Hibernate 刷新上下文
Spring Boot 版本 2.0.3.RELEASE
刷新上下文目的
当需要进行数据同步时,需要不仅往自己项目数据库(A)更新数据,还需要对外部数据源(B)进行更新。如果B不能进行回滚就GG。所以只能先写A,再写B,B成功A提交,B失败A回滚。
但是有个问题如果代码写在一个Service方法(同一次事务)中因为hibernate存在缓存导致save(entity)会导致在B执行完成之后才会执行A的数据库交互,导致有个问题如果B执行成功但是因为违反了A的数据库约束导致A因为异常回滚了,但是B数据已经更新,导致存在数据不一致的风险隐患。
关于save flush 可以看看我之前的博客CSDN,GitHub看看hibernate执行过程,可以发现在flush过程中才会去真正执行SQL语句,匹配数据库约束。因为hibernate默认是延迟提交的,当事务commit时才会刷新上下文。
Hibernate 上下文数据状态
在 Hibernate 的程序上下文中主要有以下三种状态
-
Transient (临时态) - 这个状态的实例不是上下文中的,也从未被加载到 Session,通常在数据库中没有对应的行,它通常只是你 new 出来的一个对象,为了保存的数据中。
-
Persistent (持久态) - 这个状态的实例是与唯一一个Session读写关联,在flush到数据库中是保证在数据中会有一条对应的记录
-
Detached(游离态) - 这状态的实例是曾经加载到Session中,但是现在不在Session中的。如果你从上下文中删除它,清除或关闭Session,或者通过序列化/反序列化过程放置实例,则实例将进入此状态。
这是一个简化的状态图,其中包含有关使状态转换发生的会话方法的注释。
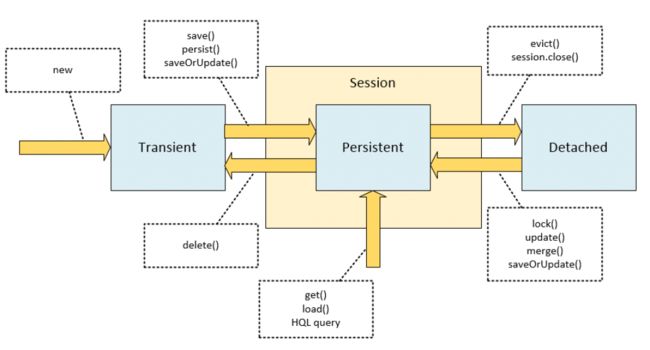
当实体实例处于持久状态时,对该实例的映射字段所做的所有更改将在刷新Session时应用于相应的数据库记录和字段。该持久实例可以被认为是“在线”,而分离的情况下已经“下线”,而不是监视更改。这意味着当更改持久对象的字段时,不必调用save,update或任何这些方法来获取对数据库的这些更改:当你完成它,您只需提交事务,或刷新或关闭会话。
来自网上介绍 经谷歌翻译
刷新上下文的方法
在刷新上下文之前看一段代码
@Service
@Transactional(rollbackFor = Exception.class)
public class TestService {
@Autowired
private ModelRepo modelRepo;
public Model test(){
Model model = new Model();
Model save = modelRepo.save(model); // 违反了数据库的约束
System.out.println("执行后置方法");
return save;
}
}
- 执行情况如下

继承 JpaRepository 手动 flush
- 将我们的repo继承于
JpaRepository,调用时显示调用flush()方法,代码如下
public interface ModelRepo extends JpaRepository<Model, String>,
JpaSpecificationExecutor<Model> {
}
@Service
@Transactional(rollbackFor = Exception.class)
public class TestService {
@Autowired
private ModelRepo modelRepo;
public Model test(){
Model model = new Model();
Model save = modelRepo.save(model);
modelRepo.flush(); //手动显示调用
System.out.println("执行后置方法");
return save;
}
}

刷新上下午文的原理
-
刷新上下文方法的核心就是调用
EventSource实现类org.hibernate.internalSessionImpl的flush()方法。不熟悉的同学可以看看我之前的博客CSDN,GitHub -
如果阅读过上一篇文章的朋友应该看到如下代码会发现代码有一些改动 这里使用的是 2.0.3.RELEASE 版本,但是主体逻辑还是一样的
@Override
public void flush() throws HibernateException {
checkOpen();
doFlush();
}
private void doFlush() {
checkTransactionNeeded();
checkTransactionSynchStatus();
try {
if ( persistenceContext.getCascadeLevel() > 0 ) {
throw new HibernateException( "Flush during cascade is dangerous" );
}
FlushEvent flushEvent = new FlushEvent( this );
for ( FlushEventListener listener : listeners( EventType.FLUSH ) ) {
listener.onFlush( flushEvent );
}
delayedAfterCompletion();
}
catch ( RuntimeException e ) {
throw exceptionConverter.convert( e );
}
}
- 现在我们已经知道了应该如何先执行SQL再处理后置业务代码,那么我们要如何进行AOP编程,尽量减少代码编写的工作量?
