (二)相关研究
- (三)DrQA
- 1. Document Retriever (提取文章)
- 2. Document Reader (回答问题)
- 2.1 Paragraph encoding
- 2.2 Question encoding
- 2.3 Prediction
- (四)数据介绍
- 1. 维基百科
- 2. SQuAD
- 3. 开放域QA
- 4. Distant supervision (DS)
- (五)实验
- (六)结论
https://arxiv.org/pdf/1704.00051.pdf
Reading Wikipedia to Answer Open-Domain Questions
最近在读陈丹琦学姐的博士毕业论文,论文里面涉及到的关键论文和模型都会在近期进行总结,以帮助理解毕业论文中的相关模型以及思想。
【笔记1-1】基于对话的问答系统CoQA (Conversational Question Answering)
【笔记1-3】斯坦福机器阅读理解模型Stanford Attentive Reader
【笔记1-4】陈丹琦毕业论文 NEURAL READING COMPREHENSION AND BEYOND
(一)论文概述(摘要+简介)
出发点: 以往的机器阅读理解任务所包含的数据集都十分有限,不仅局限于某一个领域,而且往往是基于文章进行答案检索,这对于人们日常生活中的检索需求而言,不太相符。而维基百科作为一个随时更新的知识库,有着很多人们感兴趣的内容,如果能让机器也能阅读这样海量的知识文档,并准确回答我们所需的问题,这对于我们检索并了解知识而言十分有用,因此提出了这个基于维基百科的开放域问题问答系统DrQA。
该文章以维基百科作为知识来源,建立了一个开放域问答系统DrQA,用于处理大规模机器阅读任务(MRS, machine reading at scale)。
模型包含两个部分,分别是Document Retriever和Document Reader,分别用于从广大的数据来源中提取与问题相关的文章,根据提取的文章找到问题的答案,完成阅读理解工作。
实验结果表明文章建立的两个部分的模型和其他已有的模型相比效果较好;多任务学习以及远距离监督的结合对于这一项任务而言十分有效。
(二)相关研究
根据作者在文中用到的思想,方法和数据,对以下相关研究进行了对比分析:
- 以往的开放域回答都基于非结构化的文档展开,尽管随着knowledge bases(KBs)的发展,许多数据实现了创新,但KBs依旧存在不完整,模式固定的缺点。
- 对于机器阅读理解的发展,现在已经有了很多表现较好的模型,但除了传统的数据库之外,这些模型的表现还没有在开放域问题上得到检验。
- 对于维基百科这一数据来源,有过将维基百科与其他数据结合,用维基百科进行阅读理解答案修正的研究,但该文章将维基百科作为唯一数据来源,以明确模型在大规模机器阅读任务(MRS)上的表现。
- 使用网页完成问答的模型还有AskMSR, DeepQA, YodaQA, 但这些模型都有多个数据来源,为该文章模型的表现评估提供了一个参考上界。
- 多任务学习和任务迁移也是经常用于机器阅读的工具,尤其是自然语言处理领域。以往的研究都致力于通过多任务学习实现多个问答数据集的结合:利用任务迁移来提高模型在数据集上的表现;利用数据集的多样性提供一个能回答各种问题的工具。
(三)DrQA
总体上,DrQA具有以下几个特点:
- 将bigram与TF-IDF结合,使用哈希降维,减少存储空间;
- 段落的字符编码考虑了词嵌入,词性,与问题相关的硬注意力以及软注意力;
- 通过远程监督为传统数据集扩充样本,结合多任务学习;
- 使用维基百科作为唯一数据来源,不需要预先划定段落重点;

1. Document Retriever (提取文章)
模型概述:
对于相关文章提取部分,作者采用了经典的信息检索(非机器学习)思想来缩小搜索范围:分别计算问题和文章的bigram的TF-IDF向量,然后结合两个TF-IDF得到与问题最相关的五篇文章。
这种基于统计的做法可以保证检索速度。缺点在于完全基于统计的做法忽略了词与词之间的内在含义的关联性,且与Document Reader分离,无法进行端对端训练。
具体实现:
- 对语料单词进行清洗,包括去停词等过滤操作
- 统计所有的bigram,并对bigram做同样规则的清洗得到最终的bigram
- 将这些bigram进行murmur3 hashing得到每个bigram的id(如果哈系特征数目设置过小,可能会有两个不同bigram的id相同,文章用了特征数目为2^24,可以尽量避免这种哈希冲突)
- 根据TF-IDF公式计算每个bigram的IDF向量以及TF向量,将IDF乘以TF得到TF-IDF向量
