pandas系列学习(三):DataFrame
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
pandas系列学习(一):pandas入门
pandas系列学习(二):Series
pandas系列学习(三):DataFrame
如果你正在进行数据科学,从基于 Excel 的分析转向 Python 脚本和自动分析领域,你将会遇到非常流行的数据处理方式 Pandas。Pandas 的开发始于 2008 年,主要开发人员是 Wes McKinney,该库已经成为使用 Python 进行数据分析和管理的标准。对于任何基于 Python 的数据专业人士,pandas 都是必不可少的工具。
这篇文章的目的是帮助初学者掌握 pandas 的基本数据格式 —— DataFrame。我们将研究创建数据框架的基本方法,DataFrame 是如何工作的。
本文中的主题是以下内容:
- 将数据从文件加载到 Python Pandas DataFrame 中;
- 检查数据的基本统计信息;
- 修改一些数值;
- 最后将结果输出到新文件;
什么是 DataFrame?
pandas 库将 DataFrame 定义为具有行和列的二维数据,大小可变的数据结构。简而言之,你可以将 DataFrame 视为数据表,即一维格式化的二维数据,它具有以下特征:
- 数据中可以有多个行和列;
- 每行代表一个数据样本;
- 每列包含描述样本的不同变量;
- 每列中的数据通常是相同类型的数据 —— 例如,数字,字符串,日期;
- 通常,与 Excel 数据集不同的是,DataFrame 避免丢失值,并且行或列之间没有间隙和空值;
举例来说,以下数据集很适合 Pandas DataFrame:
- 在学校系统 DataFrame 中 —— 每行可以代表学校中的单个学生,列可以表示学生姓名(字符串),年龄(数字),出生日期(日期)和地址(字符串);
- 在经济学数据框架中,每一行可以代表一个城市或者地理区域,列可能包括区域名称(字符串),人口(数量),人口平均年龄(数量),住户数量(数量),每个地区的学校数量(数量)等;
- 在电子商务系统或者商店中,DataFrame 中的每一行都可用于表示客户,其中有购买商品数量(数量),原始注册日期(日期)和信用卡(字符串);
创建 Pandas DataFrame
我们将研究两种创建 DataFrame 的方法 —— 手动创建和逗号分隔值(CSV)文件。
手动输入数据
每个数据科学项目的开始将包括将有用的数据导入分析环境,在本例中为 Python 。有多种方法可以在 Python 中创建 DataFrame 数据,最简单的犯法是手动将数据输入 Python,这显然只适用于微小的数据集。
data = {"column_1": [1,2,3,4,5],
"another_column": ["this", "column", "has", "strings", "inside"],
"float_column": [0.1,0.5,33,48,42.5558],
"binary_solo": [True, False, True, True, False]
}
new_dataframe = pd.DataFrame(data)
new_dataframe
| another_column | binary_solo | column_1 | float_column | |
|---|---|---|---|---|
| 0 | this | True | 1 | 0.1000 |
| 1 | column | False | 2 | 0.5000 |
| 2 | has | True | 3 | 33.0000 |
| 3 | strings | True | 4 | 48.0000 |
| 4 | inside | False | 5 | 42.5558 |
使用 Python 词典和列表创建 DataFrame 仅适用于你可以手动输入的小型数据集。还有其他方法可以格式化手动输入的数据,你可以查看官网。
请注意,我们一般都是预定将 pandas 库加载为 pd,这种方式也是官网推荐的方式,也会我们日常习惯用到的方式。
将 CSV 数据加载到 pandas 中
一旦知道文件的路径,使用 pandas 中的 read_csv() 函数就可以非常简单的从 csv 文件创建 DataFrame 。csv 文件是包含表格形式数据的文本文件,其中列使用“,”逗号字符分割,行位于不同的行上。
如果你的数据是采用其他形式,例如 SQL数据库或者 Excel(XLS / XLSX)文件,则额可以查看其他函数以从这些源读取到 DataFrame 中,即 read_xlsx,read_sql 。但是,为简单起见,有时候最好将数据直接提取到 csv 然后再使用它们。
我们来举个例子,我们将从 Data Science 竞赛网站 kaggle 下载的数据来记性实验,你可以直接点击这个链接进行下载。这个数据的格式非常的好,你可以现在 Excel 中打开它进行预览:

样本数据包含 21478 行数据,每行对应于来自特定国家地区的食物来源,前 10 列代表样本国家和食品的信息,其余栏代表 1963 年至 2013 年每年的粮食产量(总共 63 列)。
接下来,我们可以使用 pandas 来来加载这个 csv 数据,如下所示:
path_to_file = './Downloads/FAO+database.csv'
data = pd.read_csv(path_to_file, encoding='ISO-8859-1')
print(type(data))
预览并检查 pandas DataFrame 中的数据
在 Python 中有数据之后,你肯定希望看到数据已经加载,并确认存在预期的行和列。
打印数据
如果你使用的是 Jupyter ,只需要输入数据库的名称即可获得输出良好的输出。打印是预览加载数据的便捷方式,你可以确认列名是否已经正确导入,数据格式是否符合预期,以及是否有任何缺失值。
data.head()
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AF | 2 | Afghanistan | 2511 | Wheat and products | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 3249.0 | 3486.0 | 3704.0 | 4164.0 | 4252.0 | 4538.0 | 4605.0 | 4711.0 | 4810 | 4895 |
| 1 | AF | 2 | Afghanistan | 2805 | Rice (Milled Equivalent) | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 419.0 | 445.0 | 546.0 | 455.0 | 490.0 | 415.0 | 442.0 | 476.0 | 425 | 422 |
| 2 | AF | 2 | Afghanistan | 2513 | Barley and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 58.0 | 236.0 | 262.0 | 263.0 | 230.0 | 379.0 | 315.0 | 203.0 | 367 | 360 |
| 3 | AF | 2 | Afghanistan | 2513 | Barley and products | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 185.0 | 43.0 | 44.0 | 48.0 | 62.0 | 55.0 | 60.0 | 72.0 | 78 | 89 |
| 4 | AF | 2 | Afghanistan | 2514 | Maize and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 120.0 | 208.0 | 233.0 | 249.0 | 247.0 | 195.0 | 178.0 | 191.0 | 200 | 200 |