利用Spring的切面和事务传播机制
- 这种思路是我最初想减少样板代码所构思的方案
- 在Spring的业务层做一个环绕增强的切面
- 在切面中手动开启事务,因为Spring的默认事务传播级别为
Propagation.REQUIRED - 业务层中的事务是会继承于AOP切面的事务,可以AOP内部进行回滚
- 将项目中所有的repo注入到切面中去,进行类似于监听器模式的flush
public enum Propagation {
/**
* Support a current transaction, create a new one if none exists.
* Analogous to EJB transaction attribute of the same name.
* This is the default setting of a transaction annotation.
*/
/**
*支持当前事务,如果不存在则创建新事务。
*类似于同名的EJB事务属性。
* 这是事务注释的默认设置。
*/
REQUIRED(TransactionDefinition.PROPAGATION_REQUIRED),
...
}
public @interface Transactional {
/**
* The transaction propagation type.
* Defaults to {@link Propagation#REQUIRED}.
* @see org.springframework.transaction.interceptor.TransactionAttribute#getPropagationBehavior()
*/
Propagation propagation() default Propagation.REQUIRED;
}
service层代码
@Service
@Transactional(rollbackFor = Exception.class)
public class TestService {
@Autowired
private ModelRepo modelRepo;
public Model test(){
Model model = new Model();
Model save = modelRepo.save(model);
// modelRepo.flush();
System.out.println("执行后置方法");
return save;
}
}
切面代码
@Component
@Aspect
public class JpaAspect {
@Autowired
List<JpaRepository> jpaRepositories;
@Autowired
PlatformTransactionManager platformTransactionManager;
@Pointcut("execution(public * cn.jpa.TestService.*(..))")