- 将问题的TF-IDF向量与文章的TF-IDF向量相乘取最大的前五个的文章的索引,得到与问题最相关的5篇文章(因为TF-IDF是衡量一个词(或其他形式的元组)对一个文档的重要性,如果一些词既对于问题很重要,又对于文章很重要,那么就可以得出结论这个问题与这个文章的关联性很大)
2. Document Reader (回答问题)
模型概述:
给定一个带有 l l l 个记号(token) { q 1 , . . . . . . , q l } \{q_1,......,q_l\} {q1,......,ql}的问题 q q q 以及一个包含 n n n 个段落的文档(或文档集合)每个段落 p p p 包含 m m m 个记号 { p 1 , . . . . . . , p m } \{p_1,......,p_m\} {p1,......,pm}
轮流对每个段落应用一个RNN模型,得到预测的答案。
2.1 Paragraph encoding
- 将每一个token p i p_i pi 转换成特征向量 p i ~ ∈ R d \tilde{\mathbf{p_i}}\in \mathbb{R}^d pi~∈Rd
- 将特征向量 p ~ \tilde{\mathbf{p}} p~ 作为多层双向RNN(LSTM)的输入,取各隐藏层的隐藏单元得到 p \mathbf{p} p
{ p 1 , . . . . . . p m } = R N N ( { p 1 ~ , . . . . . . , p m ~ } ) \{\mathbf{p_1,......p_m}\} = RNN(\{\tilde{\mathbf{p_1}},......,\tilde{\mathbf{p_m}}\}) {p1,......pm}=RNN({p1~,......,pm~})
RNN输出得到的 p i \mathbf{p_i} pi 包含了token p i p_i pi 附近的上下文信息
需要特别指出的是,这里的特征向量 p i ~ \tilde{\mathbf{p_i}} pi~并不像传统的embedding矩阵那么简单,而是由以下三个部分组成:
- word embedding: f e m b ( p i ) = E ( p i ) f_{emb}(p_i) = \mathbf{E}(p_i) femb(pi)=E(pi)
使用训练好的300维Glove词向量,保留绝大多数词向量,对出现频率最高的1000个单词进行fine-tune,比如常见的who, when, how, what, where,这些单词对于QA系统十分关键; - Exact match: f e x a c t _ m a t c h ( p i ) = I ( p i ∈ q ) f_{exact\_match}(p_i) = \mathbb{I}(p_i\in q) fexact_match(pi)=I(pi∈q)
引入了三个二值特征,分别表示该单词是否对应于问题中的某一个单词,是否是小写原始形式,是否是词根形式,这三个特征对于结果十分有效; - Token features: f t o k e n ( p i ) = ( P O S ( p i ) , N E R ( p i ) , T F ( p i ) ) f_{token}(p_i) = (\mathbf{POS}(p_i),\mathbf{NER}(p_i),\mathbf{TF}(p_i)) ftoken(pi)=(POS(pi),NER(pi),TF(pi))
这个特征用来描述词本身的属性,包括词性(part-of-speech, POS)、命名体(named entity recognition, NER)以及归一化的词频(term frequency, TF),三者拼接组成一个向量; - Aligned question embedding: f a l i g n ( p i ) = ∑ j a i , j E ( q j ) f_{align}(p_i) = \sum _{j} a_{i,j}\mathbf{E}(q_j) falign(pi)=∑jai,jE(qj)
这个特征用来描述paragraph中每个单词与question中每个单词对齐的embedding,用 a i j a_{ij} aij表示paragraph中的单词 p i p_i pi 与question中的单词 q j q_j qj 的相似度,称为attention score。
