自己写内核——多任务调度
慕课18原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000 ”
很多人对于写程序都不陌生,但是大部分都是写一个应用程序或是驱动程序,这些程序都有意个特点,那就是以为自己“独占“了整个计算机或是单片机,但是实际上一个处理器可能“同时“运行着多个程序,那么计算机是如何同时处理多个任务却能让每个任务都以为计算机是在单独为其服务的呢?这就要说到操作系统内核的任务调度功能了!
接下来我们就通过一些简单的代码来看看,内核是怎样实现这一功能的!
一、问题分析
1、首先我们从整体上来了解一下其工作的原理。
计算机之所以看上去能够同时处理多个任务,是因为计算机快速的在多个任务处理中切换,也就是说假如有3个任务,计算机先运行任务1,运行了时间安长度T后去运行任务2,运行了时间T后去运行任务3,接着T时间长度后又运行任务一(不考虑任务的优先级问题),这样在3T的时间长度内,每个任务都运行了一次,当时间长度T足够小,比如说几毫秒、几微秒,小到不能察觉,就像频率足够大是的脉冲图像一样。这就有了3个任务同时运行的错觉。
2、了解了工作原理后,我们就有了几个需要解决的问题:
(1)、设定一个固定的时间长度,经过这个固定的时间计算机转向下一个任务。
(2)、完成任务的交接,保存当前任务的状态,以备下一次接着运行,并将接下来要运行的任务状态恢复到计算机中继续运行。
下面就一一解决这些问题!
二、程序实现
1、PCB.h

在PCB.h 文件中之定义了两个结构体,Thread和PCB,在Thread中定义了两个变量,分别用于在任务切换时保存任务的堆栈指针寄存器的值和指令指针寄存器的值,在PCB结构体中则定义了其他一些任务运行状态的变量,如进程的ID号、进程的堆栈空间、指向下一个任务的进程控制块的指针等。
2、设置一个系统定时器
linux中定时器的方案很多种,可以参看 http://blog.csdn.net/clp_csdnid/article/details/50800792
这里我们使用的一种方法是:函数setitimer,setitimer 在linux c编程中是一个比较常用的函数,可用来实现延时和定时的功能。
(在/usr/include/sys/time.h中,所以需要添加头文件
setitimer函数原型为:int setitimer(int which, const struct itimerval *new_value, struct itimerval *old_value);
其中which参数表示类型,可选的值有:
ITIMER_REAL:以系统真实的时间来计算,它送出SIGALRM信号。
ITIMER_VIRTUAL:以该进程在用户态下花费的时间来计算,它送出SIGVTALRM信号。
ITIMER_PROF:以该进程在用户态下和内核态下所费的时间来计算,它送出SIGPROF信号
紧接着的new_value和old_value均为itimerval结构体,先看一下itimerval结构体定义:
struct itimerval {
struct timeval it_interval; /* next value */
struct timeval it_value; /* current value */
};
struct timeval {
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
};
itimeval又是由两个timeval结构体组成,timeval包含tv_sec和tv_usec两部分,其中tv_se为秒,tv_usec为微秒(即1/1000000秒)
其中的new_value参数用来对计时器进行设置,it_interval为计时间隔,it_value为延时时长。
settimer工作机制是,先对it_value倒计时,当it_value为零时触发信号,然后重置为it_interval,继续对it_value倒计时,一直这样循环下去。
基于此机制,setitimer既可以用来延时执行,也可定时执行。
假如it_value为0是不会触发信号的,所以要能触发信号,it_value得大于0;如果it_interval为零,只会延时,不会定时(也就是说只会触发一次信号)。
old_value参数,通常用不上,设置为NULL,它是用来存储上一次setitimer调用时设置的new_value值。
下面看一下具体使用的代码:

说明一下,signal信号函数在signal.h头文件中,signal(参数1 ,参数2);参数一为我们要处理的信号,参数2 为我们的处理函数。
signal函数还有其他的使用方法,这里不作拓展,有兴趣的可以查看:http://www.360doc.com/content/12/0927/10/7534118_238403050.shtml
上面代码的意思很简单:做了四件事
(1)、定义了两个itimaerval结构体变量并进行初始化,初始化的数值含义为:1us的延时,之后每间隔200us 触发一次,也就是定时器运行1us后第一次发出SIGALRM信号,之后每200us发送一次信号。
(2)、定义了接收到信号后的处理函数signalHandler();
(3)、将信号SIGALRM与信号处理函数signalHandler()绑定;
(4)、设置/启动定时器
3、初始化任务控制块和任务控制链表
在这里任务控制链表是由一个个任务控制块连接成的一个循环链表,话不多说直接看代码:(main函数中)
在task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process中,my_process是任务处理函数的函数入口地址,在上面的代码中为了简单起见,只定义了一个任务处理函数,所有任务在运行的时候都执行相同的任务,但是是独立执行的。
4、下面是my_process的代码:

