Spark(二): 内存管理
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块; Spark的内存可以大体归为两类:execution和storage,前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;在Spark 1.5和之前版本里,两者是静态配置的,不支持借用,spark1.6 对内存管理模块进行了优化,通过内存空间的融合,消除以上限制,提供更好的性能。官方网站只是要求内存在8GB之上即可(
Impala推荐要求机器配置在128GB
), 但spark job运行效率主要取决于:数据量大小,内存消耗,内核数(确定并发运行的task数量)
目录:
- 基础知识
- spark1.5- 内存管理
- spark1.6 内存管理
基本知识:
- on-heap memory:Java中分配的非空对象都是由Java虚拟机的垃圾收集器管理的,也称为堆内内存。虚拟机会定期对垃圾内存进行回收,在某些特定的时间点,它会进行一次彻底的回收(full gc)。彻底回收时,垃圾收集器会对所有分配的堆内内存进行完整的扫描,这意味着一个重要的事实——这样一次垃圾收集对Java应用造成的影响,跟堆的大小是成正比的。过大的堆会影响Java应用的性能
- off-heap memory:堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响
- LRU Cache(Least Recently Used):LRU可以说是一种算法,也可以算是一种原则,用来判断如何从Cache中清除对象,而LRU就是“近期最少使用”原则,当Cache溢出时,最近最少使用的对象将被从Cache中清除
- spark 源码: https://github.com/apache/spark/releases
- scale ide for Intellij : http://plugins.jetbrains.com/plugin/?id=1347
Spark1.5- 内存管理:
- 1.6 版本引入了新的内存管理方案,配置参数: spark.memory.useLegacyMode 默认 false 表示使用新方案,true 表示使用旧方案, SparkEnv.scala 源码 如下图:

- 在staticMemoryManager.scala 类中查看构造类及内存获取定义
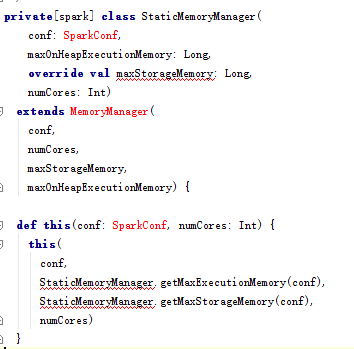

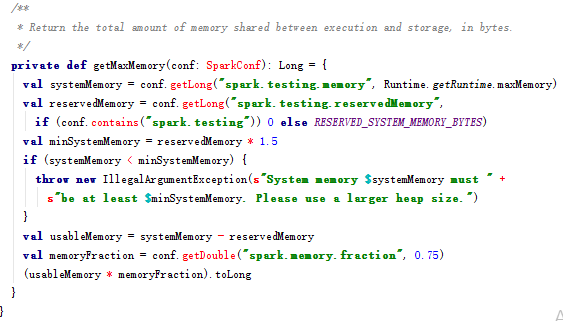
- 通过代码推断,若设置了 spark.testing.memory 则以该配置的值作为 systemMaxMemory,否则使用 JVM 最大内存作为 systemMaxMemory。
- spark.testing.memory 仅用于测试,一般不设置,所以这里我们认为 systemMaxMemory 的值就是 executor 的最大可用内存
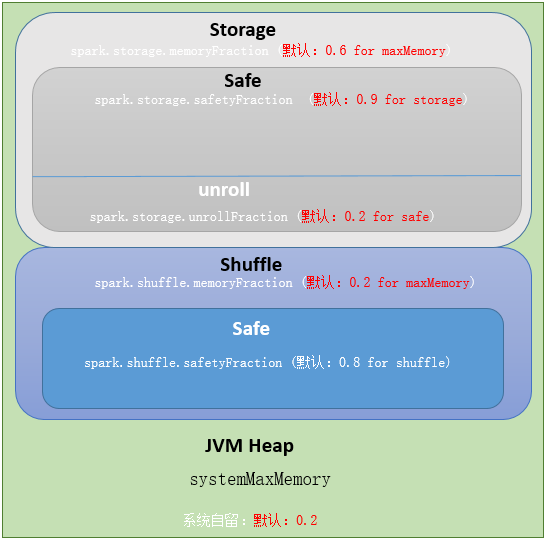
- Execution:用于缓存shuffle、join、sort和aggregation的临时数据,通过spark.shuffle.memoryFraction配置
- spark.shuffle.memoryFraction:shuffle 期间占 executor 运行时内存的百分比,用小数表示。在任何时候,用于 shuffle 的内存总 size 不得超过这个限制,超出部分会 spill 到磁盘。如果经常 spill,考虑调大参数值
- spark.shuffle.safetyFraction:为防止 OOM,不能把 systemMaxMemory * spark.shuffle.memoryFraction 全用了,需要有个安全百分比
- 最终用于 execution 的内存量为:executor 最大可用内存* spark.shuffle.memoryFraction*spark.shuffle.safetyFraction,默认为 executor 最大可用内存 * 0.16
- execution内存被分配给JVM里的多个task线程。
- task间的execution内存分配是动态的,如果没有其他tasks存在,Spark允许一个task占用所有可用execution内存
- storage内存分配分析过程与 Execution 一致,由上面的代码得出,用于storage 的内存量为: executor 最大可用内存 * spark.storage.memoryFraction * spark.storage.safetyFraction,默认为 executor 最大可用内存 * 0.54
- 在 storage 中,有一部分内存是给 unroll 使用的,unroll 即反序列化 block,该部分占比由 spark.storage.unrollFraction 控制,默认为0.2
- 通过代码分析,storage 和 execution 总共使用了 80% 的内存,剩余 20% 内存被系统保留了,用来存储运行中产生的对象,该类型内存不可控.
