杂项知识点 包含集合类 多线程p229
文章目录
- 1 方法的参数传递
- 2 抽象类和接口
- 4 集合类相关
- 4.1 ArrayList
- 4.2 LinkedList
- 4.3 HashSet
- 4.4 TreeSet
- 4.5 HashMap
- 5 Java多线程
- 5.1 同步和互斥
- 5.2 线程状态
- 进入就绪态的四种方式
- 进入阻塞态的四种方式
- 5.3 Runnable和Thread
- 5.4 synchronized
- synchronized方法(同步方法)
- synchronized块(同步块)
- 5.5 wait() notify()
- 生产者消费者示例(管程法,借助缓冲区)
- 5.6 volatile
- 5.7 单例模式
- 5.8 可重入锁
- 5.9 悲观锁 乐观锁
- 乐观锁的实现 **CAS比较并交换**
- 使用场景
- 6 ISO/OSI参考模型
- 7 三范式
- 8 系统变慢的可能原因
- 9 内连接和外连接
- 10 聚集索引,非聚集索引,创建索引考虑的因素
- 10.1 聚集索引
- 10.2 非聚集索引
- 10.3 创建索引考虑的因素
- 11 TCP连接管理
- 11.1 三次握手建立连接
- 11.1 四次握手释放连接
- 12 数据库 分表
- 13 数据库优化
- 13.1 创建并使用正确的索引
- 13.2 只返回需要的字段
- 13.3 减少交互次数
- 14 常见的三种缓存策略,缓存可能产生的错误
- 15 如何设计一个高并发系统?
- 15.1 系统拆分
- 15.2 缓存
- 15.3 消息队列MQ
- 15.4 分库分表
- 15.5 读写分离
- 15.6 ElasticSearch
- 16 在浏览器地址栏输入URL
- 16.1 域名到IP的转换
- 16.2 利用IP地址建立浏览器和服务器之间的TCP链接
- 16.3 浏览器通过HTTP协议发送请求
- 16.4 某些服务器会做永久重定向响应
- 16.5 浏览器跟踪重定向地址
- 16.6 服务器处理请求
- 16.7 释放TCP链接
- 16.8 浏览器显示页面
- 16 部分设计模式
- 16.1 观察者模式
1 方法的参数传递
实例:
class Test {
public static void main(String[] args) {
String str = "hello";
Integer num = 100;
int[] array = {1,2,3,4};
MyData myData = new MyData();
change(str, num, array, myData);
System.out.println(str);
System.out.println(num);
System.out.println(Arrays.toString(array));
System.out.println(myData.a);
}
public static void change(String str2, Integer num2, int[] array2, MyData myData2) {
str2 += " world";
num2 = 200;
array2[0] = 9;
myData2.a = 20;
}
}
class MyData {
int a = 10;
}
运行结果为:

分析:
- 形参是基本数据类型,则传递一个值的拷贝。本例未涉及
- 型参是引用数据类型:
传递地址值
String类、包装类等对象具有不可变性,一变化就会产生新的对象。
例如str存放的是指向常量池中hello字符串的地址0x1234,
此时形参str2中存放的也是0x1234(传递了地址值)
在执行str2 += " world";时,新建了一个hello world字符串,并修改str2的值,使之存放了这个新生成的字符串的地址0x1235
但是原来的hello字符串依然存在并且没有变化,str依然指向0x1234。
2 抽象类和接口

接口和抽象类都不能被实例化。
每个程序员都必须搞懂的抽象类和接口的含义以及区别
4 集合类相关
Java集合源码分析详解系列
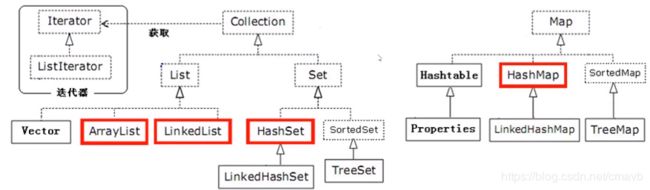
注意Map不属于Collection!