my_need_sched 是一个标志,等于1 表示该进程已经运行了200us,下面调度其他进程来运行。
my_scheuler()是调度函数,主要进行进程上下问的切换。(因为在这里我们并不考虑任务的优先级问题,而是按照任务就绪表进行顺序调度)
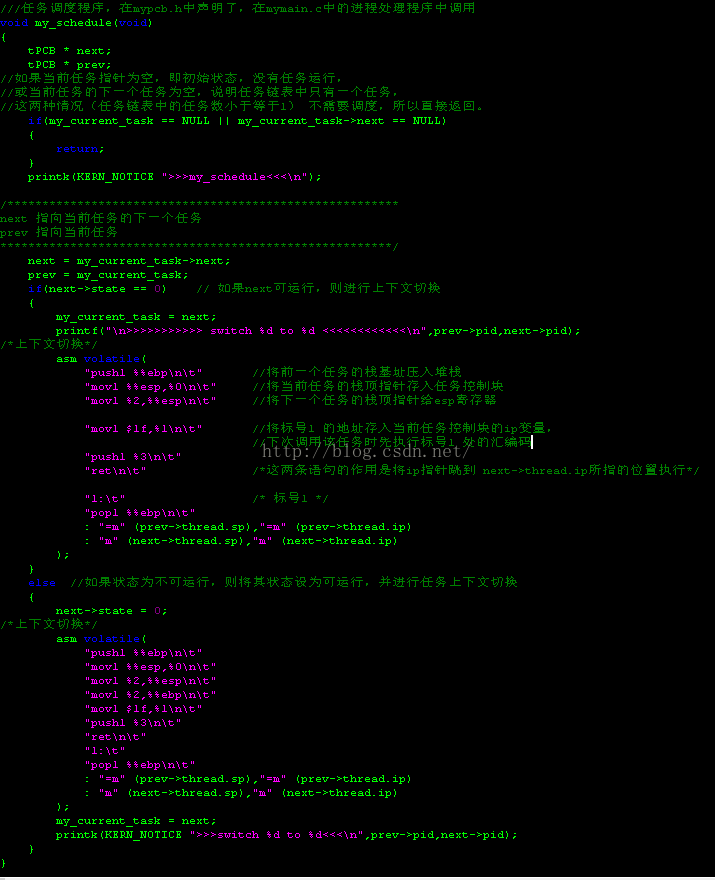
5、下面来看调度程序的代码:
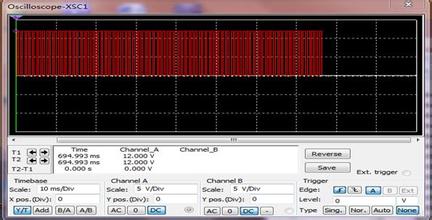
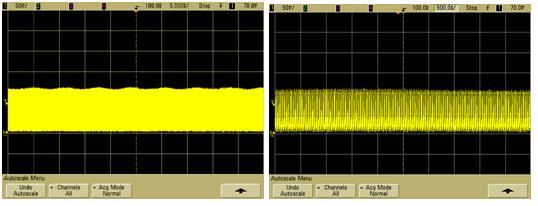
6、代码已经都看完了,下面看一下运行的效果:

从运行的结果可以看出,每个进程运行的是自己的处理程序,也就是说当从进程1切换到进程2时,进程2 是接着自己上一次的运行状态继续运行,而不是接着进程1 继续运行。
三、总结:
看完了原代码和运行结果,我们对内核的调度的理解更清晰了,下面我们就从计算机的角度再“运行”一遍程序:
先定义变量结构体并对其初始化、分配内存空间就不必多说了,我们从main函数中的那段汇编代码开始“走“,四个PCB都已经初始化完,开始运行进程0,下面就是跳转到进程 0 的process,先将进程0的堆栈的地址值送入esp寄存器并入栈保存,然后跳转到进程0的process去执行(因为process里面是一个死循环,所以不会在跳回来了)。进入process后,只要my_need_sched不等于1就不断的打印信息到终端,直到定时器设置的时间到了,发出一个SIGNALRM信号,signal()函数捕获信号后在signalHandler()中将my_need_sched置为1,表示进程已经运行了200us,该轮到下一个进程运行了,这时process发现my_need_sched被置为1,然后就将其置0,并进入调度程序,在调度程序中进行交接。
理论上交接的步骤为:先将进程0的堆栈指针寄存器的值、指令指针寄存器的值保存起来,然后将进程1的堆栈指针的值、指令指针寄存器的值(由于是第一次调度进程0,其ip所指的是process的入口地址)分别送入寄存器esp、eip,然后跳转到ip所指的地址去运行。这里要注意的是,每个进程第一次调度时,每个进程的ip都是指向process的入口处,所以跳转到ip处时都是重新运行一个process实例,所以调度四次过后,就有四个process在内存中了,每个进程都各有一个。但是当第5次调度时,也就是从进程3切换到进程0时,由于进程0中的Thread.ip,在第1次切换时保存的是第1次切换前,process0运行到的位置,所以这次切换后跳转到ip处是跳转到之前被打断的位置,而不是再加载一个process到内存运行,所以,依此下去就这样不停地在四个process中间切换,由于单个进程前后被调度的间隔很短(可以修改定时器的参数去观察),看上去就像四个进程在独立的同时运行一样!
这里我们用的方法有一点点区别,那就是切换的过程中在保存当前进程运行现场时,在Thread.ip中保存的是一个标号地址,而不是真正的进程被打断的地址,真正的被打断的地址处的现场在进入调度程序时已经由我们正在使用的操作系统自动保存进了当前进程的堆栈中,在退出调度程序时再从堆栈中恢复出来。所以如上面所说的,第5次调度都进程0先执行了标号出的代码,然后回到了调度程序中,紧接着退出调度程序。接下来就是根据堆栈中的数据恢复现场了,虽然ip保存的不是进程0被打断时的ip,但是Thread.esp保存的却是进程0之前的堆栈而不是进程3的堆栈,所以恢复的还是进程0 的现场,所以进程0任然接着之前被打断的位置继续执行。
虽然这里并不是完全按照内核的运行方式在走(毕竟不是在裸机上运行,而是基于计算机上已经装好的linux操作系统),但是深入的去分析过后会发现原理和效果还是一样的。