kafka入门
kafka入门学习笔记
1、目标
- 1、掌握kafka相关概念
- 2、掌握搭建一个kafka集群
- 3、掌握kafka生产者和消费者代码开发
- 4、掌握kafka的分区策略
- 5、掌握kafka整合flume
- 6、掌握kafka如何保证消息不丢失
2、kafka概述
2.1 kafka是什么
kafka是由linkedin开源,捐献apache基金会,它是一个实时的分布式消息队列。
它提供了一个对于实时处理下高可靠,高性能,高吞吐量、低延迟的平台
Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
2.2 消息队列的作用
- 核心作用 :
解耦、异步、并行
2.3 kafka与activeMQ区别
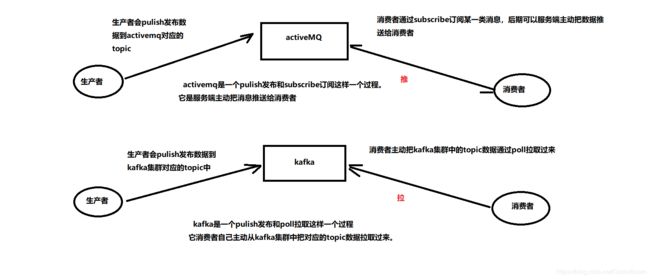
activeMQ:它是一个严格的JMS(java message)框架实现,后期需要有严格的事务去控制
kafka:它并不是一个严格的JMS(java message)框架实现,它是类似于JMS框架 , 它会主动把数据从kafka集群中拉取过来,它追求的高吞吐量。
2.3.1、在架构模型方面
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
2.3.2、在吞吐量
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
2.3.3、在可用性方面
rabbitMQ支持miror的queue,主queue失效,miror queue接管。kafka的broker支持主备模式。
2.3.4、在集群负载均衡方面
kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
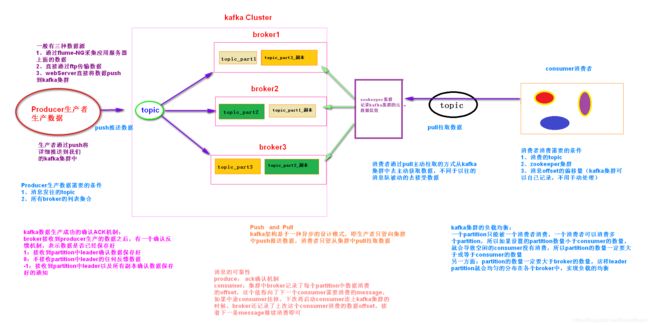
3、kafka集群架构
-
1、Producer
- 生产者
- 数据通过生产者写入到kafka集群中
- 生产者
-
2、broker
- kafka集群中每一个节点就是一个broker,后期kafka的数据就存放在每一个broker
-
3、topic
- 消息的主题,它是一类消息的聚集 , 每个topic将被分成多个partition(区),在集群的配置文件中配置。
-
4、partition
- 分区概念
- 一个topic中有很多个分区,每一个分区就存在一部分数据。
- 每个partition由多个segment组成
- 任何发布到此partition的消息都会被直接追加到log文件的尾部
- 每个partition在内存中对应一个index列表,记录每个segment中的第一条消息偏移。这样查找消息的时候,先在index列表中定位消息位置,再读取文件,速度快
- 发布者发到某个topic的消息会被均匀的分布到多个part上,broker收到发布消息往对应part的最后一个segment上添加该消息。
- 分区概念
-
5、replication
- 副本
- 一个topic中有很多个分区,每一个分区构建多个副本,保证数据的安全可靠性
- 副本
-
6、segment
- 它就是用来存储每一个分区中的数据,它里面包括了2类文件
- 一个是log文件,它用于存在该分区的数据
- 一个是index文件,它用于存在数据的索引信息数据
- 就是为log文件中的数据构建索引
- 方便后期能够快速定位到我们需要的数据在整个log文件的哪一块
- 就是为log文件中的数据构建索引
- 每个segment中存储多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射
- 当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到
- segment达到一定的大小(可以通过配置文件设定,默认1G)后将不会再往该segment写数据,broker会创建新的segment
- 它就是用来存储每一个分区中的数据,它里面包括了2类文件
-
7、zookeeper
- 主要是使用zk帮我们管理kafka集群的元数据信息
- kafka每一个broker地址
- 所有topic的信息
- 消费者的信息
- 主要是使用zk帮我们管理kafka集群的元数据信息
-
8、consumer
- 消费者
- 消费者后期去消费kafka集群中topic的数据
- 条件
- 1、kafka集群地址
- 2、需要消费的topic名称
- 3、消费的topic的偏移量(记录了消费的位置,从哪一块开始消费)
- 条件
- 消费者后期去消费kafka集群中topic的数据
- 消费者
-
9、offset
-
偏移量
- 它就是记录下每一个消费者消费的位置在哪里
-
有2中保存方式
- 第一种
- 可以通过kafka集群自己去保存,这个时候由它自身有一个内置的topic去存储偏移量
- __consumer_offsets
- 它默认有50个分区,这些分区就存在了消费者消费数据的偏移量
- 第二种
- 可以通过zk去保存
- 第一种
-
作用
它是记录了每一个消费者消费topic每一个分区的位置,好处:方便于后期消费者程序挂掉了,然后正常启动,启动之后,它会读取上一次消费的记录,继续向后面消费。
-
4、kafka集群安装部署
-
1、下载对应的安装包
- 访问kafka官网:kafka.apache.org
- https://archive.apache.org/dist/kafka/1.0.0/kafka_2.11-1.0.0.tgz
- kafka_2.11-1.0.0.tgz
-
2、规划安装目录
- /export/servers
-
3、上传安装包到服务器中
-
4、解压安装包到指定的安装目录
tar -zxvf kafka_2.11-1.0.0.tgz -C /export/servers
-
5、重命名解压目录
mv kafka_2.11-1.0.0 kafka
-
6、修改配置文件
-
在node1上进去到kafka安装目录下有一个config文件夹
-
vim server.properties, 修改和添加如下配置即可#指定broker的id,它是唯一标识,不能够重复 broker.id=0 #指定当前broker的服务地址 host.name=node-1 #kafka集群数据存放的目录 log.dirs=/export/servers/kafka/kafka-logs #指定依赖zk的地址 zookeeper.connect=node-1:2181,node-2:2181,node-3:2181 #指定kafka中的topic是否可以删除,默认是false,表示不可以删除,改为true,可以删除 delete.topic.enable=true