4.1 ArrayList
参考:
先看这个:Java集合源码分析(一)ArrayList
走进源码——ArrayList阅读笔记
size是数组中数据的实际个数。
手写简易ArrayList
public class MyArrayList {
// 整个集合中最关键的部分,用来保存数据
private Object[] elementData;
// 数组已经存放的元素的个数
private int size;
// 构造方法
public MyArrayList() {
elementData = new Object[10];
}
public void add(Object obj) {
// 要注意扩容的问题
if (size >= elementData.length) {
Object[] temp = new Object[(int) (elementData.length * 1.5)];
// 不能丢掉原先的数据
System.arraycopy(elementData, 0, temp, 0, size);
elementData = temp;
}
// 先把元素添加进去再给size增值
elementData[size++] = obj;
}
}
4.2 LinkedList
参考: Java集合源码分析(二)Linkedlist
基于双向链表。双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
非线程安全的(异步)。
能够当作队列来使用,LinkedList是双端队列的一种实现,所以,基于双端队列的操作在LinkedList中全部有效。
手写简易ArrayList
class MyLinkedList {
private Node first; // 链表的头结点
private Node last; //链表的尾节点
private int size; // 链表已经存放的元素的个数
public void add(Object obj) {
Node node = new Node();
if (first == null) { // 节点为空的情况
node.prev = null;
node.next = null;
node.obj = obj;
first = node;
last = node;
} else { // 节点不为空的情况
node.obj = obj;
node.prev = last;
last.next = node;
node.next =null;
last = node;
}
}
// 内部类
class Node {
Object obj;// 核心变量,保存当前节点的数据
Node prev;
Node next;
// 构造方法
public Node(Object obj, Node prev, Node next) {
this.obj = obj;
this.prev = prev;
this.next = next;
}
public Node() {
}
}
}
4.3 HashSet
可以添加一个null。不允许重复。
底层结构维护了一个HashMap对象,也就是和HashMap的底层一样,基于哈希表。
添加元素obj的去重原理
- 一个数组加链表存放数据(类似散列表中的拉链法)。
- 首先获取obj的哈希值,之后通过运算获取一个整数索引,代表数组下标。
如果该索引处没有元素,则直接添加。
如果有其他元素,则需要进行equals判断。不相等则以链表的形式追加到已有元素的后面;相等则直接覆盖,返回false。
4.4 TreeSet
不可以添加null。不允许重复。
底层结构维护了一个TreeMap对象,而TreeMap底层是红黑树结构。
可以实现两种排序:
- 自然排序:必须让添加元素的类型实现Comparable接口,实现里面的compareTo方法。
- 指定Comparator的定制排序:创建TreeSet对象时传入一个Comparator接口的对象,实现里面的compare方法。
去重原理:通过比较方法的返回值是否为0.
4.5 HashMap
允许null作为键值。
capacity是HashMap的桶的个数。
load factor是HashTable在增长(内部数据结构重构)之前,允许有多满。
底层结构是哈希表:jdk7是数组+链表,jdk8是数组+链表+红黑树。接下来的思路都属于jdk8
HashMap种维护了一个Node类型的数组table,当创建HashMap对象时,只是将loadFactor初始化为0.75,table保持为null。
第一次添加时,将初始table容量设为16,临界值`threshold`为12。
每次添加调用putVal方法:
1. 先获取key的二次哈希值并进行求与运算,得到了table的存放位置。
2. 判断该位置上是否有元素,如果没有则直接存放。如果有则继续判断:
2.1 如果和当前元素相等则直接覆盖
2.2 不相等则继续判断是链表结构还是树状结构,按照对应结构的判断方式来判断先等。
3. 将size++,如果超过threshold则需要resize()进行2倍扩容,并且打乱原来的顺序重新排列。
