R语言基本备忘-统计分析
Part1 相关统计量说明
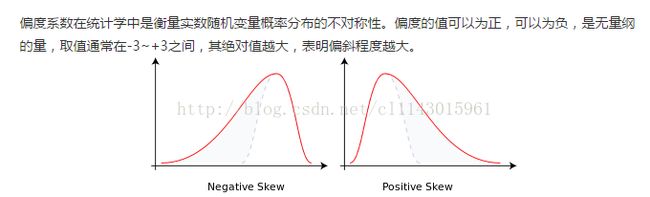
峰度系数Coefficientof kurtosis
http://baike.baidu.com/link?url=gS_sgtNYSRdjLnadNWDDa357DIzJma-tdheAx5eKp0WzTvuH_PYg8hnMNIiP4-DRmewtftVQXXUbtIYzvz4bTq
峰度系数(Kurtosis)用来度量数据在中心聚集程度。在正态分布情况下,峰度系数值是3(但是SPSS等软件中将正态分布峰度值定为0,是因为已经减去3,这样比较起来方便)。>3的峰度系数说明观察量更集中,有比正态分布更短的尾部;<3的峰度系数说明观测量不那么集中,有比正态分布更长的尾部,类似于矩形的均匀分布。

偏度系数skew
http://www.itongji.cn/article/0R326462013.html

SEMean 是 Standard error ofthe mean的缩写,
标准误差平均值,也叫平均数标准误差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度。SE Mean的计算公式如下:
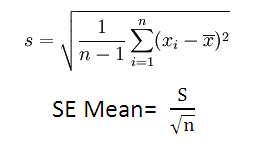
http://www.pinzhi.org/thread-7741-1-1.html
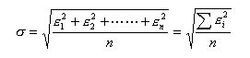
均方误差MeanSquared Error, MSE
数理统计中均方误差是指参数估计值与参数真值之差平方的期望值,记为MSE。MSE是衡量“平均误差”的一种较方便的方法,MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。与此相对应的,还有均方根误差RMSE、平均绝对百分误差等等。
标准偏差StdDev,Standard Deviation
标准偏差反映数值相对于平均值(mean) 的离散程度。
http://baike.baidu.com/link?url=_oBhB0gpULQI0aGZ3Xju0u5bxN9X6RonOb_aGEHOJGdUe5J0WfR5H_8ANijgzEmgmWZmnu0H9z0zK_q2ebmTp_

变异系数(Coefficientof Variation)

统计百科参考
http://www.itongji.cn/analysis/wiki/
http://www.bbioo.com/lifesciences/40-266598-1.html
Part2 R中基本统计函数实现
R语言中除本身有的获取统计量的方法summary()之外,能得到描述性统计量的包有Hmisc、pastecs和psych。这里使用的数据是R中已有车辆路试(mtcars)数据集,挑取其中的几个字段,英里数(mpg)、马力(hp)和车重(wt)来做后续的示例数据集。
vars <- c(“mpg”,”hp”,”wt”)
summary(mtcars[vars])
#统计结果有最小值、最大值、平均值、上四分位数、下四分位数
library(Hmisc)
describe(mtcars[vars])
#统计结果有总数、缺失数、唯一值、平均值、各个分位数、最大值最小值五个
library(pastecs)
stat.desc(mtcars[vars])