-
-
-
7、配置kafka环境变量
-
vim /etc/profileexport KAFKA_HOME=/export/servers/kafka export PATH=$PATH:$KAFKA_HOME/bin
-
-
8、分发kafka安装目录和环境变量
scp -r kafka node-2:/export/servers scp -r kafka node-3:/export/servers scp /etc/profile node-2:/etc scp /etc/profile node-3:/etc -
9、修改node-2和node-3配置文件信息
-
node-2
vim server.properties
#指定broker的id,它是唯一标识,不能够重复 broker.id=1 #指定当前broker的服务地址 host.name=node-2 #kafka集群数据存放的目录 log.dirs=/export/servers/kafka/kafka-logs #指定依赖zk的地址 zookeeper.connect=node-1:2181,node-2:2181,node-3:2181 #指定kafka中的topic是否可以删除,默认是false,表示不可以删除,改为true,可以删除 delete.topic.enable=true -
node-3
-
vim server.properties#指定broker的id,它是唯一标识,不能够重复 broker.id=2 #指定当前broker的服务地址 host.name=node-3 #kafka集群数据存放的目录 log.dirs=/export/servers/kafka/kafka-logs #指定依赖zk的地址 zookeeper.connect=node-1:2181,node-2:2181,node-3:2181 #指定kafka中的topic是否可以删除,默认是false,表示不可以删除,改为true,可以删除 delete.topic.enable=true
-
-
-
10、让所有kafka节点环境变量生效
- 在所有kafka节点执行
source /etc/profile
- 在所有kafka节点执行
5、kafka集群启动和停止
-
1、启动
-
1、先启动zk集群
-
2、然后再启动kafka集群
-
需要再每一个kafka节点执行
nohup kafka-server-start.sh /export/servers/kafka/config/server.properties > /dev/null 2>&1 & -
一键启动脚本
vim start-kafka.sh
#!/bin/sh for host in node-1 node-2 node-3 do ssh $host "source /etc/profile;nohup kafka-server-start.sh /export/servers/kafka/config/server.properties > /dev/null 2>&1 &" echo "$host kafka is running" done -
sh start-kafka.sh
-
-
-
2、停止
-
1、需要再每一个台kafka节点执行
-
kafka-server-stop.sh
这个脚本由于不同的linux版本,有一定问题(centos 6.x) ps ax | grep -i 'kafka\.Kafka' | grep java | grep -v grep | awk '{print $1}' 改为 ps ax | grep -i 'kafka' | grep java | grep -v grep | awk '{print $1}' -
一键关闭脚本
#!/bin/sh for host in node-1 node-2 node-3 do ssh $host "source /etc/profile;kafka-server-stop.sh" echo "$host kafka is stop" done -
-
6、kafka管理命令的使用
-
1、创建topic
-
kafka-topics.shkafka-topics.sh --create --topic test --partitions 3 --replication-factor 2 --zookeeper node-1:2181,node-2:2181,node-3:2181 --create :表示要创建 --topic:指定要创建的topic名称 --partitions:指定要创建的topic有几个分区 --replication-factor:指定副本数 --zookeeper:指定zk地址
-
-
2、查看kafka集群有哪些topic
-
kafka-topics.shkafka-topics.sh --list --zookeeper node-1:2181,node-2:2181,node-3:2181 --list:查看kafka集群有哪些topic
-
-
3、模拟一个生产者向topic发送数据
-
kafka-console-producer.shkafka-console-producer.sh --topic test --broker-list node-1:9092,node-2:9092,node-3:9092 --topic:指定向哪一个topic生产数据 --broker-list :指定kafka集群地址
-
-
4、模拟一个消费者去消费topic的数据
-
kafka-console-consumer.shkafka-console-consumer.sh --bootstrap-server node-1:9092,node-2:9092,node-3:9092 --from-beginning --topic test --bootstrap-server:指定kafka集群地址 --from-beginning:指定从第一条数据开始消费 --topic:指定消费哪一个topic数据 kafka-console-consumer.sh --zookeeper node-1:2181,node-2:2181,node-3:2181 --from-beginning --topic test
