phoenix 5.0 CURSOR 游标
都在一起,讲几个点:
1、phoenix使用游标实例
2、游标对SQL的支持情况
3、phoenix游标与map reduce感受
1、phoenix使用游标实例
官网地址:
https://phoenix.apache.org/cursors.html
官网示例很清晰明了,只不过使用存在几处问题。
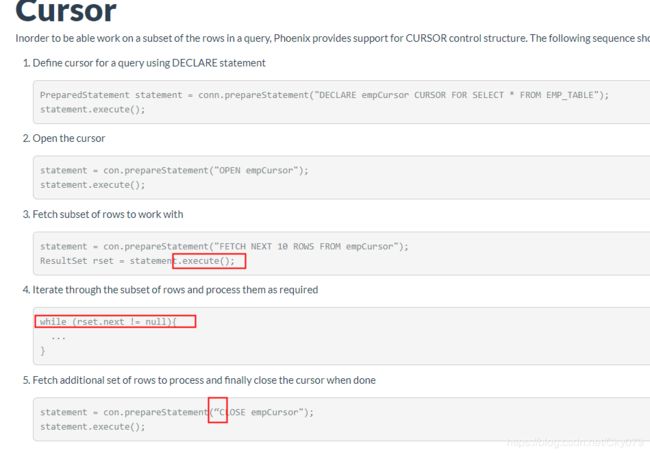
1、将execute() 改为 executeQuery() 这样rset才能接收。
2、rset.next() 就好。
3、中文的引号,哈哈。(含义很深~)
直接贴上我的测试代码:
public static void main(String[] args) throws SQLException, ClassNotFoundException {
long start = System.currentTimeMillis();
// 获得连接资源
Connection con = PhoenixUtils.getConnection();
ResultSet rset = null;
// 游标语句
PreparedStatement statement = con.prepareStatement("DECLARE empCursor CURSOR FOR select show_date,email,seq_id,time_spend,cam_site,token_earned,revenue,tips_sent,toy from T_EXTENSION_SHOW where show_date='2018-11-25'");
statement.execute();
// 开启游标
statement = con.prepareStatement("OPEN empCursor");
statement.execute();
boolean flag = true;
int countTotal=0;
do{
int count=0;
// 一次拿5000条
statement = con.prepareStatement("FETCH NEXT 5000 ROWS FROM empCursor");
rset = statement.executeQuery();
while (rset.next()){
count++;
countTotal++;
System.out.println(rset.getString("seq_id"));
}
// 没有数据,停止循环读取
if(count!=5000){
flag = false;
}
}while(flag);
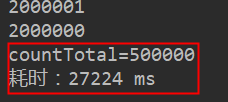
System.out.println("countTotal="+countTotal);
// 关闭游标
statement = con.prepareStatement("CLOSE empCursor");
statement.execute();
PhoenixUtils.colseResource(con,statement,rset);
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) +" ms");
}执行结果,耗时情况。
将where条件去掉后,我们再试试性能如何:
DECLARE empCursor CURSOR FOR select show_date,email,seq_id,time_spend,cam_site,token_earned,revenue,tips_sent,toy from T_EXTENSION_SHOW;
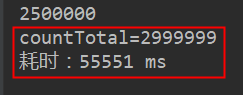
性能结论:
phoenix的游标,性能还是可以的。
我们可以使用游标来获取数据,去做一些分析的工作。
最好是where条件是带时间的,按照天、或者小时,这样的时间区间去分析数据。
2、游标对SQL的支持情况
使用游标,对SQL的支持情况:
-- 正确(可以用函数)
select age,count(1) num from test group by age;
-- 正确(可以用条件、排序这些)
select id,name,age from test where id in(66,3,92);
-- 错误(子查询不支持)
select id,name,age from test where id in(select id from test where id in(66,3,92));
Exception in thread "main" org.apache.phoenix.exception.PhoenixParserException: ERROR 602 (42P00): Syntax error. Missing "LPAREN" at line 1, column 37.
at org.apache.phoenix.exception.PhoenixParserException.newException(PhoenixParserException.java:33)
at org.apache.phoenix.parse.SQLParser.parseStatement(SQLParser.java:111)
at org.apache.phoenix.jdbc.PhoenixStatement$PhoenixStatementParser.parseStatement(PhoenixStatement.java:1644)
at org.apache.phoenix.jdbc.PhoenixStatement.parseStatement(PhoenixStatement.java:1727)
at org.apache.phoenix.jdbc.PhoenixStatement$ExecutableDeclareCursorStatement.compilePlan(PhoenixStatement.java:949)
at org.apache.phoenix.jdbc.PhoenixStatement$ExecutableDeclareCursorStatement.compilePlan(PhoenixStatement.java:941)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:401)
at org.apache.phoenix.jdbc.PhoenixStatement$2.call(PhoenixStatement.java:391)
-- 正确(可以支持join,但是两个表数据过大,内存不足会有报错情况。这个锅还是join的问题,和游标无关。)
select t1.* from test t1 inner join test t2 on(t1.id=t2.id) where t1.id in(66,3,92)
-- 错误(join,子查询不支持)
select t1.* from test t1,(select id,name,age from test where id in(66,3,92)) t2 where t1.id=t2.id;
select t1.* from test t1 inner join (select id,name,age from test where id in(66,3,92)) t2 on(t1.id=t2.id);
Exception in thread "main" java.lang.NullPointerException
at org.apache.phoenix.compile.JoinCompiler$JoinTableConstructor.resolveTable(JoinCompiler.java:187)
at org.apache.phoenix.compile.JoinCompiler$JoinTableConstructor.visit(JoinCompiler.java:224)
at org.apache.phoenix.compile.JoinCompiler$JoinTableConstructor.visit(JoinCompiler.java:181)
at org.apache.phoenix.parse.DerivedTableNode.accept(DerivedTableNode.java:49)
at org.apache.phoenix.compile.JoinCompiler$JoinTableConstructor.visit(JoinCompiler.java:201)
at org.apache.phoenix.compile.JoinCompiler$JoinTableConstructor.visit(JoinCompiler.java:181)
游标sql语句总结:
1、游标对select语句是有要求的,最好的方式就是单表。
2、支持sum等函数,where条件,以及join操作(join慎用,内存问题)。
3、不支持子查询,换句话说就是 (不支持二次查询的结果来做游标处理,只支持第一手数据。)
对于大数据的join操作,是不是可以使用 游标处理呢?期待一下。
3、phoenix游标与map reduce感受
如果是使用时间区间分析数据,cursor操作方便,支持更好。
map reduce不支持
Note: The SELECT query must not perform any aggregation or use DISTINCT as these are not supported by our map-reduce integration.
结论:
简单说,
增量统计的情况使用cursor,方便快捷。
而全量统计的时候就使用map reduce,利用集群环境的优势计算统计。