#统计结果有总数、null数、NA数、最小、最大、差值、和、平均值、0.95置信区间均值、方差、标准差、变异系数desc=FALSE时,基本统计量总数、null数、NA数、最小、最大、差值、和norm=TRUE时,多六个个正态分布统计量,包括偏度和峰度(以及它们的统计显著程度)和Shapiro–Wilk正态检验结果。
library(psych)
describe(mtcars[vars])
#缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误差
注意:Hmisc包中describe()函数被新加载的包psych中的describe函数屏蔽,要使用Hmisc中的函数时,使用下面代码Hmisc::describe(mt)
获取分组统计量
aggregate()
aggregate(mtcars[vars], by = list(am =mtcars$am), mean)
aggregate(mtcars[vars], by = list(am =mtcars$am), sd)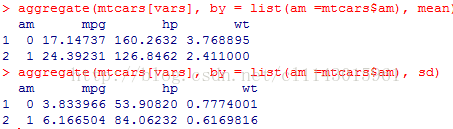
缺点:只能获取平均值、标准差这样的单值统计量。
by()可以自定义函数
dstats <- function(x){c(max=max(x),min=min(x))}
by(mtcars[vars], mtcars$am, dstats)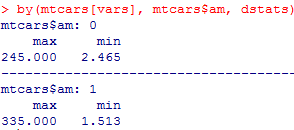
doBy包中的summaryBy()可以自定义函数

library(doBy)
summaryBy(mpg + hp + wt ~ am, data = mtcars,FUN = mystats)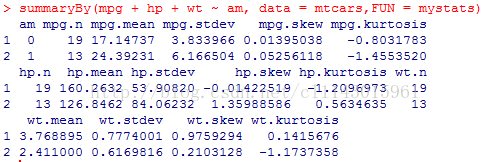
psych包中的describe.by()函数不能自定义函数,就是describe()方法中的那些统计量。若存在一个以上的分组变量,你可以使用list(groupvar1, groupvar2, ... , groupvarN)。
library(psych)
describe.by(mtcars[vars], mtcars$am)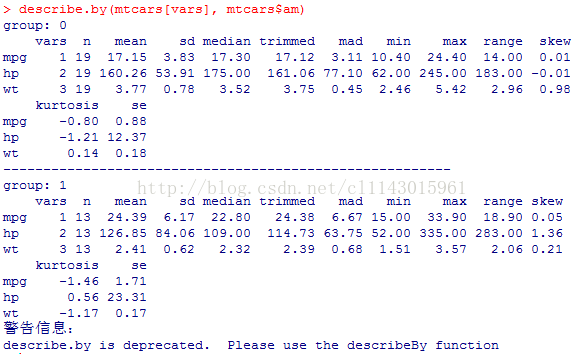
利用reshape包中的cast方法来自定义分组统计量的一个例子如下:
library(reshape)
dstats <- function(x) (c(n = length(x),mean = mean(x), sd = sd(x)))
dfm <- melt(mtcars, measure.vars =c("mpg", "hp", "wt"), id.vars = c("am","cyl"))
cast(dfm, am + cyl + variable ~ ., dstats)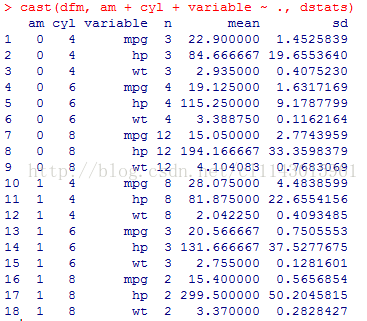
频数表和列联表
数据来自vcd包中的Arthritis数据集。这份数据来自Kock & Edward (1988),表示了一项风湿性关节炎新疗法的双盲临床实验的结果。
install.packages("vcd")
library(vcd)
head(Arthritis)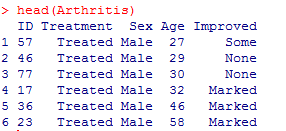
R中提供的创建频数表和列联表的方法有下面几种:

一维列联表
mytable <- with(Arthritis,table(Improved))#某一列的频数统计表