4. 当一个桶中节点数>=8 && 桶的总数>=64时,会将链表转为红黑树。
5 Java多线程
参考:Java 视频教程全集(376P) | 80 小时从入门到精通
线程是进程的内部的部分。进程看作一个容器

内存是逻辑内存。
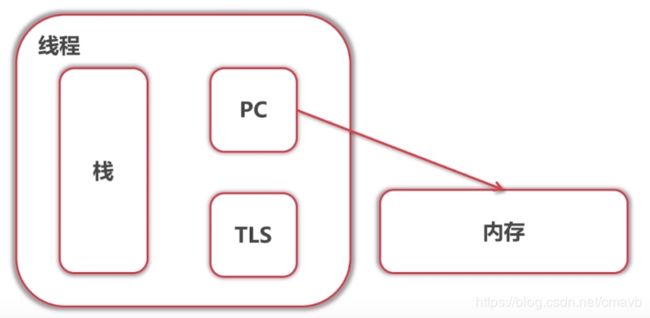
TLS是thread local storage,存放线程的独有数据。
5.1 同步和互斥
相交进程的关系主要有两种:同步和互斥。
同步: 散布在不同进程之间的若干程序片断,它们的运行必须严格按照规定的某种先后次序来运行,这种先后次序依赖于要完成的特定的任务。
互斥: 散布在不同进程之间的若干程序片断,当某个进程运行其中一个程序片段时,其它进程就不能运行它们之中的任一程序片段,只能等到该进程运行完这个程序片段后才可以运行。
同步是一种更为复杂的互斥,而互斥是一种特殊的同步。
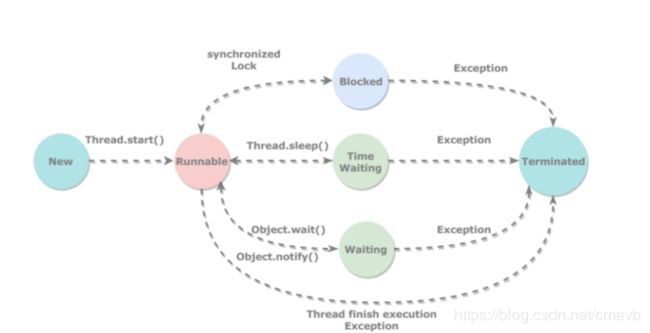
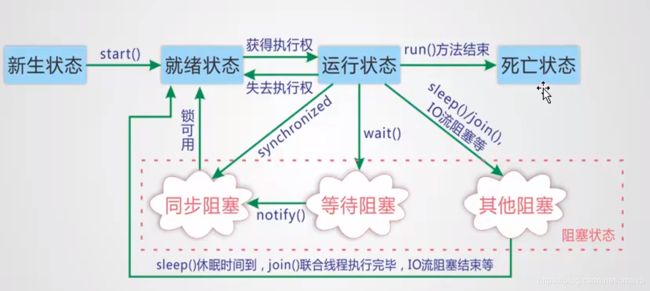
5.2 线程状态
-
新建(New)
创建后尚未启动。
Thread t = new Thread(); -
可运行(Runnable)
可能正在运行,也可能正在等待 CPU 时间片。
包含了操作系统线程状态中的Running 和 Ready。
就绪状态:调用start()方法就进入就绪状态,但不是立即执行。
运行状态:由CPU调度进入运行态。 -
阻塞(Blocked)
当调用sleep() wait() 或者同步锁定时。线程进入阻塞状态。阻塞事件结束后,重新进入就绪状态。 -
死亡(Terminated)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
进入就绪态的四种方式
- start方法
- 解除阻塞
- yield方法(注意sleep是进入了阻塞状态)
- jvm调度
进入阻塞态的四种方式
- sleep方法(注意yield是进入了就绪状态)
- wait
- join:在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。让目标线程来“插自己的队”。
- 一些操作。例如IO read write
5.3 Runnable和Thread
实现接口 VS 继承 Thread
实现接口会更好一些,因为:
- Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
- 类可能只要求可执行就行,继承整个 Thread 类开销过大。
5.4 synchronized
并发:同一个对象被多个线程 同时操作。
当一个线程获得对象的排他锁,独占资源,其他线程必须等待。
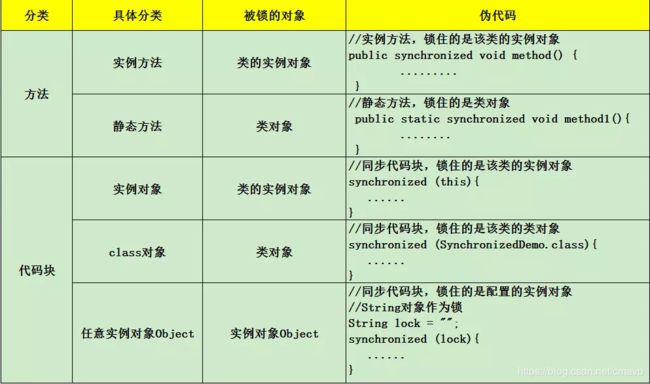
synchronized方法(同步方法)
synchronized块(同步块)
synchronized (obj){}
obj称为同步监视器。- obj可以是任何对象,但是推荐使用共享资源作为同步监视器。
- 同步方法中无需指定同步监视器,因为同步方法的同步监视器是this即该对象本身,或者Class对象。
使用synchronized不当容易引起死锁。
5.5 wait() notify()
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
- 它们都属于 Object 的一部分,而不属于 Thread。
- 只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateException。
- 使用
wait()挂起期间,线程会释放锁(sleep()不会释放锁)。这是因为如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
生产者消费者示例(管程法,借助缓冲区)
class TestConsumerProductor {
public static void main(String[] args) {
SynContainer synContainer = new SynContainer();
new Productor(synContainer).start();
new Consumer(synContainer).start();
}
}
// 生产者
class Productor extends Thread {
SynContainer container;
public Productor(SynContainer synContainer) {
this.container = synContainer;
}
public void run() {
// 假设生产10个
for (int i = 0; i < 10; i++) {
System.out.println("produce No." + i + "production");
