java复习宝典,jdbc与mysql数据库
一.java
1.面向对象知识
(1)类和对象
类:若干具有相同属性和行为的对象的群体或者抽象,类是创建对象的模板,由属性和行为两部分组成。
类是对象的概括或者抽象,对象是类的实例化。
举例:例如车有很多类型,但是这些都是车,车这个大类就是一个类,每种车都是一个对象。
1.类的声明
[修饰符] class 类名{//类的声明部分 [成员变量] [成员方法] }
员变量的声明: [修饰符] 数据类型 变量名 [= 初始值];
成员方法的声明:
[修饰符] 返回值类型 方法名([数据类型 参数名,……]){
//方法体,该方法完成的功能代码
}
2.什么是构造器
类中的构造器也叫构造方法,在进行创建对象的时候必须进行调用。并且每一个类中都隐藏一个无参构造。
格式:public 类名称(形参 实参){
方法体
}
构造器:
1.和类名必须相同
2.没有返回值
作用:
1.new的本质就是在调用构造方法
2.初始化对象的值
注意点:定义有参构造之后,如果还想用无参构造的话,那么就必须显示的定义一个无参构造
3.构造器的声明:
[修饰符] 构造器名([数据类型 参数名,……]){
//构造器完成的功能代码
}
注意:
①构造器名必须和类名一致
②构造器没有返回值类型
③任何类都含有构造器。如果没有显式地定义类的构造器,
④则系统会为该类提供一个默认的无参的构造器。一旦在类中显式地定义了构造器,系统就不会再为这个类提供默认的构造器了。
4.类的使用
类变量的声明:类名 对象名;
类对象的创建,赋值给变量:对象名 = new 构造器([参数列表])
成员变量与局部变量:
成员变量:声明在类中方法体之外、可以有缺省值、可以使用修饰符。作用域:整个类
局部变量:声明在方法体或代码块中、没有缺省值、只能使用final修饰。作用域:当前方法体
参数:参数的本质是特殊的局部变量,只能定义在方法的小括号中
5.重载
方法的重载OverLoading: 同一个类中定义了多个方法名相同而参数不同的方法
重载在同一个类中,方法名相同,参数不同(参数的个数、顺序、类型不同)
方法的返回值类型:
(1)无返回值类型:void,return;//结束方法体
(2)有返回值类型为:数据类型(基本数据类型、引用数据类型),return 数据;//结束方法体,并且返回一条数据
6.方法重写
特点:
1.方法名必须相同。
2.参数列表必须相同。
3.修饰符范围可以扩大。
4.抛出的异常:可以被缩小但是不能扩大。
子类的方法和父类必须要一致,方法体不同。
为什么需要重写?
父类的功能:子类可能不一定需要,或者是不一定满足。
7.static关键字
1.static静态变量在类中是共享的。
2.非静态方法可以访问本类中的所有静态方法。
3.静态方法可以调用本类中所有的静态方法。
原因:因为静态的方法是随着类的加载一起加载出来的,加载之前还没有普通的方法,所以就无法调用。
8.this关键字
this关键字:
this是一种特殊的引用,指向当前对象
9.super关键字
super代表的是父类对象,
使用方式:
super.属性名、super.方法名();用于在子类中调用父类被隐藏的同名实例变量
super([参数列表])用于在子类的构造方法中调用父类的构造方法
每一个子类的构造方法在没有显示调用super()系统都会提供一个默认的super(),super()必须是构造器的第一条语句
10.final关键字
final 关键字,意思是最终的、不可修改的,最见不得变化 ,用来修饰类、方法和变量,具有以下特点:
修饰类:类不能继承,final 类中的所有成员方法都会被隐式的指定为 final 方法;
修饰符变量:该变量为常量,,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能让其指向另一个对象。
修饰符方法:方法不能重写
二.java的三大特征
1.封装
定义:将一些较为复杂的内部结构进行隐藏,大部分程序的细节都应该藏起来。
一旦使用了private进行修饰,本类当中可以随意访问,但是超出了本类就不可以访问了。
封装的意义:
1.提高程序的安全性,保护数据。
2.隐藏代码
3.统一接口。
4.提高了系统的可维护性
2、继承
对象用来封装数据和功能,但我们要创建一个新类,然而它又与已存在的类具有部分相同的属性或功能,如动物是所有其他动物的子类,其他动物是该类的子类,例如动物和狗,可以使用继承来实现。
3、多态
通过将子类对象引用赋给父类对象引用来实现动态方法调用。
三.抽象类
抽象类定义;在普通类的结构里面增加抽象方法的组成部分。
抽象方法定义:是指没有方法体的方法。
关键字为:abstract。
注意:
1.不能new这个抽象类,只能靠它的子类进行实现。
2.抽象类中可以写普通的方法。
3.抽象方法必须在抽象类中。
抽象类的声明: [修饰符] abstract class 类名 [extends 父类名]{类体}
抽象方法的声明: [修饰符] abstract 返回值类型 方法名([参数列表]);
四.接口
