Hadoop二次排序
MapReduce框架在把记录到达reducers之前会将记录按照键排序。对于任意一个特殊的键,然而,值是不排序的。甚至是,值在两次执行中的顺序是不一样的,原因是它们是从不同的map中来的,这些不同的map可能在不同的执行过程中结束的先后顺序不确定。通常情况下,大多数的MapReduce程序的reduce函数不会依赖于值的顺序。然而,我们也可通过以一种特殊的方式排序和分组键,来指定值的顺序。
要说明这个思想,考虑计算一年中最高气温的MapReduce程序。如果我们将值安排为降序,那么我们就不需要通过迭代来找出最大值——我们仅仅是拿出第一个值来,而忽略掉剩下的。(这个方法可能不是解决这个问题的最有效的方式,但是它说明了二次排序的工作方式)
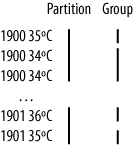
要达到这个目的,我们将我们键修改成一个组合体:年份和温度的结合。我们想要按照年份(升序),然后按照温度(降序)排序:
1900 35C
1900 34C
1900 34C
...
1901 36C
1901 35C
如果我们仅仅是修改了键,这不会起到任何的帮助,因为同样的年份将不会(通常情况下)进入到相同的reducer中,因为它们有着不同的键。对于实例,(1900, 35)和(1900, 34)将会进入到不同的reducer中。通过将键的年份设置一个分区器,我们可以保证相同年份的记录将进入到相同的reducer中。然而,这还是达不到我们的目标。一个分区器只是保证一个reducer接收到一个年份的所有的记录;它不能改变reducer在这个分区里通过key来做分组的事实:
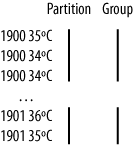
谜题最后的部分是控制分组的设置。如果我们通过键的年份部分进行分组,然后我们将看到一年的所有记录出现在一个reduce组中。既然它们是按照温度降序排列的,那么第一个就是最大温度:
做一个总结,这里有一个获得通过值排序的效果的方法:
1. 将键改成自然键和自然值的组合体
2. 键比较器应该通过组合键来排序,也就是说,自然键 and 自然值
3. 组合键的分类器和分组比较器应该被认为是自然键的分区和组合
将所有这些组合到一起就产生了一下代码。这个程序使用纯文本输入:
public class MaxTemperatureUsingSecondarySort
extends Configured implements Tool {
static class MaxTemperatureMapper extends MapReduceBase implements Mapper
private NcdcRecordParser parser = new NcdcRecordParser();
public void map(LongWritable key, Text value,
OutputCollector
throws IOException {
}
}
parser.parse(value);
if (parser.isValidTemperature()) {
output.collect(new IntPair(parser.getYearInt(),
+ parser.getAirTemperature()), NullWritable.get());
}
static class MaxTemperatureReducer extends MapReduceBase
implements Reducer
public void reduce(IntPair key, Iterator
OutputCollector
throws IOException {
}
}
output.collect(key, NullWritable.get());
public static class FirstPartitioner
implements Partitioner
@Override
public void configure(JobConf job) {}
}
@Override
public int getPartition(IntPair key, NullWritable value, int numPartitions) {
return Math.abs(key.getFirst() * 127) % numPartitions;
}
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
int cmp = IntPair.compare(ip1.getFirst(), ip2.getFirst());
if (cmp != 0) {
return cmp;
}
return -IntPair.compare(ip1.getSecond(), ip2.getSecond()); //reverse
}
}
public static class GroupComparator extends WritableComparator {
protected GroupComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
return IntPair.compare(ip1.getFirst(), ip2.getFirst());
}
}
@Override
public int run(String[] args) throws IOException {
JobConf conf = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (conf == null) {
return -1;
}
conf.setMapperClass(MaxTemperatureMapper.class);
conf.setPartitionerClass(FirstPartitioner.class);
conf.setOutputKeyComparatorClass(KeyComparator.class);
conf.setOutputValueGroupingComparator(GroupComparator.class);
conf.setReducerClass(MaxTemperatureReducer.class);
conf.setOutputKeyClass(IntPair.class);
conf.setOutputValueClass(NullWritable.class);
}
}
JobClient.runJob(conf);
return 0;
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureUsingSecondarySort(), args);
System.exit(exitCode);
}
在mapper中我们创建了一个代表年份和温度的键,使用了一个IntPair实现。我们不需要在值中存储任何值,因为我们可以从键中拿到第一个(最高的)温度,所以我们使用NullWritable。由于二次排序,reducer提交第一个键,是一个年份和最高气温的IntPair实例。IntPair的toString()方法创建了一个以tab分割的字符串,所以输出是一个以tab分割的年-温度对。
我们通过使用一个个性化的分区器,使用键的第一个字段(年份)作为分区依据。要按照年份升序排序和温度降序排序,我使用一个个性化的比较器,将字段抽取出来并做合适的比较。类似的,要按照年份分组,我们使用setOutputValueGroupingComparator(),来抽取键的第一个字段来比较。