小结:
- 这种内存管理方式的缺陷,即 execution 和 storage 内存表态分配,即使在一方内存不够用而另一方内存空闲的情况下也不能共享,造成内存浪费,为解决这一问题,spark1.6 启用新的内存管理方案UnifiedMemoryManager
- staticMemoryManager- jvm 堆内存分配图如下
Spark1.6 内存管理:
从spark1.6开始,引入了新的内存管理方式-----统一内存管理(UnifiedMemoryManager),在统一内存管理下,spark一个executor中的jvm heap内存被划分成如下图:
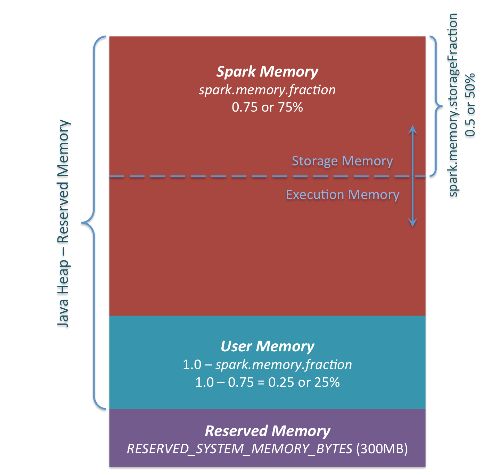
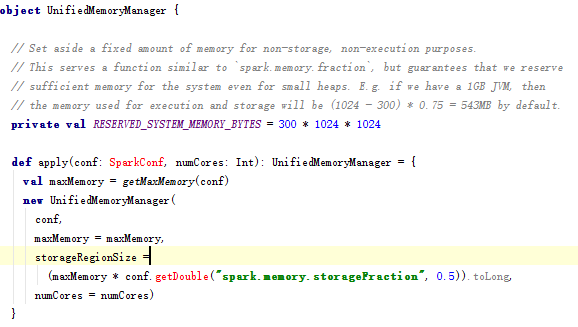
- Reserved Memory,这一部分的内存是我们无法使用的部分,spark内部保留内存,会存储一些spark的内部对象等内容。
- spark1.6默认的Reserved Memory大小是300MB。这部分大小是不允许我们使用者改变的。简单点说就是我们在为executor申请内存后,有300MB是我们无法使用的。并且如果我们申请的executor的大小小于1.5 * Reserved Memory 即 < 450MB,spark会报错:
- User Memory:用户在程序中创建的对象存储等一系列非spark管理的内存开销都占用这一部分内存
- Spark Memory:该部分大小为 (JVM Heap Size - Reserved Memory) * spark.memory.fraction,其中的spark.memory.fraction可以是我们配置的(默认0.75),如下图:
- 如果spark.memory.fraction配小了,我们的spark task在执行时产生数据时,包括我们在做cache时就很可能出现经常因为这部分内存不足的情况而产生spill到disk的情况,影响效率。采用官方推荐默认配置
- Spark Memory这一块有被分成了两个部分,Execution Memory 和 Storage Memory,这通过spark.memory.storageFraction来配置两块各占的大小(默认0.5,一边一半),如图:
- Storage Memory主要用来存储我们cache的数据和临时空间序列化时unroll的数据,以及broadcast变量cache级别存储的内容
- Execution Memory则是spark Task执行时使用的内存(比如shuffle时排序就需要大量的内存)
- 为了提高内存利用率,spark针对Storage Memory 和 Execution Memory有如下策略:
-
- 一方空闲,一方内存不足情况下,内存不足一方可以向空闲一方借用内存
- 只有Execution Memory可以强制拿回Storage Memory在Execution Memory空闲时,借用的Execution Memory的部分内存(如果因强制取回,而Storage Memory数据丢失,重新计算即可)
- 如果Storage Memory只能等待Execution Memory主动释放占用的Storage Memory空闲时的内存。(这里不强制取回,因为如果task执行,数据丢失就会导致task 失败)