Kubernetes与大数据之四:基于Kubernetes的Spark运行Terasort(50GB data)
一、前言
Terasort可以测试Kubernetes平台对于Spark计算过程的如下需求的支持:
从HDFS读取能力
向HDFS写入能力
shuffle中网络读写能力
本文使用如下terasort的实现,包括TeraGen、TeraSort和TeraValidate:
https://github.com/ehiggs/spark-terasort
转载自https://blog.csdn.net/cloudvtech
二、准备工作
2.1 获取代码
git clone https://github.com/ehiggs/spark-terasort.git2.2 修改编译配置
指定合适的spark和scala版本
UTF-8
2.11.8
2.11
2.1.1
2.3 编译
mvn install
ls target/
archive-tmp generated-sources maven-status spark-terasort-1.1-SNAPSHOT-jar-with-dependencies.jar
classes jars site spark-terasort-1.1-SNAPSHOT-javadoc.jar
classes.440875732.timestamp maven-archiver spark-terasort-1.1-SNAPSHOT.jar surefire转载自https://blog.csdn.net/cloudvtech
三、运行
3.1 在hdfs建立数据目录
hadoop fs -mkdir /terasort3.2 建立spark运行的namespace和权限
admin-role.conf
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: spark-admin
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: spark-admin
namespace: spark
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark-admin
namespace: spark
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile建立spark namespace并绑定cluster-admin role
kubectl create namespace spark
kubectl apply -f admin-role.conf 3.3 运行TeraGen
run_spark_teragen.sh
/root/spark/bin/spark-submit \
--master k8s://https://192.168.0.3:6443 \ #master地址
--deploy-mode cluster \
--name spark-terasort \
--class com.github.ehiggs.spark.terasort.TeraGen \ #class地址
--conf spark.kubernetes.namespace=spark \ #namespace
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-admin \ #service account
--conf spark.kubernetes.container.image=192.168.0.3:5000/spark:terasort \ #镜像地址
--conf spark.eventLog.dir=hdfs://192.168.2.11:9000/eventLog \ #log地址
--conf spark.eventLog.enabled=true \ #打开log
--conf spark.executor.instances=50 \ #executor数目
--conf spark.driver.cores=2 \ #driver CPU数目
--conf spark.driver.memory=8g \ #driver内存
--conf spark.executor.memory=6g \ #executor内存
--conf spark.executor.cores=1 \ #executor CPU数目
--proxy-user hadoop \ #运行用户
local:///opt/spark/examples/jars/spark-terasort-1.1-SNAPSHOT-jar-with-dependencies.jar \
50g \ #数据大小
hdfs://172.2.2.11:9000/terasort/50g_generated #数据生成目录

3.4 运行TeraSort
run_spark_terasort.sh
/root/spark/bin/spark-submit \
--master k8s://https://172.3.0.3:6443 \
--deploy-mode cluster \
--name spark-terasort \
--class com.github.ehiggs.spark.terasort.TeraSort \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-admin \
--conf spark.kubernetes.container.image=172.3.0.3:5000/spark:terasort \
--conf spark.eventLog.dir=hdfs://172.2.2.11:9000/eventLog \
--conf spark.eventLog.enabled=true \
--conf spark.executor.instances=50 \
--conf spark.driver.cores=2 \
--conf spark.driver.memory=8g \
--conf spark.executor.memory=6g \
--conf spark.executor.cores=1 \
--proxy-user hadoop \
local:///opt/spark/examples/jars/spark-terasort-1.1-SNAPSHOT-jar-with-dependencies.jar \
hdfs://172.2.2.11:9000/terasort/50g_generated \
hdfs://172.2.2.11:9000/terasort/50g_sortedStages:

Executors:
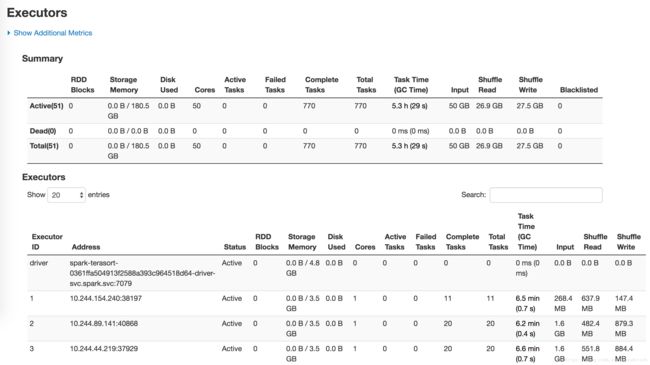
Tasks:

3.5 运行TeraValidate
run_spark_teravarify.sh
/root/spark/bin/spark-submit \
--master k8s://https://172.3.0.3:6443 \
--deploy-mode cluster \
--name spark-terasort \
--class com.github.ehiggs.spark.terasort.TeraValidate \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-admin \
--conf spark.kubernetes.container.image=172.3.0.3:5000/spark:terasort \
--conf spark.eventLog.dir=hdfs://172.2.2.11:9000/eventLog \
--conf spark.eventLog.enabled=true \
--conf spark.executor.instances=50 \
--conf spark.driver.cores=2 \
--conf spark.driver.memory=8g \
--conf spark.executor.memory=6g \
--conf spark.executor.cores=1 \
--proxy-user hadoop \
local:///opt/spark/examples/jars/spark-terasort-1.1-SNAPSHOT-jar-with-dependencies.jar \
hdfs://172.2.2.11:9000/terasort/50g_sorted \
hdfs://172.2.2.11:9000/terasort/50g_varified
3.6 运行概览
![]()
3.7 运行状态图示
系统资源使用情况

转载自https://blog.csdn.net/cloudvtech