container.push(new Production(i));
}
}
}
// 消费者
class Consumer extends Thread {
SynContainer container;
public Consumer(SynContainer synContainer) {
this.container = synContainer;
}
public void run() {
// 假设消费20个
for (int i = 0; i < 20; i++) {
// 注意此时程序不能自己停止。因为生产者生产完10个以后已经停止了,消费者还在阻塞等待
System.out.println("consume No." + container.pop().id + "production");
}
}
}
// 缓冲区
class SynContainer extends Thread {
// 只能存放5个产品
Production[] productions = new Production[5];
int count = 0; // 指向最后一个产品的下一个位置
// 存 操作
public synchronized void push(Production p) {
if (count == productions.length) {
try {
this.wait();// 线程阻塞,消费者通知则解除阻塞
} catch (InterruptedException e) {
e.printStackTrace();
}
}
productions[count] = p;
count++;
this.notifyAll();
}
// 取 操作
public synchronized Production pop() {
if (count == 0) {
try {
this.wait();// 线程阻塞,生产者通知则解除阻塞
} catch (InterruptedException e) {
e.printStackTrace();
}
}
count--;
this.notifyAll();
return productions[count];
}
}
// 产品
class Production {
int id;
public Production(int id) {
this.id = id;
}
}
5.6 volatile
1分钟读懂java中的volatile关键字
volatile 修饰的变量就是通知系统这个变量不稳定,随时会被其他线程所修改。
使用volatile修饰的变量会强制将修改的值立即写入主存,主存中值的更新会使缓存(每个线程的工作空间)中的值失效(非volatile变量不具备这样的特性,非volatile变量的值会被缓存,线程A更新了这个值,线程B读取这个变量的值时可能读到的并不是是线程A更新后的值)。
volatile会禁止指令重排。
volatile具有可见性、有序性,不具备原子性。
5.7 单例模式
双重检验锁(DCL double checked locking)
class Singleton {
// 懒汉式,此时的 volatile是为了禁止指令重拍
private static volatile Singleton instance;
private Singleton() {
}
public Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
5.8 可重入锁
当线程请求一个由其它线程持有的对象锁时,该线程会阻塞,而当线程请求由自己持有的对象锁时,如果该锁是重入锁,请求就会成功,否则阻塞。
synchronized就是一种可重用锁。
测试是不是可重入锁:
class TestReentrantLock {
public void test() {
// 第一次获取锁
synchronized (this) {
System.out.println("第一次取得了锁!");
synchronized (this) {
System.out.println("第二次取得锁,这是ReentrantLock!");
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new TestReentrantLock().test();
}
}
可重入锁的实现原理:
每一个锁关联一个线程持有者和计数器,当计数器为 0 时表示该锁没有被任何线程持有,那么任何线程都可能获得该锁而调用相应的方法;当某一线程请求成功后,JVM会记下锁的持有线程,并且将计数器置为 1;此时其它线程请求该锁,则必须等待;而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增;当线程退出同步代码块时,计数器会递减,如果计数器为 0,则释放该锁。
5.9 悲观锁 乐观锁
- 悲观锁:每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁。synchronized是独占锁即悲观锁,会导致其他所有需要锁的线程挂起,等待持有锁的线程释放锁。