-
-
5、删除topic
-
kafka-topics.shkafka-topics.sh --delete --topic test --zookeeper node1:2181,node2:2181,node3:2181 --delete:表示要删除操作 --topic:指定要删除的topic名称 --zookeeper :指定zk服务地址
-
7、kafka生产者和消费者java代码开发
-
引入依赖
<dependencies> <dependency> <groupId>org.apache.kafkagroupId> <artifactId>kafka-clientsartifactId> <version>1.0.0version> dependency> dependencies>
7.1 生产者代码开发
package cn.itcast.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
//todo:开发一个kafka的生产者代码
public class KafkaProducerStudy {
public static void main(String[] args) {
Properties props = new Properties();
//kafka集群地址
props.put("bootstrap.servers", "node-1:9092,node-2:9092,node-3:9092");
//kafka的acks消息确认机制
//acks一共有4个选项
//-1和all:表示生产者发送数据给topic,需要所有该topic分区副本把数据保存正常
//1: 表示生产者发送数据给topic,只需要分区的主副本已经把数据保存正常
//0:生产者只管发数据,不需要确认,丢失数据可能性最高
props.put("acks", "all");
//重试次数
props.put("retries", 0);
//每个批次写入数据的大小
props.put("batch.size", 16384);
//延迟多久进行写入
props.put("linger.ms", 1);
//缓冲区的内存大小
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//设置自己的分区函数
props.put("partitioner.class","cn.itcast.kafka.MyPartitioner");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 100; i++)
//ProducerRecord 有2个泛型 第一个String表示消息的key类型,在这里表示消息的标识,第二个String表示消息内容本身
//构建ProducerRecord对象需要3个参数:第一个是topic名称,第二个就是消息的key,第三个消息内容本身
// producer.send(new ProducerRecord("test", Integer.toString(i), "hadoop spark"));
//kafka分区策略:4种分区策略
//1、指定具体的分区号,数据就按照指定的分区号,流入到对应分区中
//producer.send(new ProducerRecord("test", 0,Integer.toString(i), "hadoop spark"));
//2、不指定具体的分区号,指定消息的key(不断变化) 按照key.hashcode%分区数=分区号,hashPartitioner
//producer.send(new ProducerRecord("test", Integer.toString(i), "hadoop spark"));
//3、不指定具体的分区号,也不指定消息的key,它是采用轮训(随机)的方式写入到不同分区中。
//producer.send(new ProducerRecord("test","hadoop spark"));
//4、自定义分区函数
producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "hadoop spark"));
producer.close();
}
}
7.2 消费者代码开发
- 1、自动提交偏移量
package cn.itcast.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
//todo:开发kafka的消费者代码-----自动提交偏移量
public class KafkaConsumerStudy {
public static void main(String[] args) {
Properties props = new Properties();
//kafka集群地址
props.put("bootstrap.servers", "node-1:9092,node-2:9092,node-3:9092");
//消费者组id
props.put("group.id", "test");
//自动提交消费的偏移量
props.put("enable.auto.commit", "true");
//每隔多久提交一次偏移量
props.put("auto.commit.interval.ms", "1000");
//key反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//value 反序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
//指定消费的topic名称,可以有多个
consumer.subscribe(Arrays.asList("test"));
while (true) {
//指定数据拉取的时间间隔
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
- 2、手动提交偏移量
package cn.itcast.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
//todo:开发一个kafka消费者程序-------自己提交偏移量
public class KafkaConsumerManualOffset {