mytable
prop.table(mytable)#根据频数统计表得到百分比表
prop.table(mytable)*100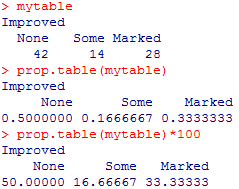
二维列联表
mytable <- xtabs(~ Treatment+Improved,data=Arthritis)
mytable
margin.table(mytable, 1)#按行计数
prop.table(mytable, 1) #按行求百分比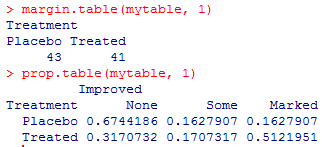
margin.table(mytable, 2)#按列计数
prop.table(mytable, 2)#按列求百分比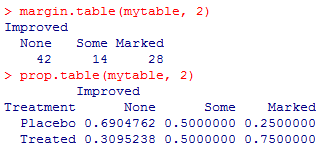
prop.table(mytable)#行列合计求百分比
addmargins(mytable)#对计数结果列求和
addmargins(prop.table(mytable))#对百分比结果列求和
addmargins(prop.table(mytable, 1), 2)#对百分比结果按行求和
addmargins(prop.table(mytable, 2), 1)#对百分比结果按列求和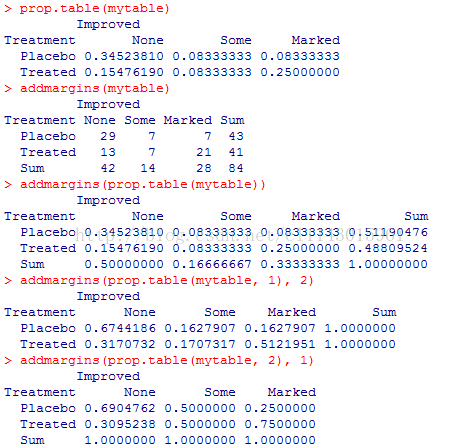
使用gmodels包中的CrossTable()函数是创建二维列联表的第三种方法。CrossTable()
函数仿照SAS中PROC FREQ或SPSS中CROSSTABS的形式生成二维列联表。CrossTable()函数有很多选项,可以做许多事情:计算(行、列、单元格)的百分比;指定小数位数;进行卡方、Fisher和McNemar独立性检验;计算期望和(皮尔逊、标准化、调整的标准化)残差;将缺失值作为一种有效值;进行行和列标题的标注;生成SAS或SPSS风格的输出。可参阅help(CrossTable)以了解详情。
install.packages("gmodels")
library(gmodels)
CrossTable(Arthritis$Treatment,Arthritis$Improved)
多维列联表
mytable <- xtabs(~Treatment+Sex+Improved, data=Arthritis)#生成三维表
mytable
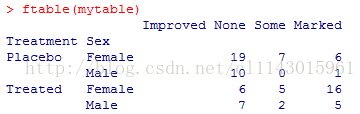
ftable(mytable)#以一种更紧凑的方式生成三维表
margin.table(mytable, 1)# 边际频数表
margin.table(mytable, 2)
margin.table(mytable, 3)
margin.table(mytable, c(1,3))# 治疗情况(Treatment)×改善情况(Improved)的边际频数
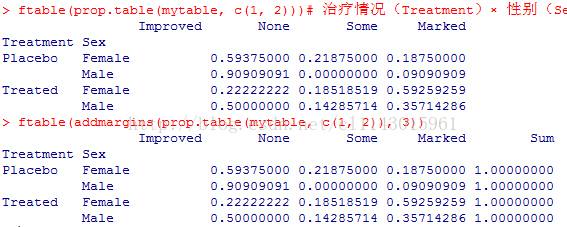
ftable(prop.table(mytable, c(1, 2)))# 治疗情况(Treatment)× 性别(Sex)的各类改善情况比例
ftable(addmargins(prop.table(mytable, c(1,2)), 3))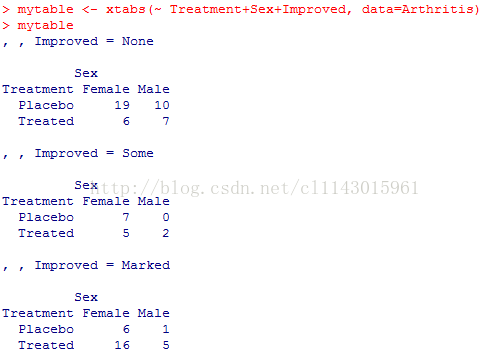

独立性检验
卡方独立性检验