public void jpaTarget() {
}
@Around("jpaTarget()")
public Object serviceThreadLocalHandle(ProceedingJoinPoint joinPoint) throws Throwable {
//手动开启事务
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
TransactionStatus status = platformTransactionManager.getTransaction(def);
Object proceed = null;
try {
proceed = joinPoint.proceed();
for (JpaRepository repository : jpaRepositories) {
repository.flush();
}
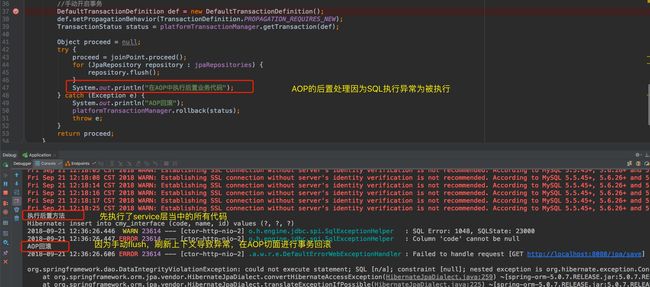
System.out.println("在AOP中执行后置业务代码");
} catch (Exception e) {
System.out.println("AOP回滚");
platformTransactionManager.rollback(status);
throw e;
}
return proceed;
}
}
执行效果如下
-
这样做确实可以有效的减少样板代码的数量,减少不必要的开发,但是有一些不太优雅的感觉
- 需要编写切面
- 需要在切面中手动开启/关闭事务,如果处理不好有点烦,而且还需要把握好service层的事务传播级别
- 需要对所有的repo的上下文进行刷新,有点冗余
-
当然作为一个减少样板代码同时保证代码逻辑正确的解决方案应该是完成了它应该做的目标
利用 Hibernate 的事件监听器
如果阅读过之前文章的同学应该会发现在执行save(entity)方法时的核心代码是放在一个监听器集合中去循环执行的。
repo 实现类的方法
package org.springframework.data.jpa.repository.support;
public class SimpleJpaRepository<T, ID>
@Transactional
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
监听器处代码
package org.hibernate.internal;
public final class SessionImpl
private void firePersist(PersistEvent event) {
try {
checkTransactionSynchStatus();
checkNoUnresolvedActionsBeforeOperation();
//监听器集合
for ( PersistEventListener listener : listeners( EventType.PERSIST ) ) {
listener.onPersist( event );
}
}
catch (MappingException e) {
throw exceptionConverter.convert( new IllegalArgumentException( e.getMessage() ) );
}
catch (RuntimeException e) {
throw exceptionConverter.convert( e );
}
finally {
try {
checkNoUnresolvedActionsAfterOperation();
}
catch (RuntimeException e) {
throw exceptionConverter.convert( e );
}
}
}
private void fireMerge(Map copiedAlready, MergeEvent event) {
try {
checkTransactionSynchStatus();
//监听器集合
for ( MergeEventListener listener : listeners( EventType.MERGE ) ) {
listener.onMerge( event, copiedAlready );
}
}
catch ( ObjectDeletedException sse ) {
throw exceptionConverter.convert( new IllegalArgumentException( sse ) );
}
catch ( MappingException e ) {
throw exceptionConverter.convert( new IllegalArgumentException( e.getMessage(), e ) );
}
catch ( RuntimeException e ) {
//including HibernateException
throw exceptionConverter.convert( e );
}
finally {
delayedAfterCompletion();
}
}
Hibernate事件监听器模式更多的信息可以看看jboss Hibernate 官方文档的介绍,里面介绍了一些Hibernate的原生事件,以及事件的触发时机,但是有一些还是没有介绍比如说,上文中提到过,下文中即将介绍的Merge,Persist。可能这些所有的事件想要全部都了解需要去自己一步一步的debug源码了。主要的事件是围绕着EventType这个类来使用的,全类名为org.hibernate.event.spi.EventType
- 所以目前我们的设计思路如下
- 编写一个自定义的Hibernate事件监听器
- 在自定义监听器中进行Hibernate上下文的刷新 session.flush()
- 将自定义监听器注册到Hibernate的上下文
编写一个自定义的Hibernate事件监听器
在自定义监听器中进行Hibernate上下文的刷新 session.flush()
- 根据上文代码可以看出save()是有两种情况的 Merge,Persist,所以可以搞两个监听器
