Facebook页面受欢迎程度分析
目标是分析Facebook帖子的受欢迎程度与xxx特征的关系。需要用到的工具有jupyder,sklearn,pandas,numpy,matplotlib。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
filename = './dataset_Facebook.csv'
#read_csv()方法用于读取文件内容并以相应方式显示
pd_facebook=pd.read_csv(filename,delimiter = ';')
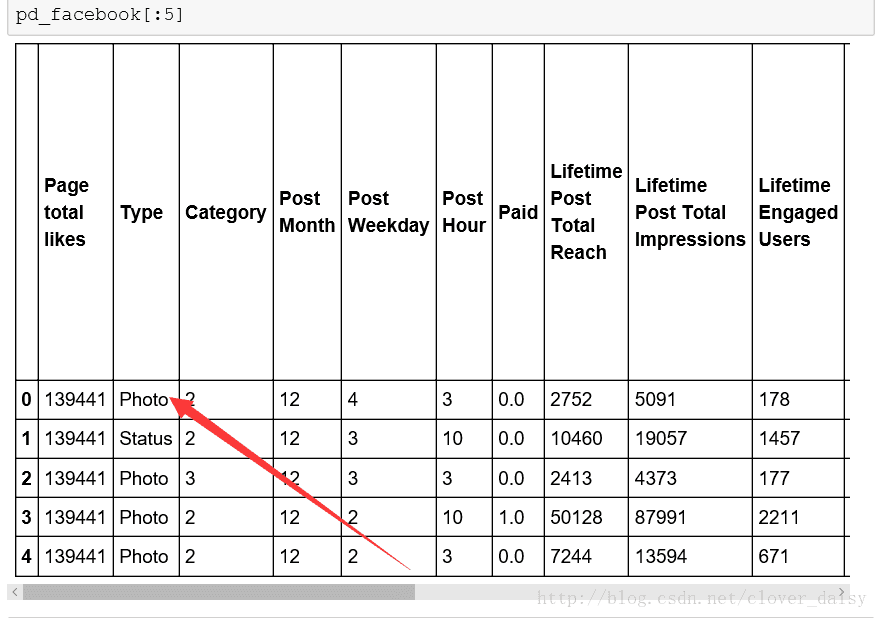
pd_facebook[:5]
#查看列名为Type的一列值
#pd_facebook['Type']
#获取列名
#pd_facebook.columns
#将Type列的数据转换为集合,集合元素唯一,由此确定有几种Type
set(pd_facebook.Type)#out:{'Link', 'Photo', 'Status', 'Video'}
#Type列的字符串类型转为数字
pd_facebook.Type = pd_facebook.Type.replace(['Link','Photo','Status','Video'],[0,1,2,3])
pd_facebook[:5]
#第一列作为y标准目标,其他列作为X特征值
dataset = pd_facebook.as_matrix()
#print(dataset.shape)
X = dataset[:,1:].astype(float)
y = dataset[:,0].astype(int)
#数据集归一化处理
X_max = X.max(axis = 0)
X_min = X.min(axis = 0)
X_one = (X-X_min)/(X_max - X_min)
from sklean.preprocessing import Imputer
#Imputer()是自动规避错误的方法
imputer = Imputer()
X = imputer.fit_transform(X_one)
#训练的数据X的个数
train_c = 100
train_i = np.random.randit(0,500,size = (train_c,))
train_x = X[train_i]
train_y = y[train_i]
#svm和knn算法
from sklearn import svm,neighbors
svm_rg = svm.SVR(C = 1e4,gamma = 0.1)
knn_rg = neighbors.KNeighborsRegressor()
svm_rg.fit(train_x,train_y)
knn_rg.fit(train_x,train_y)
s_y = svm_rg.predict(X)
k_y = knn_rg.predict(X)
#svm和knn的欧式误差
print(np.mean((s_y-y)**2)/1e4,np.mean((k_y-y)**2)/1e4)
#绘图
linspace = np.linspace(0,499,500)
#print(linspace)
plt.plot(linspace,y,'r',linspace,s_y,'g',linspace,k_y,'b')
plt.show()
第一次pd_facebook[:5]的输出结果
第二次pd_facebook[:5]的输出结果

两幅图片对比看到Type列由字符串类型转变成为数字类型。
绘图结果
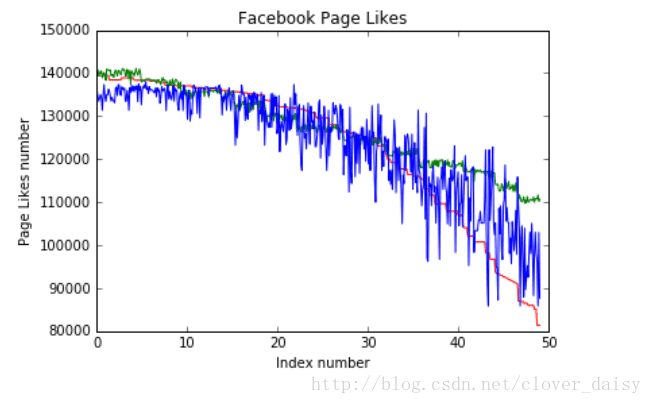
红色是y,代表标准结果;蓝色是k_y,代表knn算法的拟合效果;绿色是s_y,代表svm的拟合效果。
1.pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包
2.matplotlib是Python编程语言及其数值数学扩展NumPy的绘图 库 。 它提供了面向对象的 API ,用于使用通用的GUI工具包(如wxPython , Qt或GTK +)将图绘制到应用程序中。pyplot是matplotlib模块,提供了一个类似matlab的接口。
好了,今天的博客终于完成了,来张图片缓解一下cc紧张的神经吧,啦啦啦啦啦