chisq.test()函数对二维表的行变量和列变量进行卡方独立性检验。
library(vcd)
mytable <- xtabs(~Treatment+Improved,data=Arthritis)#治疗情况和改善情况
chisq.test(mytable)
mytable <- xtabs(~Improved+Sex,data=Arthritis)#性别和改善情况
chisq.test(mytable)
检验中,治疗情况和改善情况不独立(p < 0.01),患者性别和改善情况相互独立(p > 0.05)。卡方检验的介绍http://en.wikipedia.org/wiki/Pearson%27s_chi-squared_test。
Fisher精确检验
fisher.test()函数可进行Fisher精确检验,也是针对二维列联表进行的检验。Fisher精确检验的原假设是:边界固定的列联表中行和列是相互独立的。
mytable <- xtabs(~Treatment+Improved,data=Arthritis)
fisher.test(mytable)
上面p=0.001393,因此原假设不成立,治疗情况和改善情况之间存在关系,两者不独立。关于Fisher精确检验的介绍http://bioinformatics.lofter.com/post/bffd5_4cd73a。
Cochran-Mantel—Haenszel检验
mantelhaen.test()函数可用来进行Cochran—Mantel—Haenszel卡方检验,其原假设是,两
个名义变量在第三个变量的每一层中都是条件独立的。
mytable <-xtabs(~Treatment+Improved+Sex, data=Arthritis)
mantelhaen.test(mytable)
上面p-value=0.0006647,可以知道,患者接受的治疗与得到的改善在性别的每一水平下并不独立,即不管性别是什么,治疗情况和改善情况都存在关系。
相关性的度量
R提供了多种检验类别型变量独立性的方法,这里讲到三种检验分别为卡方独立性检验、Fisher精确检验和Cochran-Mantel–Haenszel检验。
vcd包中的assocstats()函数可以用来计算二维列联表的phi系数、列联系数和Cramer’s V系数。
library(vcd)
mytable <- xtabs(~Treatment+Improved,data=Arthritis)
assocstats(mytable)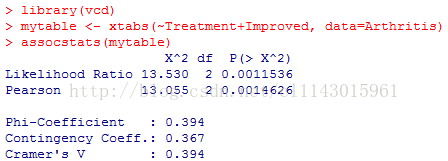
这些相关性系数的介绍及其计算方式不详细说明了,提供一个参考:
http://wenku.baidu.com/link?url=t-K9lISqB_fYQWIeETpCk7vmHUknflQwqnEU95Hg6gIGKl1nTX-AmlWGiAWk_SNG78-bHMW-pknDpunFFKTL1DeGeWb9ImcW-Li0YZ6bqzC。
Phi系数
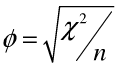
Φ相关系数的大小,表示两因素之间的关联程度。当Φ值小于0.3时,表示相关较弱;当Φ值大于0.6时,表示相关较强。适用于2×2表即四格表。
列联系数
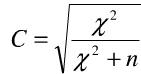
C系数的大小,表示两因素之间的关联程度。C系数可能的最大值依赖于列联表的行列数,并随行列增大而增大,只有行列数相同的列联表比较其列联系数的大小。
