Mycat入门学习理解
一、安装
从官网下载符合自己要求的Mycat版本,安装步骤可以根据官网提供的权威指南来操作,也可以在网上搜索安装教程,教程比较多,这里提供一个windows的安装教程地址,可以参考一下:
https://blog.csdn.net/smilefyx/article/details/72810531
注意:
(1)本地安装jdk(根据mycat的版本安装对应版本的jdk)
(2)本地安装mysql(根据mycat的版本安装对应版本的mysql)
(3)需要在本地的环境变量中配置jdk和mysql
二、Mycat的认识
Mycat是一个开源的分布式数据库系统,但是由于真正的数据库需要存储引擎,而Mycat并没有存储引擎,所以并不是完全意义的分布式数据库系统,它更贴切的可以说成是数据库的中间件。
Mycat是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务。传统的我们,访问数据库是直接连接数据库,创建数据库实例,根据需求对数据库中的数据进行增删查改。但是,当我们使用mycat后,我们其实直接连接是mycat,通过mycat对真正的数据库进行操作,在mycat上我们可以做一些分表,分库等操作,达到我们对数据库的高可用的要求。
当我们使用mycat的时候,我们需要创建一些逻辑库,逻辑表,分片规则等配置信息,对应真实数据库的库,来进行数据库的操作。
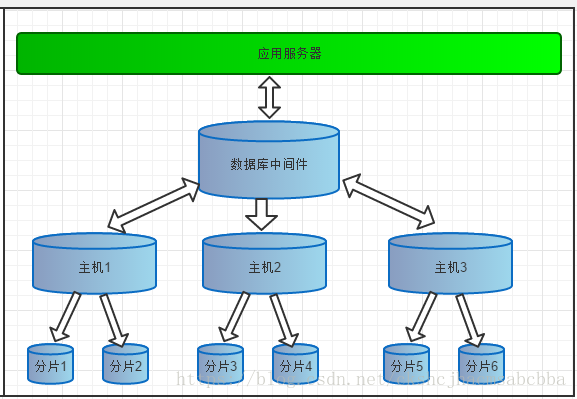
数据库中间件:代表mycat
主机1,主机2,主机3:代表真正数据库服务的主机地址
分片1,2,3,4,5,6:代表我们经过mycat对数据库进行切分后,创建在对应主机上的真正数据库
如上图所表示,数据被分到多个分片数据库后,应用如果需要读取数据,就要需要处理多个数据源的数据。如果没有数据库中间件,那么应用将直接面对分片集群,数据源切换、事务处理、数据聚合都需要应用直接处理,原本该是专注于业务的应用,将会花大量的工作来处理分片后的问题,最重要的是每个应用处理将是完全的重复造轮子。
所以有了数据库中间件,应用只需要集中与业务处理,大量的通用的数据聚合,事务,数据源切换都由中间件来处理,中间件的性能与处理能力将直接决定应用的读写性能,所以一款好的数据库中间件至关重要。
三、mycat的基本配置步骤
使用mycat时,我们一般需要经历这几个步骤:
(1)创建逻辑库
我们需要配置conf/server.xml文件,schema 标签用于定义MyCat实例中的逻辑库,MyCat可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。
此时,我们已经配置好我们需要创建的逻辑库。
(2)创建逻辑表
当我们创建好我们需要的逻辑库后,我们需要创建库里面的逻辑表,此时我们需要配置conf/schema.xml,Table 标签定义了MyCat中的逻辑表,所有需要拆分的表都需要在这个标签中定义。
dataNode(分片节点):数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)
dataHost(节点主机):数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)
rule(分片规则):一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
此时我们的逻辑表创建完毕,我们需要配置我们的分表规则,也就是rule="auto-sharding-long" 对应的规则。
(3)创建rule规则
创建规则,该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中name属性属性值一一对应
name :属性指定唯一的名字,用于标识不同的表规则。
内嵌的rule标签则指定对物理表中的哪一列进行拆分和使用什么路由算法。
columns:指定要拆分的列名字。
algorithm: 使用function标签中的name属性。连接表规则和具体路由算法。当然,多个表规则可以连接到同一个路由算法上。table标签内使用。让逻辑表使用这个规则进行分片。
Tips:
mycat对数据库表的切分操作,基本按照这个步骤,根据自己的要求,在对应的配置文件中,填写配置信息,完成操作需求。希望对大家的mycat的入门认识能有所帮助。
mycat还有很多的配置参数,以上介绍的几个参数都是基础的参数配置,其他的参数配置根据我们的业务需求,可以参考mycat官网的权威指南,里面有详细的介绍。
当我们修改配置文件后,需要重启服务。