a i , j = e x p ( α ( E ( p i ) ) ⋅ α ( E ( q j ) ) ) ∑ j ′ e x p ( α ( E ( p i ) ) ⋅ α ( E ( q j ′ ) ) ) a_{i,j} = \frac{exp(\alpha(\mathbf{E}(p_i))\cdot\alpha(\mathbf{E}(q_j)))}{\sum_{j'}exp(\alpha(\mathbf{E}(p_i))\cdot \alpha(\mathbf{E}(q_{j'})))} ai,j=∑j′exp(α(E(pi))⋅α(E(qj′)))exp(α(E(pi))⋅α(E(qj)))
其计算方式为:将每个embedding E \mathbf{E} E 经过一层ReLU激活函数的全连接网络,各自相乘并且归一化。
特征跟Exact match中的第一个二值化特征很像,但exact match从名字就可以看出是判断是否完全一样,而这里是用相似度来度量,即使两个单词不一样,意思相近的话,相似度也会高,相当于软注意力机制,Exact Match则相当于硬注意力机制;
2.2 Question encoding
Question的编码简单一些:
- 将token q i q_i qi 的word embedding q i \mathbf{q_i} qi 作为RNN的输入
- 将RNN的隐含单元加权拼接到一起组成一个向量: { q 1 , . . . . . . , q l } → q \{\mathbf{q_1},......,\mathbf{q_l}\} \rightarrow \mathbf{q} {q1,......,ql}→q,
q = ∑ j b j q j \mathbf{q}=\sum_{j}b_j \mathbf{q_j} q=∑jbjqj,其中权重因子 b j b_j bj 通过将每个单词的embedding q j \mathbf{q_j} qj乘以一个可以学习的权重向量 w \mathbf{w} w 并经过softmax得到:
b j = e x p ( w ⋅ q j ) ∑ j ′ e x p ( w ⋅ q j ′ ) b_j = \frac{exp(\mathbf{w}\cdot \mathbf{q_j})}{\sum_{j'}exp(\mathbf{w}\cdot \mathbf{q_{j'}})} bj=∑j′exp(w⋅qj′)exp(w⋅qj)
2.3 Prediction
由于最终的答案一定是从paragraph中生成的,因此只用找到答案在paragraph中的单词区间,即找到开始字符和结束字符各自的位置即可。
对于开始和结束的位置,训练两个分类器,将段落向量 { p 1 , . . . . . . p m } \{\mathbf{p_1,......p_m}\} {p1,......pm} 和问题向量 q \mathbf{q} q 作为输入,获取 p i \mathbf{p_i} pi 和 q \mathbf{q} q 之间的相似度,通过两个带有exp函数的线性网络分别计算每个字符成为开始字符和结束字符的概率:
P s t a r t ( i ) ∝ e x p ( p i W s q ) P_{start}(i) \propto exp(\mathbf{p_i}\mathbf{W_s}\mathbf{q}) Pstart(i)∝exp(piWsq) P e n d ( i ) ∝ e x p ( p i W e q ) P_{end}(i) \propto exp(\mathbf{p_i}\mathbf{W_e}\mathbf{q}) Pend(i)∝exp(piWeq) 在预测的过程中,选择从token i i i 到token i ′ i' i′的最佳范围,该最佳范围满足: i ≤ i ′ ≤ i + 15 i \leq i' \leq i+15 i≤i′≤i+15 且 P s t a r t ( i ) ∗ P e n d ( i ′ ) P_{start}(i) * P_{end}(i') Pstart(i)∗Pend(i′) 最大。
在训练过程中,将 P s t a r t ( i ) P_{start}(i) Pstart(i) 和 P e n d ( i ′ ) P_{end}(i') Pend(i′) 记为start_score和end_score,则损失函数由两个部分相加得到,即start_score与target_start的负对数似然函数加end_score与target_end的负对数似然函数得到最终的损失函数,进而可以使用反向传播来更新所有参数。
(四)数据介绍
1. 维基百科
wikipedia:作为寻找问题答案的知识库
只保留文字,一共5075182篇文章和9008962个不同的字符
2. SQuAD
SQuAD:用来训练document reader
基于维基百科的机器阅读数据集,训练集包含87k个示例,开发集包含10k个示例,以及一个很大的隐藏测试集,可以通过Creator获取。
