集成学习之GBDT算法
Boosting树算法
Boosting树算法采用的是前向分步算法,假设前m-1轮迭代得到的强学习器是 f m − 1 ( x ) f_{m-1}(x) fm−1(x),第m轮的迭代目标是训练一个CART回归树模型的弱学习器 T ( x ; Θ m ) T(x;\Theta_m) T(x;Θm),使得本轮的损失函数 L ( y , f m ( x ) ) = L ( y , f m − 1 + T ( x ; Θ m ) ) L(y,f_m(x))=L(y,f_{m-1}+T(x;\Theta_m)) L(y,fm(x))=L(y,fm−1+T(x;Θm))最小化。本轮迭代找到决策树,使得样本的损失尽量变得更小。 Θ m = a r g min Θ m ∑ i = 1 N L ( y i , f m − 1 ( x i ) + T ( x i ; Θ m ) ) \Theta_m=arg\min_{\Theta_m}\sum_{i=1}^NL(y_i,f_{m-1}(x_i)+T(x_i;\Theta_m)) Θm=argΘmmini=1∑NL(yi,fm−1(xi)+T(xi;Θm))


事实上,Boosting树是通过前面的强学习器的数据残差来拟合当前模型,这些残差的累加能得到最终的预测值。举一个通俗的例子,训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图所示:
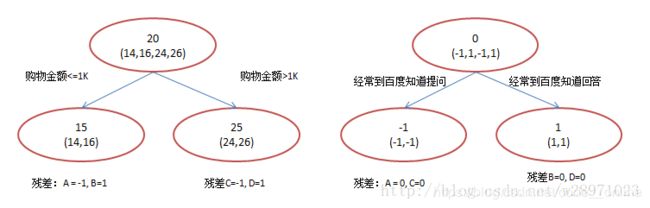
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
将两个回归树的预测结果进行汇总:
A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
GBDT
虽然提升树利用加法模型和前向分步算法实现学习的优化过程,但是一般的损失函数的每一步优化不是那么容易。针对这个问题,Freidman提出了梯度提升算法,利用了损失函数的负梯度拟合本轮损失的近似值,从而拟合一个CART回归树。第m轮的第i个样本的损失函数的负梯度表示为: r m i = − [ ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f m − 1 ( x ) r_{mi}=-\left[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\right]_{f(x)=f_{m-1}(x)} rmi=−[∂f(xi)∂L(yi,f(xi))]f(x)=fm−1(x)
利用 ( x i , r m i ) ( i = 1 , 2 , . . . , m ) (x_i,r_{mi})(i=1,2,...,m) (xi,rmi)(i=1,2,...,m)残差数据去拟合一个回归树,得到第m个回归树,其对应的叶节点区域 R m j ( j = 1 , 2 , . . . , J ) R_{mj}(j=1,2,...,J) Rmj(j=1,2,...,J),J是叶子节点的个数。
对于每一个叶子节点里的样本,为了使损失函数最小,拟合叶子节点最优的输出值 c m j c_{mj} cmj。 c m j = a r g min c ∑ x i ∈ R m j L ( y i , f m − 1 ( x i ) + c ) c_{mj}=arg\min_c\sum_{x_i\in R_{mj}}L(y_i,f_{m-1}(x_i)+c) cmj=argcminxi∈Rmj∑L(yi,fm−1(xi)+c)
这样得到本轮的决策树拟合函数: T ( x ; Θ m ) = ∑ j = 1 J c m j I ( x ∈ R m j ) T(x;\Theta_m)=\sum_{j=1}^Jc_{mj}I(x\in R_{mj}) T(x;Θm)=j=1∑JcmjI(x∈Rmj)
当前得到的强学习器为: f m ( x ) = f m − 1 ( x ) + ∑ j = 1 J c m j I ( x ∈ R m j ) f_m(x)=f_{m-1}(x)+\sum_{j=1}^Jc_{mj}I(x\in R_{mj}) fm(x)=fm−1(x)+j=1∑JcmjI(x∈Rmj)
GBDT回归算法
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\left\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),...,(xN,yN)},最大迭代次数M,损失函数 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x));
输出:强学习器 f ( x ) f(x) f(x)
-
初始化弱学习器 f 0 ( x ) = a r g min c ∑ i = 1 N L ( y i , c ) f_0(x)=arg\min_c\sum_{i=1}^NL(y_i,c) f0(x)=argcmini=1∑NL(yi,c)
-
对迭代轮数 m = 1 , 2 , . . . , M m=1,2,...,M m=1,2,...,M
(a)对样本 i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N,计算负梯度 r m i = − [ ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f m − 1 ( x ) r_{mi}=-\left[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}\right]_{f(x)=f_{m-1}(x)} rmi=−[∂f(xi)∂L(yi,f(xi))]f(x)=fm−1(x)