- 乐观锁:每次获取数据时,并不会加锁。只在更新数据的时候判断该数据是不是被其他人修改过。如果被其他线程修改则不进行数据的更新。由于不及所,所以其他线程也可以进行读写操作。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。一般使用version方式和CAS方式。
乐观锁的实现 CAS比较并交换
- 有三个值:当前的内存值
V,原来的值A,将要更新的值B。 - 首先线程从内存V中读取值A,当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则返回V。这是一种乐观锁的思路,它相信在它修改V之前,没有其他线程会去修改V值;而Synchronized是一种悲观锁,它认为在它修改V之前,一定会有其它线程去修改V,悲观锁效率很低。
- CAS是一组原子操作,不会被外界打断,属于硬件级别的操作。
使用场景
- 乐观锁的使用场景:适合大量读取。如果大量写入的话,冲突的可能性大。为了数据一致,需要不断查询新的数据,占用了吞吐量。
- 悲观锁的使用场景:写入频繁。如果读取频繁会造成浪费。
6 ISO/OSI参考模型
- 物理层:传输单位是比特,任务是透明的传输数据。
- 数据链路层:传输单位是帧,任务是将网络层传下来的IP数据报封装成帧。功能概括为成帧、差错控制、流量控制等。(注意没有拥塞控制)。
- 网络层:传输单位是数据报,关心的是通信子网的运行控制。功能概括为差错控制、流量控制、拥塞控制等。
- 运输层:传输单位是TCP报文段或者用户数据报(UDP)。负责主机中两个进程的通信。
- 会话层:向表示层实体提供建立连接并在连接上有序地传输数据。负责管理主机间的会话进程,包括建立、管理以及终止会话。
- 表示层:处理两个通信系统中交换数据的表示方式。
- 应用层:用户和网络的界面,最为复杂。
物理层、数据链路层和网络层统称为通信子网,它是为了联网而加上去的通信设备。
运输层承上启下。
会话层、表示层和应用层统称为资源子网,相当于计算机系统,完成数据的处理。
7 三范式
- 第一范式:属性值不可再分。例如电话应该被分为手机和座机。
- 第二范式:每个非主属性 应该完全依赖于R的每一个候选关键属性,而不是部份依赖。例如选课成绩表(学号,课程号,成绩,姓名)中,关键字为组合关键字(学号,课程号),但是姓名仅仅依赖于学号,所以冗余,需要拆解。
- 第三范式:非主属性 不传递依赖于R的每一个候选关键属性。例如选课成绩表(学号,课程号,成绩,姓名)中,此时假设姓名不会重复。该表有两个候选码:(学号,课程号)和(姓名,课程号)。存在依赖:
学号->姓名,(学号,课程号)->成绩,(姓名,课程号)->成绩,唯一的非主属性成绩不存在部份依赖,也不存在传递依赖,所以属于第三范式。
8 系统变慢的可能原因
- 数据库原因
数据库的表设计复杂,需要的关联查询较多。随着数据量的增大这个问题越来越凸显。
数据库有的表被死锁。
索引不够全,可能有很多查询的条件为不存在索引的属性。 - 服务器
配置低。
受到攻击,比如DDos - 其他
许多资源没有及时的释放,重启服务器。没有及时关闭已打开并提交过的记录集对象和连接对象
垃圾文件太多。
9 内连接和外连接
- 内链接也被称为自然连接,两个表中只有符合条件的行才能放入结果集。
- 左外连接是在自然连接的基础上,再检查左表的值是不是都出现在结果集之中了,如果没有,则将未出现的该行放入结果集,再将对应右表对应的部分设置为null。
10 聚集索引,非聚集索引,创建索引考虑的因素
10.1 聚集索引
数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。
叶子节点存的是整行数据,直接通过这个聚集索引的键值找到某行
10.2 非聚集索引
数据行的物理顺序与索引的逻辑顺序不同的逻辑顺序不同,一个表中可以拥有多个非聚集索引。
叶子节点存的是字段的值,通过这个非聚集索引的键值找到对应的聚集索引字段的值,再通过聚集索引键值找到表的某行,类似oracle通过键值找到rowid,再通过rowid找到行。
10.3 创建索引考虑的因素
- 考虑在WHERE和ORDER BY命令上涉及的列建立索引
- 值分布很稀少的字段不适合建索引,例如“性别”这种只有两三个值的字段;
- 不要建立太多索引
- 频繁进行数据操作的表,不要建立太多的索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引
11 TCP连接管理
11.1 三次握手建立连接
- 客户机的TCP向服务器的TCP发送一个连接请求报文,不含应用层数据。SYN=1,seq=x。
- 服务器的TCP收到连接请求报文段后,发回确认,并为该连接设置TCP缓存和变量。不含应用层数据。SYN=1,ACK=1,seq=y,ack=x+1。
- 客户机向服务器发出确认,同时为连接分配缓存和变量。SYN=0,ACK=1,seq=x+1,ack=y+1。可以携带数据。
- 由于服务器的资源是在第二次握手时分配的,而客户端的资源是在第三次握手时分配,使得服务器容易受到SYN洪泛攻击。
- 为什么三次?