在Java中接口不仅仅是程序开发过程中“约定”,更是更加抽象化的抽象类。
接口的声明语法: [修饰符] interface 接口名{[常量];[抽象方法];}
接口实现的语法: [修饰符] class 类名 [extends 父类名] [implements 接口1,接口2,……]{类体部分}
接口的作用:
- 提高程序的重用性
- 提高程序的可扩展性
- 降低程序的耦合度
- 实现了多继承
五.异常
异常英文(Exception),意思是例外,这些例外情况需要我们写程序做出合理的处理,而不至于让程序崩溃。
异常指程序运行中出现的不期而至的各种状况:文件找不到,网络连接错误,非法参数等。
异常发生在程序运行期间,它影响了正常的执行流程。
分类:检查时异常;运行时异常;错误。
检查时异常:检查时异常最具有代表性的就是用户错误或者是问题引起的异常,这种异常是我们程序员无法进行预测的。例如我们要打开一个文件时文件不见了,这些异常都是在编译时不能被简单的忽略的。
运行时异常:运行时异常是可能被程序员避免的异常,与检查时异常相反,运行时异常可以在编译时被忽略。
Error 错误:错误不是异常,而是不被程序员控制的问题,错误在代码中通常被忽略。例如当栈溢出时,错误就产生了,并且在程序编译的时候也无法被找到。
异常的体系结构:
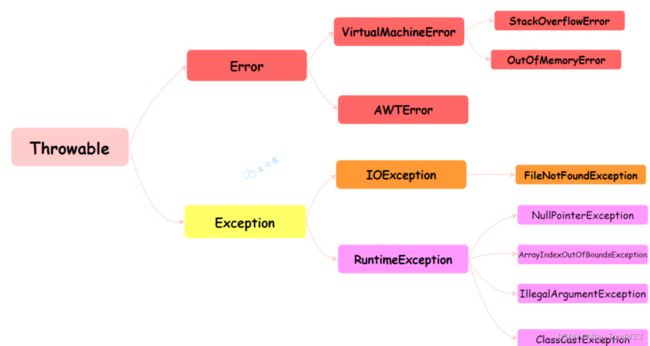
1.抛出以及捕获异常
关键字:try、catch、final、throw、throws。
try:抛出异常(尝试着去处理什么东西)。
catch:捕获异常。
final:无论有什么异常发生,finally都会被执行(可以运行清理类型等收尾善后性质的语句)。
throw:当程序发生异常而无法处理的时候,会抛出对应的异常对象。
throws:throws用来在类中捕获异常信息,标明方法可能抛出的异常。
2.自定义异常
定义:使用Java内置的异常类可以描述在编程时出现的大部分异常情况。除此之外,用户还可以自定义异常,用户自定义异常类,只需要继承Exception类即可。
在程序中使用自定义异常类,大体可以分为以下步骤。
1.创建自定义常类。
2.在方法中通过throw关键字抛出异常。
3.如果在当前抛出异常的方法中处理异常,可以使用try——catch语句来捕获异常并处理,否则在方法的声明处通过throws关键字指明要抛出给方法调用的异常,继续下一步操作。
4.在出现异常方法的调用者中捕获并处理异常。
二.jdbc
1.JDBC(java DataBase Connectivity)
java语言连接数据库。
2.JDBC的本质:
JDBC是一套接口(面向接口写实现类,能够解耦合,提高代码的扩展力,因为每个数据库底层的实现原理是不同的,如果没有接口 访问不同数据库就要不同的代码。
jdbc驱动: 所有的数据库连接的驱动都以 jar包存在(里面是.class) ,有很多的 .class文件他们是对JDBC接口的实现类 由数据库厂商提供连接相应的数据库 官网下载 。
3.为什么要使用JDBC
有了JDBC,java开发人员只需要编写一次程序,就可以访问不同的数据库.
J a v a A P I 中 提 供 了 操 作 数 据 库 的 标 准 接 口 , 最 终 由 不 同 的 数 据 库 开 发 商 实 现 这 些 标 准 接 口 来 对 数 据 库 操 作 . Java定义者制定了JDBC规范,数据库开发商实现接口, 程序员。
二.连接步骤
1.在项目添加jar文件
2.加载驱动类 Class.forName("com.mysql.cj.jdbc.Driver");
3.建立与数据库的连接,获得连接对象
String url = "jdbc:mysql://127.0.0.1:3306/schooldb?serverTimezone=Asia/Shanghai";
String user = "root";
String password = "root";
Connection connection = DriverManager.getConnection(url,user,password);
4.发送sql
Statement st = connection.createStatement();
st.executeUpdate("INSERT INTO student(NAME,num,gender,birthday,phone,address,reg_time,majorid)" +
"VALUES('"+name+"','"+gender+"','"+birthday+"','"+phone+"','"+address+"',now(),"+majorid+")");
PreparedStatement ps = connection.prepareStatement("delete from student where num=?");
ps.setObject(1,num);
ps.executeUpdate();
三.mysql数据库
(1)什么是数据库?数据库使用来干什么的?