// Persist 监听器
@Component
public class CostomPersistEventListener implements PersistEventListener {
@Override
public void onPersist(PersistEvent event) throws HibernateException {
System.out.println("My persist and flush");
EventSource session = event.getSession();
session.flush();
}
@Override
public void onPersist(PersistEvent event, Map createdAlready) throws HibernateException {
System.out.println("My persist with createdAlready and flush");
EventSource session = event.getSession();
session.flush();
}
}
// Merge 监听器
@Component
public class CostomMergeEventListener implements MergeEventListener {
@Override
public void onMerge(MergeEvent event) throws HibernateException {
System.out.println("My save");
EventSource session = event.getSession();
session.flush();
}
@Override
public void onMerge(MergeEvent event, Map copiedAlready) throws HibernateException {
System.out.println("My save with copiedAlready");
EventSource session = event.getSession();
session.flush();
}
}
将监听器注册到上下中
@Configuration
public class HibernateListenerConfigurer {
@PersistenceUnit
private EntityManagerFactory emf;
@Autowired
private CostomMergeEventListener costomMergeEventListener;
@Autowired
private CostomPersistEventListener costomPersistEventListener;
@PostConstruct
protected void init() {
SessionFactoryImpl sessionFactory = emf.unwrap(SessionFactoryImpl.class);
EventListenerRegistry registry = sessionFactory.getServiceRegistry().getService(EventListenerRegistry.class);
registry.getEventListenerGroup(EventType.MERGE).appendListener(costomMergeEventListener);
registry.getEventListenerGroup(EventType.PERSIST).appendListener(costomPersistEventListener);
}
}
执行效果如下图所示
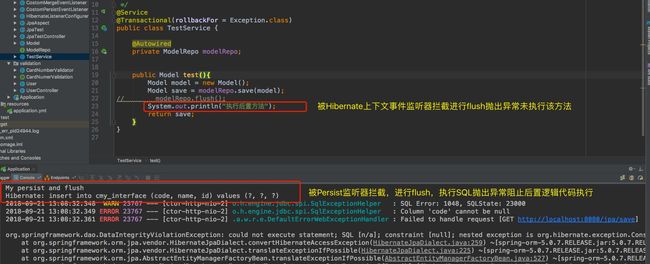
我们的目的到达了
小结
其实在我们平时开发工作中这种业务场景是很少见的。Hibernate这种延迟提交确实是可以满足大部分的开发需要,并且延迟提交可以有效的提高数据库访问的效率,减少数据库访问交互的次数。
如果阅读过Hibernate源码的同学应该知道,Hibernate是在flush的过程中进行数据交互的,应该是使用了一个批处理的方式执行的,当判断可以使用批处理时就使用批处理减少网络开销。虽然说Hibernate很重但是不得不说Hibernate这么长时间也是做了很多的优化工作。
而且Hibernate对自己的上下文数据进行了状态维护,当一次service中做了很多的业务操作,他其实是会现在内存中进行更新再转换成SQL语句更新到数据库中。比如级联更新,交叉引用等,(虽然我都不了解),但确实是有效的提升执行效率。
后期根据网上资料查询,Hibernate默认是在事务提交时和数据查询进行flush的。
对于Hibernate的一点个人理解,现在网上有很多关于Hibernate与Mybatis的比较,在文章即将结束之时我写写我对与二者的看法
-
在框架的功能性上来说,Hibernate应该是功能更加强大,是一个完整的ORM框架,应该是最成功的JPA规范实现。Mybatis在这一方面来说,Mybatis官方也承认自己是一个不完整的ORM,而且也与JPA规范无关。
-
学习成本,毫无疑问Hibernate的学习成本高于Mybatis的,Hibernate的代码量就比Mybatis要多出不少。而且里面的各种设计模式,上下文,事件监听,缓存使用等等想要完整的了解是要花很多心思去研究的。
-
移植性,这点应该是Hibernate更好一些,这也与JPA的理理念有关,JPA认为就应该是从JAVA到数据库,如果都使用了JPA规范写代码应该是可以做到一键切换数据源的。当然目前SQL语句主流数据库都是是支持的,所以在移植性上来说只要不是写存储过程,Mybatis虽然稍逊一筹但是,差别也不大。
-
自定义SQL语句编写,这方面Mybatis有着与生俱来的优势。尤其是动态SQL生成,复杂SQL查询。但是我认为这是JPA与Mybatis的理念有关。JPA认为一切都是应该是Java对象的描述方式进行,所以才会有级联,而Mybatis的理念应该是从数据库出发,java对象是数据库数据的一种展示。也行JPA算是区域驱动设计思想的一种体现吧。