(b)利用 ( x i , r m i ) ( i = 1 , 2 , . . . , M ) (x_i,r_{mi})(i=1,2,...,M) (xi,rmi)(i=1,2,...,M),拟合一个回归树,得到第m个回归树,其对应的叶节点区域 R m j ( j = 1 , 2 , . . . , J ) R_{mj}(j=1,2,...,J) Rmj(j=1,2,...,J),J是叶子节点的个数。
(c)对叶子区域 j = 1 , 2 , . . . , J j=1,2,...,J j=1,2,...,J,计算最优拟合值 c m j = a r g min c ∑ x i ∈ R m j L ( y i , f m − 1 ( x i ) + c ) c_{mj}=arg\min_c\sum_{x_i\in R_{mj}}L(y_i,f_{m-1}(x_i)+c) cmj=argcminxi∈Rmj∑L(yi,fm−1(xi)+c)(d)更新强学习器: f m ( x ) = f m − 1 ( x ) + ∑ j = 1 J c m j I ( x ∈ R m j ) f_m(x)=f_{m-1}(x)+\sum_{j=1}^Jc_{mj}I(x\in R_{mj}) fm(x)=fm−1(x)+j=1∑JcmjI(x∈Rmj)
-
得到最终的强学习器 f ( x ) f(x) f(x):
f ( x ) = f M ( x ) = f 0 ( x ) + ∑ m = 1 M ∑ j = 1 J c m j I ( x ∈ R m j ) f(x)=f_M(x)=f_0(x)+\sum_{m=1}^M\sum_{j=1}^Jc_{mj}I(x\in R_{mj}) f(x)=fM(x)=f0(x)+m=1∑Mj=1∑JcmjI(x∈Rmj)
GBDT分类算法
由于分类算法的输出值不是连续值,而是离散类别,因此,GBDT通过离散类别与预测类别的概率之间的差异来拟合类别输出的误差。分类问题的损失函数通常有两种:一个是指数损失函数,另一个是类似于逻辑回归的对数似然损失函数。下面主要讲解了GBDT的二元分类算法,采用了对数损失函数。
GBDT二元分类算法
对数似然损失函数: L ( y , f ( x ) ) = l o g ( 1 + e x p ( − y f ( x ) ) ) L(y,f(x))=log(1+exp(-yf(x))) L(y,f(x))=log(1+exp(−yf(x)))
其中 y ∈ { − 1 , + 1 } y\in \left\{-1,+1\right\} y∈{−1,+1},此时的负梯度拟合残差 r m i = − [ ∂ L ( y , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f m − 1 ( x ) = y i 1 + e x p ( y i f ( x i ) ) r_{mi}=-\left[\frac{\partial L(y,f(x_i))}{\partial f(x_i) }\right]_{f(x)=f_{m-1}(x)}=\frac{y_i}{1+exp(y_if(x_i))} rmi=−[∂f(xi)∂L(y,f(xi))]f(x)=fm−1(x)=1+exp(yif(xi))yi
对于训练的决策树,各个叶子节点的最优拟合值为 c m j = a r g min c ∑ x i ∈ R m j l o g ( 1 + e x p ( − y i ( f m − 1 ( x i ) + c ) ) ) c_{mj}=arg\min_c\sum_{x_i\in R_{mj}}log(1+exp(-y_i(f_{m-1}(x_i)+c))) cmj=argcminxi∈Rmj∑log(1+exp(−yi(fm−1(xi)+c)))
上式比较难优化,一般使用近似值代替 c m j = ∑ x i ∈ R m j r m i / ∑ x i ∈ R m j ∣ r m i ∣ ( 1 − ∣ r m i ∣ ) c_{mj}=\sum_{x_i\in R_{mj}}r_{mi}/\sum_{x_i\in R_{mj}}|r_{mi}|(1-|r_{mi}|) cmj=xi∈Rmj∑rmi/xi∈Rmj∑∣rmi∣(1−∣rmi∣)
GBDT二分类算法的整个训练过程和GBDT回归算法相同,差异主要是损失函数的区别以及叶子节点的最优拟合值。
对于多元分类算法,假设一个样本x,可能属于K个类别,其估计值分别为 f 1 ( x ) , . . . , f K ( x ) f_1(x),...,f_K(x) f1(x),...,fK(x),第k类的概率表达式如下: p k ( x ) = e x p ( f k ( x ) ) / ∑ l = 1 K e x p ( f l ( x ) ) p_k(x)=exp(f_k(x))/\sum_{l=1}^Kexp(f_l(x)) pk(x)=exp(fk(x))/l=1∑Kexp(fl(x))其损失函数为 L ( y , f ( x ) ) = − ∑ k = 1 K y k l o g p k ( x ) L(y,f(x))=-\sum_{k=1}^Ky_klogp_k(x) L(y,f(x))=−∑k=1Kyklogpk(x),计算第m轮的第i个样本对应类别k的负梯度残差为 r m i k = − [ ∂ L ( y , f ( x i ) ) ∂ f ( x i ) ] f ( x ) = f k , m − 1 ( x ) = y i k − p k , m − 1 ( x i ) r_{mik}=-\left[\frac{\partial L(y,f(x_i))}{\partial f(x_i) }\right]_{f(x)=f_{k,m-1}(x)}=y_{ik}-p_{k,m-1}(x_i) rmik=−[∂f(xi)∂L(y,f(xi))]f(x)=fk,m−1(x)=yik−pk,m−1(xi)