例如:学校的高校图书管理:图书馆有包含图书信息的数据库,该数据库拥有借阅者信息,图书信息,借书信息等,通过该数据库图书管理员可以查找借阅者的信息,借阅者可以查询借阅图书的信息等,还有公司员工数据库等。数据库(DBMS)是为了方便数据的存储和管理,它将数据按照特定的 规则存储在磁盘上,就是一个存储数据的仓库。简单来说数据库就是用来存储信息的仓库,但是存储的信息不是乱存,而是通过建立关系表,通过各关系表来存储信息,删除信息,查找信息等。
(2)关系.属性.元组.主码
关系:关系简单来说就是一个表,例如:高校图书管理中的读者表,
属性:属性就是关系表中每一列,如:高校图书管理中读者表中的读者卡号,姓名,性别,单位,办卡日期等。
元组:元组就是关系表中的每一行数据,如:高校图书管理中读者表中的一组数据,(2100001,李丽,女,数计学院,2021-03-06)
主码:主码就是在关系表中属性或属性组可以唯一表示一个元组,而其子集不能,则称该属性或者属性组为一个主码,如高校图书管理中读者表中的读者卡号。
(3)数据库相关语句
1、创建数据库
CREATE DATABASE db_name DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
2、查询数据库
SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)
SELECT * FROM 表名称;
SELECT 列名称 FROM 表名称;3、删除数据库
DROP DATABASE db_name;
4、修改数据库
-- 修改数据库的字符编码和排序方式
ALTER DATABASE db_name DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
5、选择数据库
USE db_name;
6、删除表数据
delete语法
delete from 表名 where 删除的条件7.distinct去重
作用 : 去掉SELECT查询返回的记录结果中重复的记录,只返回一条所有列的值都相同数据
select distinct user_id,user_name from tb_user; 8、where条件查询
作用:用于检索数据表中 符合条件 的记录
搜索条件可由一个或多个逻辑表达式组成 , 结果一般为真或假.
LIKE模糊查询-通配符
%(百分号)匹配零个或者多个任意字符
_(下划线)匹配一个任意字符
-- 模糊匹配 【like "_"占位,"%"代表通配符】
select * from t_user where user_name like 'han%';
select * from t_user where user_name like '_han%';
select * from t_user where user_name like '%hanmei%';
IN字段指定多个值查询
select * from t_user where user_id in (5,6,9);
-- 查询结果等价于下面的结果集
select * from t_user where user_id = 5 UNION ALL
select * from t_user where user_id = 6 UNION ALL
select * from t_user where user_id = 9
BETWEEN AND 区间查询
-- between and 查询
select * from t_user where user_id between 6 and 9;
select * from t_user where user_id >=6 and user_id <=9;
IN子查询
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
select * from t_user where user_id in
(select user_id from t_user where user_id where user_id>9)
group by 分组查询
配合函数count(field)获取符合条件出现的非null值的次数
sum(field)获取所有符合条件的数据的总和
avg(field)或者平均值
-- 统计所有用户信息中男女的平均身高
-- 使用group by注意在查询中出现字段必须是group by后面字段
select user_gender as 性别,avg(user_height) 平均身高,sum(user_height) 总身高,count(user_gender) 总数 from t_user group by user_gender;
having 分组之后的条件,一般和group by联合使用
select user_gender,count(*) as 性别统计 from t_user group by user_gender having 性别统计>1;
10、order by排序查询
ORDER BY field DESC;降序查询
ORDER BY field ASC;升序查询(默认的排序)可以省略不写
select * from t_user order by user_id asc;
select * from t_user order by user_id desc;
-- order by 放置在group by的后面
select user_gender as 性别,avg(user_height) 平均身高,sum(user_height) 总身高,count(user_gender) 总数 from t_user group by user_gender order by 总身高 desc;
11、limit分页选择语句
LIMIT 后边可以跟两个参数,如果只写一个表示从零开始查询指定长度,如果两个参数就是从第一个参数开始查询查询长度是第二个参数的值,俩个参数必须是整形。
外键:
(1)外键概念
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。
在实际操作中,将一个表的值放入第二个表来表示关联,所使用的值是第一个表的主键值(在必要时可包括复合主键值)。此时,第二个表中保存这些值的属性称为外键(foreign key)。
外键作用
保持数据一致性,完整性,主要目的是控制存储在外键表中的数据,约束。 使两张表形成关联,外键只能引用外表中的列的值或使用空值。
(2)创建外键
建表时指定外键约束
(4)连接查询
JOIN 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