cramer’s V系数
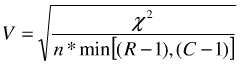
cramer’s V系数是Phi系数的修正值,适用于四格表,也适用于大于2×2表格,当行列有一个为二维时,V系数就等于Phi系数。
多维联表转换为扁平表格
table2flat <- function(mytable) {
df <- as.data.frame(mytable)
rows <- dim(df)[1]
cols <- dim(df)[2]
x<- NULL
for (i in 1:rows) {
for (j in 1:df$Freq[i]) {
row <- df[i, c(1:(cols - 1))]
x <- rbind(x, row)
}
}
row.names(x) <- c(1:dim(x)[1])
return(x)
}
treatment <- rep(c("Placebo","Treated"), 3)
improved <- rep(c("None","Some", "Marked"), each = 2)
Freq <- c(29, 13, 7, 7, 7, 21)
mytable <- as.data.frame(cbind(treatment,improved, Freq))
mydata <- table2flat(mytable)#
head(mydata)
相关
相关系数可以用来描述定量变量之间的关系。相关系数的符号(+、-)表明关系的方向(正相关或负相关),其值的大小表示关系的强弱程度(完全不相关时为0,完全相关时为1)。这一部分介绍多种相关系数和相关性的显著性检验方法。使用的数据是R中测试数据state.x77数据集,它提供了美国50个州在1977年的人口、收入、文盲率、预期寿命、谋杀率和高中毕业率数据。
R可以计算多种相关系数,包括Pearson相关系数、Spearman相关系数、Kendall相关系数、偏相关系数、多分格(polychoric)相关系数和多系列(polyserial)相关系数。接下来依次看这些数据。
Pearson、Spearman和Kendall相关
cor()函数可以计算这三种相关系数,而cov()函数可用来计算协方差。这两个方法的参数如下:

states <- state.x77[, 1:6]
cov(states)#计算states数据集的协方差
cor(states)# 计算states数据集的相关系数,默认pearson
cor(states, method="spearman")# 计算states数据集的spearman系数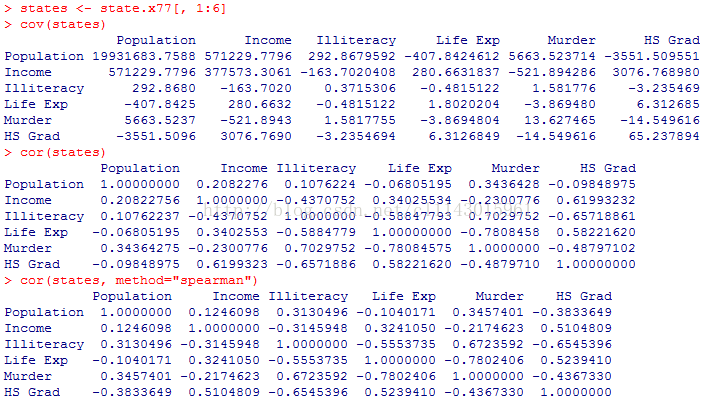
我们能看到收入和高中毕业率之间存在很强的正相关,文盲率和预期寿命之间存在很强的负相关,文盲率和谋杀率存在很强的正相关。还可以自己定义想要计算相关性的行列。
x <- states[, c("Population","Income", "Illiteracy", "HS Grad")]
y <- states[, c("Life Exp","Murder")]
cor(x, y)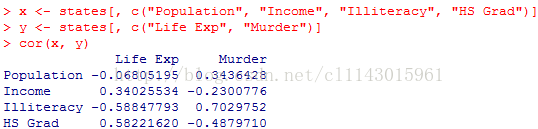
偏相关
偏相关是指在控制一个或多个定量变量时,另外两个定量变量之间的相互关系。
install.packages("ggm")
library(ggm)
pcor(c(1, 5, 2, 3, 6), cov(states))