GBDT常用损失函数
对于分类算法,损失函数一般是对数损失函数或者指数损失函数
- 指数损失函数的表达式:
L ( y , f ( x ) ) = e x p ( − y f ( x ) ) L(y,f(x))=exp(-yf(x)) L(y,f(x))=exp(−yf(x)) - 对数损失函数的表达式: L ( y , f ( x ) ) = l o g ( 1 + e x p ( − y f ( x ) ) ) L(y,f(x))=log(1+exp(-yf(x))) L(y,f(x))=log(1+exp(−yf(x)))
对于回归算法,常用的损失函数有以下几种:
- 均方差,最常见的回归损失函数: L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y,f(x))=(y-f(x))^2 L(y,f(x))=(y−f(x))2
- 绝对损失函数的表达式: L ( y , f ( x ) ) = ∣ y − f ( x ) ∣ L(y,f(x))=|y-f(x)| L(y,f(x))=∣y−f(x)∣其负梯度为 s i g n ( y i − f ( x i ) ) sign(y_i-f(x_i)) sign(yi−f(xi))
- Huber损失函数,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下: L ( y , f ( x ) ) = { 1 2 ( y − f ( x ) ) 2 , ∣ y − f ( x ) ∣ ≤ δ δ ( ∣ y − f ( x ) ∣ − δ 2 ) , ∣ y − f ( x ) ∣ > δ L(y,f(x))=\begin{cases} \frac{1}{2}(y-f(x))^2, & |y-f(x)|\leq \delta\\ \delta(|y-f(x)|-\frac{\delta}{2}), & |y-f(x)|> \delta \end{cases} L(y,f(x))={21(y−f(x))2,δ(∣y−f(x)∣−2δ),∣y−f(x)∣≤δ∣y−f(x)∣>δ
对应的负梯度误差为: r ( y i , f ( x i ) = { y i − f ( x i ) ∣ y i − f ( x i ) ∣ ≤ δ δ s i g n ( ∣ y i − f ( x i ) ∣ ) , ∣ y i − f ( x i ) ∣ > δ r(y_i,f(x_i)=\begin{cases} y_i-f(x_i) & |y_i-f(x_i)|\leq \delta\\ \delta sign(|y_i-f(x_i)|), & |y_i-f(x_i)|> \delta \end{cases} r(yi,f(xi)={yi−f(xi)δsign(∣yi−f(xi)∣),∣yi−f(xi)∣≤δ∣yi−f(xi)∣>δ - 分位数损失,其表达式为: L ( y , f ( x ) ) = ∑ y ≥ f ( x ) θ ∣ y − f ( x ) ∣ + ∑ y < f ( x ) ( 1 − θ ) ∣ y − f ( x ) ∣ L(y,f(x))=\sum_{y\ge f(x)}\theta|y-f(x)|+\sum_{y<f(x)}(1-\theta)|y-f(x)| L(y,f(x))=y≥f(x)∑θ∣y−f(x)∣+y<f(x)∑(1−θ)∣y−f(x)∣
其中 θ \theta θ为分位数,需在回归前指定,对应的负梯度残差为: r ( y i , f ( x i ) ) = { θ , y i ≥ f ( x i ) θ − 1 , y i < f ( x i ) r(y_i,f(x_i))=\begin{cases} \theta, & y_i \ge f(x_i)\\ \theta -1, & y_i < f(x_i) \end{cases} r(yi,f(xi))={θ,θ−1,yi≥f(xi)yi<f(xi)
GBDT的正则化
和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化有以下三种方式。
- 和AdaBoost类似,即步长(learning rate) η \eta η,对于前面的弱学习器的迭代 f k ( x ) = f k − 1 ( x ) + h k ( x ) f_k(x)=f_{k-1}(x)+h_k(x) fk(x)=fk−1(x)+hk(x),加上正则化项,即 f k ( x ) = f k − 1 ( x ) + η h k ( x ) f_k(x)=f_{k-1}(x)+\eta h_k(x) fk(x)=fk−1(x)+ηhk(x) η \eta η的取值范围为(0,1],对于同样的训练集学习效果,较小的 η \eta η意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
- 正则化的方式是通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
- 对于弱学习器即CART回归树进行正则化剪枝
GBDT实战
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
print('Loading data...')
