yolo v1原理
目标检测系列文章
yolo v1原理:https://blog.csdn.net/cjnewstar111/article/details/94035842
yolo v2原理:https://blog.csdn.net/cjnewstar111/article/details/94037110
yolo v3原理:https://blog.csdn.net/cjnewstar111/article/details/94037828
SSD原理:https://blog.csdn.net/cjnewstar111/article/details/94038536
FoveaBox:https://blog.csdn.net/cjnewstar111/article/details/94203397
FCOS:https://blog.csdn.net/cjnewstar111/article/details/94021688
FSAF: https://blog.csdn.net/cjnewstar111/article/details/94019687
基本原理
将输入图像划分为S*S(最终feature map的大小)个cell,每一个cell预测B个bounding boxes,以及这些bounding boxes的confidence scores(置信度),以及C个类别概率。由于一个cell只有一组分类概率,所以在yolov1中,一个cell只能预测一个物体。训练过程中,ground truth的中点落在哪个cell中,那个cell就负责预测这个ground truth框。

网络结构
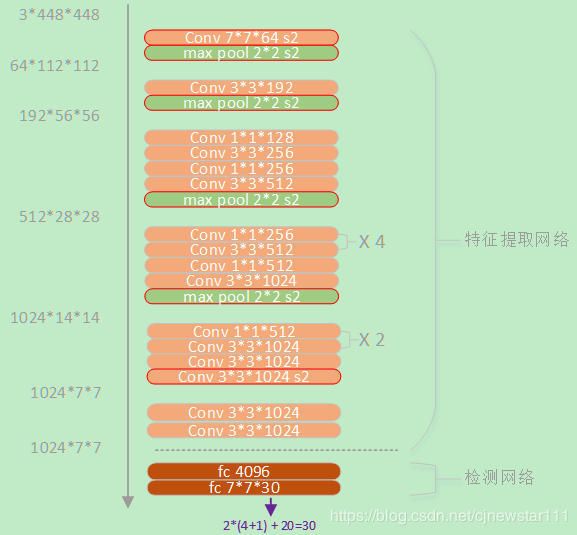
摘自论文翻译:我们的网络架构受图像分类模型GoogLeNet的启发。我们的网络有24个卷积层,后面是2个全连接层。我们只使用1×1降维层,后面是3×3卷积层,这与Lin等人类似,而不是GoogLeNet使用的Inception模块。完整的网络如图所示。我们还训练了快速版本的YOLO,旨在推动快速目标检测的界限。快速YOLO使用具有较少卷积层(9层而不是24层)的神经网络,在这些层中使用较少的滤波器。除了网络规模之外,基本版YOLO和快速YOLO的所有训练和测试参数都是相同的。我们网络的最终输出是7×7×30的预测张量。
实现细节:
S*S格的划分
其实就是看CNN提取特征最后一层的输出大小。原始论文中输入是448*448,最后输出的feature map是7*7(缩小64倍),那么就划分为7*7的cell。每一个cell最终会产生一个30维的向量(B=2,一个cell产生2个bounding box的坐标位置和置信度,以及20个类别的概率 B(4+1)+20=30)。
正负样例的选择
一个cell中有多个bounding box,那么具体是哪个bounding box作为有效的,而其他作为无效的呢?训练过程中,将每个预测的bounding box和gt求IOU。这个cell中的哪个bounding box与gt的iou大,那么这个bounding box就就是有效的bounding box,作为正样例(response bounding box)。其他bounding box就作为负样例(not response bounding box)。(有的资料中需要把iou小于某一个阈值,才作为负样例。其实区别不大,就是在计算负样例的置信度loss的时候的数量不一样而已)
一个cell中有多个gt怎么处理?
这个是yolo v1的缺点,一个cell只有一组概率预测,也就是一个cell只能预测一个物体。所以如果一个cell中有多个gt,那么只能选择其中的一个用来训练。
位置信息
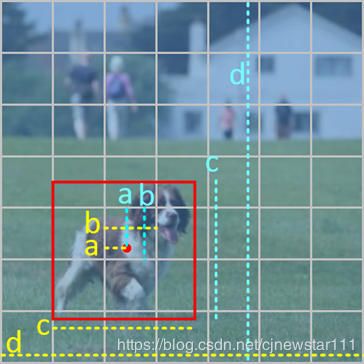
位置信息采用归一化的(X中心,Y中心,宽,高)表示
X中心的归一化采用相对cell的x轴长度表示。图中的黄色虚线a/黄色虚线b
Y中心的归一化采用相对cell的y轴长度表示。图中的蓝色虚线a/蓝色虚线b
宽的归一化表示采用相对原始图片的宽度表示。图中的黄色虚线c/黄色虚线d
高的归一化表示采用相对原始图片的高度表示。图中的蓝色虚线c/蓝色虚线d
置信度(confidence)
bounding box的置信度 = 该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU
![]()
损失函数
损失函数分为三部分:坐标误差,置信度误差和分类误差
置信度误差针对所有的bounding box都要计算。由于无效的bounding box多,所以无效bounding box的置信度有一个系数系数0.5
坐标loss针对有物体的bounding box(response bounding box)计算,分类loss针对有物体的cell计算
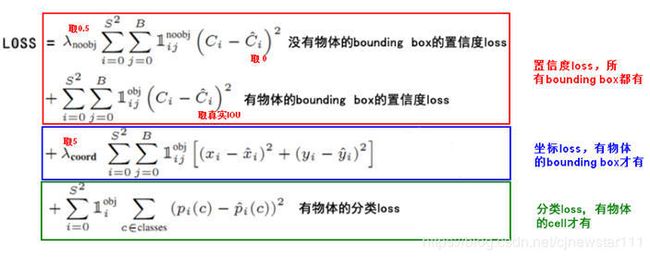
如何判断一个bounding box是有效的还是无效的
首先是判断gt的中点有没有落在cell里面,如果落在cell里面,那么预测的两个bounding box,哪个和gt的iou大,哪个就是有效的bounding box,是正样例(response bounding box),而iou小的就作为负样例(not response bounding box)。有些资料里面把iou小于某一个阈值才作为负样例。
yolo推理
yolo推理的时候,把置信度乘以分类的最高概率,作为一个bounding box的得分,然后大于某一个阈值的得分的bouding box再送到NMS里面处理,最终得出输出框
数据增强
通过改变训练数据的饱和度,曝光度,色调,抖动进行数据增强
yolo v1的优缺点
优点:
速度快,达到了完全实时的效率
错误率低(相对于faster rcnn会把很多背景预测为物体)
泛华能力强(在美术绘画作品中也有较好的效果)
缺点:
定位不够精确(map低)
对小目标检测效果不好(召回率低)
参考资料
《真的,关于深度学习与计算机视觉,看这一篇就够了 | 硬创公开课 》
《物体检测-回归方法(YOLO+SSD) 》
《 RCNN学习笔记(10):SSD:Single Shot MultiBox Detector 》
《YOLOv1论文理解》
《YOLO详解》来自
《YOLO: Real-Time Object Detection 官网》来自
《【YOLO】详解:YOLO-darknet训练自己的数据》来自
《TensorFlow-YOLO代码阅读笔记——YOLO中的Loss是如何计算的?》来自
《YOLO v1的详解与复现》http://www.cnblogs.com/xiongzihua/p/9315183.html
github开源实现 https://github.com/xiongzihua/pytorch-YOLO-v1