public static void main(String[] args) {
Properties props = new Properties();
//指定kafka集群地址
props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
//消费者组id
props.put("group.id", "test");
// 手动提交偏移量
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<ConsumerRecord<String, String>>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
//判断下数据有没有超过200条数据
if (buffer.size() >= minBatchSize) {
// insertIntoDb(buffer); //具体的处理逻辑
System.out.println("当前总条数据:"+buffer.size());
//手动提交偏移量
consumer.commitSync();
buffer.clear();
}
}
}
}

8、kafka的分区策略
-
当前生产者产生的数据到底会流入到topic的哪一个分区中去?这里就涉及到kafka的分区策略
-
kafka分区策略:4种分区策略
-
1、指定具体的分区号,数据就按照指定的分区号,流入到对应分区中
producer.send(new ProducerRecord<String, String>("test", 0,Integer.toString(i), "hadoop spark")); -
2、不指定具体的分区号,指定消息的key(不断变化) 按照key.hashcode%分区数=分区号
producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "hadoop spark")); -
3、不指定具体的分区号,也不指定消息的key,它是采用轮训(随机)的方式写入到不同分区中
producer.send(new ProducerRecord<String, String>("test","hadoop spark")); -
4、自定义分区函数
//设置自己的分区函数 props.put("partitioner.class","cn.itcast.kafka.MyPartitioner"); producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), "hadoop spark"));
package cn.itcast.kafka; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; //todo:开发一个kafka的生产者代码 public class KafkaProducerStudy { public static void main(String[] args) { Properties props = new Properties(); //kafka集群地址 props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092"); //kafka的acks消息确认机制 props.put("acks", "all"); //重试次数 props.put("retries", 0); //每个批次写入数据的大小 props.put("batch.size", 16384); //延迟多久进行写入 props.put("linger.ms", 1); //缓冲区的内存大小 props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //设置自己的分区函数 props.put("partitioner.class","cn.itcast.kafka.MyPartitioner"); Producer<String, String> producer = new KafkaProducer<String, String>(props); for (int i = 0; i < 100; i++) //ProducerRecord -
-
自定义分区函数
package cn.itcast.kafka; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; //自定义分区函数 public class MyPartitioner implements Partitioner{ /** * 该方法会返回一个分区号 * @param topic topic的名称 * @param key 消息的key * @param keyBytes 消息的key字节数组 * @param value 消息的内容 * @param valueBytes 消息的内容字节数组 * @param cluster kafka集群对象 * @return */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { //自己去实现hashPartitioner key.hashcode%分区数=分区号 int numPartions = cluster.partitionsForTopic("test").size(); //test有3个分区,对应的分区号就分别为:0 1 2 // -2 -1 0 1 2 return Math.abs(key.hashCode()%numPartions); } public void close() { } public void configure(Map<String, ?> configs) { } }
9、kafka文件存储机制
可以见参考资源《kafka的文件存储机制.md》
note:
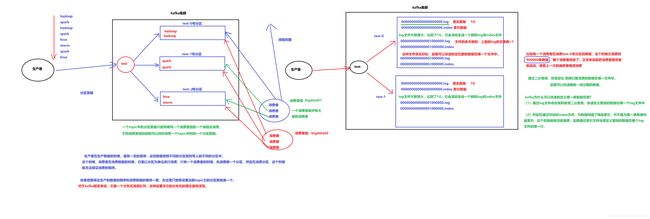
- 一个topic中的分区数据只能够被同一个消费者组的一个线程取消费
- 不同消费者组的线程可以同时消费一个topic中的同一个分区数据
生产者在生产数据的时候 , 是有一定的顺序 , 这些数据按照不同的分区规则写入到不同的分区中 . 这个时候 , 消费者在消费数据的时候 , 它是以分区为单位进行消费 , 只有一个消费者的时候 , 先消费哪一个分区 , 然后再消费其他分区 , 这个时候就无法保证消费的顺序 .