# load data
boston = load_boston()
data = boston.data
target = boston.target
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=0.2,random_state=2)
print('Starting training model...')
# train
boost = GradientBoostingRegressor(loss='ls',
learning_rate=0.1,
n_estimators=100,
subsample=1.0,
criterion='friedman_mse',
max_depth=3)
boost.fit(X_train,y_train)
print('Model training completed...')
print('Starting evaluating model...')
# Eval the trained model
print("the rmse of model's prediction is:",mean_squared_error(y_test,boost.predict(X_test))**0.5)
print("the score of model is: %f" % boost.score(X_test,y_test))
print("the feature importance of model is:{}".format(list(boost.feature_importances_)))
# Plot training deviance
test_score = np.zeros((boost.n_estimators,),dtype=np.float32)
for idx,y_pred in enumerate(boost.staged_predict(X_test)):
test_score[idx] = boost.loss_(y_test,y_pred)
plt.figure(figsize=(12,6))
plt.subplot(1,2,1)
plt.plot(np.arange(boost.n_estimators)+1,boost.train_score_,'b-',label='Training Set Deviance')
plt.plot(np.arange(boost.n_estimators)+1,test_score,'r-',label='Test Set Deviance')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
plt.title('Deviance')
plt.legend(loc='upper right')
# Plot feature importance
feature_importance = boost.feature_importances_
# make importances relative to max importance
feature_importance = 100.0 * feature_importance / feature_importance.max()
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0])
plt.subplot(1,2,2)
plt.barh(pos,feature_importance[sorted_idx],align = 'center')
plt.yticks(pos,boston.feature_names[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show()
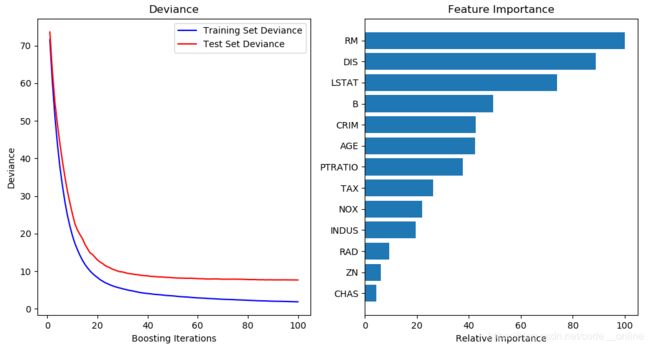
实验结果如下:
Loading data...
Starting training model...
Model training completed...
Starting evaluating model...
the rmse of model's prediction is: 2.7615984016
the score of model is: 0.908840
the feature importance of model is:[0.084712646875127848, 0.0097351165703343095, 0.040617110162197712, 0.0081960085266105723, 0.043264545727389629, 0.19021745274900886, 0.08417347055698729, 0.16845320584399176, 0.01774046578783461, 0.047947146061769731, 0.072053189758934655, 0.090655113920724922, 0.14223452745908799]
参考文献
- https://www.cnblogs.com/pinard/p/6140514.html#!comments
- https://www.cnblogs.com/peizhe123/p/5086128.html
- J. Friedman, Greedy Function Approximation: A Gradient Boosting Machine, The Annals of Statistics, Vol. 29, No. 5, 2001.
- 李航《统计学习方法》
- scikit-learn官方文档