每个样本包含一个自然段、问题和人工答案,通常用exact string match与F1 score两种评估方法,都是在字符级别进行评估。
SQuAD是最大的问答数据集,但本文的模型定位是用于开放领域的问答系统,所以仅用SQuAD数据集训练和评估Document Reader的机器阅读理解能力,在SQuAD验证集上做测试。
与其他论文中的测试不同的是,这里作者剔除了自然段,仅仅给出问题以及wikipedia数据库,让模型自己去匹配对应的自然段然后找出答案。
3. 开放域QA
CuratedTREC、WebQuestions、WikiMovies:用来测试模型在开放域数据集上的表现,并用于衡量多任务学习和DS的效果。
与SQuAD不同,这三个数据集只包含问题和答案,没有关联的文档或段落,因此无法用来直接训练Document Reader。
作者采取了Mintz在论文Distant supervision for relation extraction without labelled data中提出的Distant Supervised方法来构建训练集,该方法的核心思想是基于已有的关系库来为训练样本匹配文章。(见下)
4. Distant supervision (DS)
具体步骤:
(1)基于数据集中的问题,使用document retriever提取相关性最高的5篇文章。
(2)对于五篇文章中的所有段落,抛弃不包含与已知答案完全匹配(no exact match)的段落,抛弃小于25个字大于1500个字的段落,若有的段落中包含命名实体,抛弃那些不包含命名实体的段落
(3)对于留下来的所有段落,从段落中找出包含答案的span,这里是基于word水平的,也就是unigram,首先找到段落中包含答案的完整区间[start, end],然后基于20 token window,从start向左延展20个word,从end向右延展20个word(要保证左右两边不能溢出,溢出则取边界)得到一个备选小段落
(4) 从备选小段落中找出最有可能的5个小段落,要与问题进行比较。分别对每个小段落统计它的bigram,同时也统计问题的bigram,最后统计每个小段落的bigram与问题的bigram有多少交集,最后对交集求和,求和总数最多的5个小段落为最有可能的段落。比如小段落的bigram是{‘i am’:2, ‘you are’:3, ‘how are’: 1},问题的bigram是{‘i am’: 3, ‘you are’: 1},交集是{‘i am’:2, ‘you are’:1},求和就是3次。
(五)实验
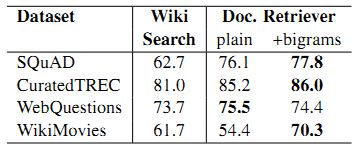
(1)首先对document retriever进行测试,结果表明这一文档检索工具比wikipedia search的效果更好,尤其是在引入bigram哈希的时候。
(2)然后对document reader部分进行测试。
在具体实现过程中,作者使用三层双向LSTM,包含128个隐藏单元,对段落和问题进行编码,使用Stanford CoreNLP toolkit做标记(tokenization)词性生成以及命名实体标签。按照段落长度对训练样本进行排序,将样本分成大小为32的mini-batch,使用adamax作为优化器,对词嵌入和LSTM隐藏单元使用p=0.3的dropout
结果表明,作者提出的这个理论上较为简单的模型表现很好,并对前文所述的特征向量进行了切除分析。分析结果表明只去除 f a l i g n f_{align} falign这个特征对模型表现影响不大,但是同时去除 f a l i g n , f e x a c t m a t c h f_{align}, f_{exact_match} falign,fexactmatch模型的表现就会大幅度下降,这可能是因为两者的作用相似又互补。


(3)最后对DrQA模型整体进行实验,将DrQA用于前述数据库,并对比分析多任务学习和远距离监督的效果。
先在SQuAD上训练一个简单地document reader,然后基于SQuAD预训练一个document reader并使用每个数据集的远距离监督(DS)训练集对模型进行fine-tune,最后在SQuAD以及其他DS训练集上集合训练一个document reader。
结果表明引入DS和多任务学习对模型的提升效果不明显,表明其中存在任务迁移,而DS的单独引入对模型的提升可能是由于额外数据的引入,最终最好的模型是multitask (DS)

(六)结论
本文基于MSR任务,利用维基百科构建了一个开放域的问答系统DrQA,由document retriever和document reader两个部分组成,分别负责文章提取和阅读理解。实验结果表明,引入多任务学习以及远距离监督(DS)的模型效果最好。