如果想要保证生产的数据的顺序和消费数据的顺序一致 , 在这里只能够设置当前topic的分区数就是一个 ,
对于kafka框架来说 , 它是一个分布式消息队列 , 这种设置与它的分布式的理念是有违背的. 为什么kafka可以快速的定义那一条数据在哪?
- 通过log文件命令规则使用二分查询 , 快速定义要找的数据在哪个文件中
- 然后在通过对应的index文件 , 为数据构建了稀疏索引 , 并不是为每一条数据构建索引 , 这是为了避免空间浪费 , 后期通过索引文件快速定义要找的数据在整个log文件的哪一行
具体原因参考《kafka为什么那么快.md》
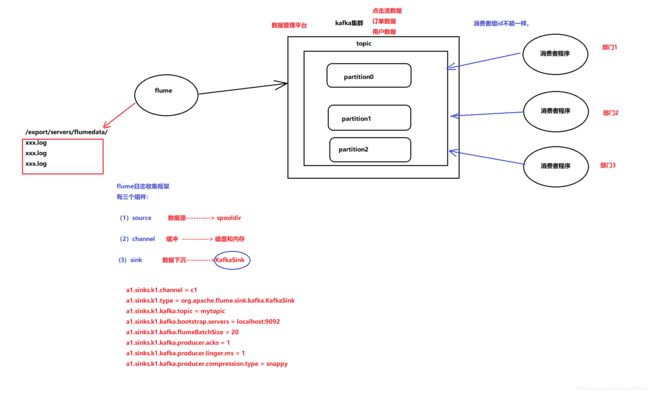
10、kafka整合flume
-
1、安装flume和kafka
-
2、修改flume配置
vim flume-kafka.conf
#为我们的source channel sink起名 a1.sources = r1 a1.channels = c1 a1.sinks = k1 #指定我们的source收集到的数据发送到哪个管道 a1.sources.r1.channels = c1 #指定我们的source数据收集策略 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /export/servers/flumedata a1.sources.r1.deletePolicy = never a1.sources.r1.fileSuffix = .COMPLETED a1.sources.r1.ignorePattern = ^(.)*\\.tmp$ a1.sources.r1.inputCharset = utf-8 #指定我们的channel为memory,即表示所有的数据都装进memory当中 a1.channels.c1.type = memory #指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据 a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = test a1.sinks.k1.kafka.bootstrap.servers = node-1:9092,node-2:9092,node-3:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 -
3、启动flume(需要在flume文件目录下)
bin/flume-ng agent -n a1 -c conf -f conf/flume-kafka.conf -Dflume.root.logger=info,console
11、kafka如何保证数据不丢失
-
1、生产者保证数据不丢失
-
就是利用kafka的ack机制
-
同步模式
//指定为同步模式 producer.type=sync //ack确认机制等于1,只需要主副本确认数据保存成功就可以了,后期从副本自己去同步数据 request.required.acks=1 -
异步模式
//指定为异步模式 producer.type=async //ack确认机制等于1,只需要主副本确认数据保存成功就可以了,后期从副本自己去同步数据 request.required.acks=1 //指定数据缓存到什么时候发送出去 queue.buffering.max.ms=5000 //指定数据缓存到多少条之后发送出去 queue.buffering.max.messages=10000 //数据达到了发送的阈值,后期由于一些原因导致数据并没有发送出去,这个时候对于缓存的数据是否保留,-1保留未成功发送的数据, 0就是不保留,直接舍弃掉。 queue.enqueue.timeout.ms = -1 //每次发送的数据量条数 batch.num.messages=200
-
-
-
2、broker—kafka集群自己本身
- kafka中有很多个topic,每一个topic有很多个分区,每一个分区有多个副本。通过多副本机制保证数据的安全性
-
3、消费者保证数据不丢失
- 每一个消费者在消费数据的时候,都把当前消费的位置记录下来,后续消费者程序挂掉了,然后正常重启,读取上一次消费的偏移量offset,接着上一次继续消费。
12、kafkaManager监控工具的安装与使用
可以参考资料《kafka_manager监控工具的安装与使用.md》文档