pcor(c(3, 5, 1, 2, 6), cov(states))![]()
上面两个结果一是在控制了收入、文盲率和高中毕业率的影响时,人口和谋杀率之间的相关系数为0.3462724。二是在控制了人口、收入和高中毕业率的影响时,文盲率和谋杀率之间的相关系数为0.5989741,这个值已经很大了,说明这两者之间的关系很大。
相关性的显著性检验
cor.test()函数对单个的Pearson、Spearman和Kendall相关系数进行检验。使用格式如下:
cor.test(x, y, alternative=, method=)
x和y为要检验相关性的变量,alternative则用来指定进行双侧检验或单侧检验(取值
为"two.side"、"less"或"greater"),而method用以指定要计算的相关类型("pearson"、"kendall"或"spearman")。当研究的假设为总体的相关系数小于0时,请使用alternative="less"。在研究的假设为总体的相关系数大于0时,应使用alternative="greater"。默认情况下,假设为alternative="two.side"(总体相关系数不等于0)。
cor.test(states[, 3], states[, 5])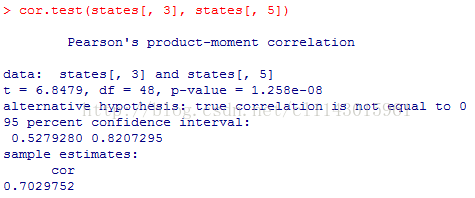
cor.test()方法有一个不足就是一次只能检验一种相关关系的,psych包中的corr.test()函数可以一次检验更多变量之间的相关性值和显著水平。其使用格式如下:
corr.test(x, y, use=, method=)
参数use=的取值可为"pairwise"或"complete"(分别表示对缺失值执行成对删除或行删除)。参数method=的取值可为"pearson"(默认值)、"spearman"或"kendall"。
library(psych)
corr.test(states, use ="complete")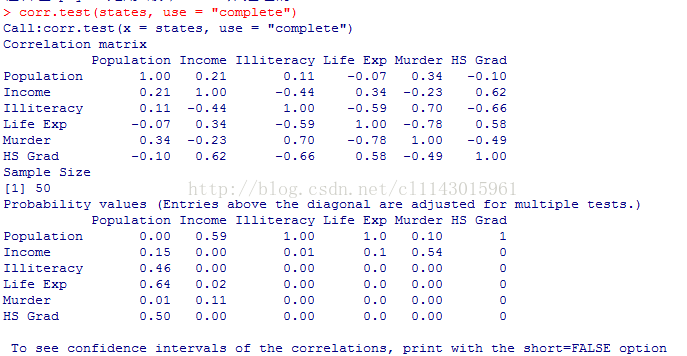
t检验
这里使用MASS包中的UScrime数据集。它包含了1960年美国47个州的刑罚制度对犯罪率影响的信息。我们感兴趣的结果变量为Prob(监禁的概率)、U1(14~24岁年龄段城市男性失业率)和U2(35~39岁年龄段城市男性失业率)。类别型变量So(指示该州是否位于南方的指示变量)将作为分组变量使用。
独立样本的t检验
library(MASS)
t.test(Prob ~ So, data=UScrime)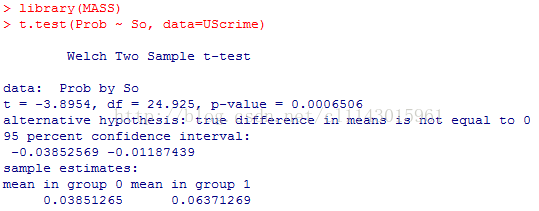
美国的南方犯罪,是否更有可能被判监禁?对象是南方和非南方各州,因变量为监禁的概率。结果是拒绝南方各州和非南方各州拥有相同监禁概率的假设(p < .001)。
非独立样本的t检验
library(MASS)
sapply(UScrime[c("U1","U2")], function(x) (c(mean = mean(x), sd = sd(x))))
with(UScrime, t.test(U1, U2, paired =TRUE))
较年轻(14~24岁)男性的失业率是否比年长(35~39岁)男性的失业率更高?在这种情况下,这两组数据并不独立。差异的均值(61.5)足够大,可以保证拒绝年长和年轻男性的平均失业率相同的假设。年轻男性的失业率更高。
参考:《R语言实战》
有任何问题建议欢迎指正,转载请注明来源,谢谢!