防止已经失效的连接请求报文段到达服务器。例如此时采取二次握手,客户端A向服务器B发送了第一次请求报文,但是在某个中间节点长时间滞留。A超时后重发第二次请求报文,B收到后发送给A确认,此时连接就建立了。等数据传输完之后,连接断开。此时失效的第一次请求报文到达B,B就会直接建立连接,浪费资源。
11.1 四次握手释放连接
- 客户机的TCP向服务器的TCP发送一个连接释放报文,并停止发送数据,主动关闭TCP连接。FIN=1,seq=u。(TCP是全双工的)
- 服务器的TCP收到连接释放报文段后,发回确认,此时TCP处于半关闭,如果服务器还需要发送数据,那么客户端还是得接收。ACK=1,seq=v,ack=u+1。
- 如果服务器没有可发送的数据了,就向客户端发出连接释放报文段。FIN=1。
- 客户机向服务器发出确认,且等待
2MSL(最长报文段寿命)后,A才进入连接关闭状态。
- 为什么四次,且等待2MSL?
- 两个原因
- 保证A的最后确认报文段可以到达B,如果最后的确认报文段丢失了,那么B无法正常关闭连接,就要向A重发释放连接报文段。
- 防止出现已经失效的连接请求报文。情形同“三次握手建立连接“一样。
12 数据库 分表
当一个表的数据不断增多时,切分是必然选择,因为数据量太大查询效果会很差,维护索引也会变得困难。将数据分散到集群中的不同节点上,从而缓存单个数据库的压力。
- 垂直拆分:将有很多字段的表拆分为多个表,每个表的结构不一样且包含原表的部分字段。将访问频率搞得放到一个表中,低的放到另外一个表里去。
- 水平拆分:把一个表的数据拆分到多个库的多个表里去,但是每个新表的结构都是一样的。每个新表的数据量加起来就是原表的数据量。
13 数据库优化
数据库性能优化(一)
13.1 创建并使用正确的索引
见10.3 创建索引考虑的因素
- 考虑在WHERE和ORDER BY命令上涉及的列建立索引
- 值分布很稀少的字段不适合建索引,例如“性别”这种只有两三个值的字段;
- 不要建立太多索引
- 频繁进行数据操作的表,不要建立太多的索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引
13.2 只返回需要的字段
- 减少数据在网络上的传输开销
- 减少服务器处理数据开销
- 减少内存占用
13.3 减少交互次数
采用批处理,比如每一千条数据提交一次。
14 常见的三种缓存策略,缓存可能产生的错误
- FIFO First In First out 先进先出
- 新访问的数据插入FIFO队列尾部,数据在FIFO队列中顺序移动;
- 淘汰FIFO队列头部的数据;
- LRU Least recently used 最近最少使用
核心思想“如果数据最近被访问过,那么将来被访问的几率也更高”。
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
- LFU Least frequently used 最近使用次数最少
核心思想“如果数据过去被访问多次,那么将来被访问的频率也更高”。
- 新加入数据插入到队列尾部(因为引用计数为1);
- 队列中的数据被访问后,引用计数增加,队列重新排序;
- 当需要淘汰数据时,将已经排序的列表最后的数据块删除。
可能的错误:
缓存与数据库双存储双写导致的数据一致性。
Cache Aside Pattern:
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
15 如何设计一个高并发系统?
参考:如何设计一个高并发系统?
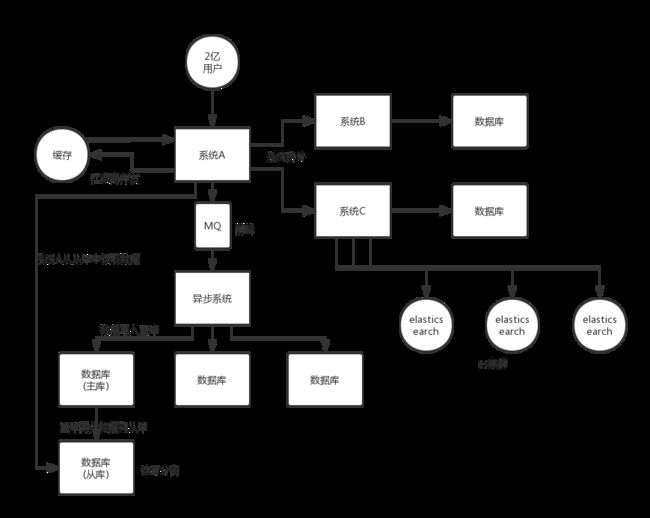
15.1 系统拆分
将一个系统拆分为多个子系统,之后每个系统连接一个数据库。
之所以拆分系统,是为了降低耦合性,将具有不同功能的服务分别部署到不同的服务器上。
15.2 缓存
大多数的高并发场景都是读多写少,在数据库和缓存里都写一份,高并发读的时候去读取缓存。
15.3 消息队列MQ
应对高并发写的情况,大量的写请求灌入 MQ ,后边系统消费后慢慢写。
存放消息的容器,需要使用消息的时候就取出消息,是分布式系统中的重要的组件。通过异步处理提高下性能,降低耦合性。
15.4 分库分表
可能到了最后数据库层面还是免不了抗高并发的要求,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 sql 跑的性能。
15.5 读写分离
主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
15.6 ElasticSearch
16 在浏览器地址栏输入URL
参考: 在浏览器地址栏输入URL,按下回车后究竟发生了什么?
16.1 域名到IP的转换
- 首先查找浏览器的缓存
- 查找系统的缓存,host文件
- 如果还没有找到,那么使用域名解析协议。网络服务提供商的DNS服务器会进行递归查询或者迭代查询来查找IP。
16.2 利用IP地址建立浏览器和服务器之间的TCP链接
三次握手。见第11节。
16.3 浏览器通过HTTP协议发送请求
浏览器向主机发起一个HTTP-GET方法报文请求。请求中包含访问的URL,KeepAlive,长连接,还有User-Agent等。
16.4 某些服务器会做永久重定向响应
对于大型网站存在多个主机站点,为了了负载均衡或者导入流量,提高SEO排名,往往不会直接返回请求页面,而是重定向。返回的状态码就不是200OK,而是301,302以3开头的重定向码,浏览器在获取了重定向响应后,在响应报文中Location项找到重定向地址,浏览器重新第一步域名解析或者建立TCP链接,再访问即可。
16.5 浏览器跟踪重定向地址
当浏览器知道了重定向后最终的访问地址之后,重新发送一个http请求,发送内容同上。
16.6 服务器处理请求
服务器接收到获取请求,然后处理并返回一个响应。返回状态码200 OK,表示服务器可以响应请求。
16.7 释放TCP链接
四次握手。见第11节。
16.8 浏览器显示页面
尚没有完整接受完全部文件内容时便开始渲染。但有一些图片、js文件等的url,还可能需要利用这些url重新发送请求,走一个完整的流程。
16 部分设计模式
16.1 观察者模式
【设计模式】最常用的设计模式之一的观察者模式
定义对象之间的一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于该对象的对象都会得到通知并且自动更新。
- Subject:被观察的角色。将所有的观察者的引用保存到一个集合之中。
- Observer:抽象的“观察者”,定义了一个更新接口,使用被观察者的状态改变时通知自己。
- ConcreteObserver:具体的观察者。