获得 DataFrame 的行和列
shape 命令提供有关于数据集大小的信息 —— shape 返回一个包含行数的元祖,以及 DataFrame 中数据的列数。另一个描述属性是 ‘ndim’,它给出了数据中的维数,通常为 2 。
data.shape
(21477, 63)
data.ndim
2
从上面的结果中,我们可以看到我们的食品生产数据包含 21477 行,每行有 63 列,如 .shape 的输出所示。我们有两个维度 —— 即具有高度和宽度的2D数据帧。如果你的数据只有一列,则 ndim 将返回 1。
使用 head() 和 tail() 预览 DataFrame
默认情况下,DataFrame.head() 函数向你显示 DataFrame 中的前5行数据,相反的是 DataFrame.tail() 函数向你显示 DataFrame 中的最后5行数据。
如果你想打印特定的行数,那么你只需要向 head() 和 tail() 函数中传入特定的数字就行了。比如你想打印最开始的 10 行数据,那么你只需要调用 head(10) 就可以打印最开始的10行数据了。
data.head()
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AF | 2 | Afghanistan | 2511 | Wheat and products | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 3249.0 | 3486.0 | 3704.0 | 4164.0 | 4252.0 | 4538.0 | 4605.0 | 4711.0 | 4810 | 4895 |
| 1 | AF | 2 | Afghanistan | 2805 | Rice (Milled Equivalent) | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 419.0 | 445.0 | 546.0 | 455.0 | 490.0 | 415.0 | 442.0 | 476.0 | 425 | 422 |
| 2 | AF | 2 | Afghanistan | 2513 | Barley and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 58.0 | 236.0 | 262.0 | 263.0 | 230.0 | 379.0 | 315.0 | 203.0 | 367 | 360 |
| 3 | AF | 2 | Afghanistan | 2513 | Barley and products | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 185.0 | 43.0 | 44.0 | 48.0 | 62.0 | 55.0 | 60.0 | 72.0 | 78 | 89 |
| 4 | AF | 2 | Afghanistan | 2514 | Maize and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 120.0 | 208.0 | 233.0 | 249.0 | 247.0 | 195.0 | 178.0 | 191.0 | 200 | 200 |
5 rows × 63 columns
data.tail()
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21472 | ZW | 181 | Zimbabwe | 2948 | Milk - Excluding Butter | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 373.0 | 357.0 | 359.0 | 356.0 | 341.0 | 385.0 | 418.0 | 457.0 | 426 | 451 |
| 21473 | ZW | 181 | Zimbabwe | 2960 | Fish, Seafood | 5521 | Feed | 1000 tonnes | -19.02 | 29.15 | … | 5.0 | 4.0 | 9.0 | 6.0 | 9.0 | 5.0 | 15.0 | 15.0 | 15 | 15 |
| 21474 | ZW | 181 | Zimbabwe | 2960 | Fish, Seafood | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 18.0 | 14.0 | 17.0 | 14.0 | 15.0 | 18.0 | 29.0 | 40.0 | 40 | 40 |
| 21475 | ZW | 181 | Zimbabwe | 2961 | Aquatic Products, Other | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 |
| 21476 | ZW | 181 | Zimbabwe | 2928 | Miscellaneous | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 |
5 rows × 63 columns
data.tail(10)
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21467 | ZW | 181 | Zimbabwe | 2943 | Meat | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 222.0 | 228.0 | 233.0 | 238.0 | 242.0 | 265.0 | 262.0 | 277.0 | 280 | 258 |
| 21468 | ZW | 181 | Zimbabwe | 2945 | Offals | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 20.0 | 20.0 | 21.0 | 21.0 | 21.0 | 21.0 | 21.0 | 21.0 | 22 | 22 |
| 21469 | ZW | 181 | Zimbabwe | 2946 | Animal fats | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 26.0 | 26.0 | 29.0 | 29.0 | 27.0 | 31.0 | 30.0 | 25.0 | 26 | 20 |
| 21470 | ZW | 181 | Zimbabwe | 2949 | Eggs | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 15.0 | 18.0 | 18.0 | 21.0 | 22.0 | 27.0 | 27.0 | 24.0 | 24 | 25 |
| 21471 | ZW | 181 | Zimbabwe | 2948 | Milk - Excluding Butter | 5521 | Feed | 1000 tonnes | -19.02 | 29.15 | … | 21.0 | 21.0 | 21.0 | 21.0 | 21.0 | 23.0 | 25.0 | 25.0 | 30 | 31 |
| 21472 | ZW | 181 | Zimbabwe | 2948 | Milk - Excluding Butter | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 373.0 | 357.0 | 359.0 | 356.0 | 341.0 | 385.0 | 418.0 | 457.0 | 426 | 451 |
| 21473 | ZW | 181 | Zimbabwe | 2960 | Fish, Seafood | 5521 | Feed | 1000 tonnes | -19.02 | 29.15 | … | 5.0 | 4.0 | 9.0 | 6.0 | 9.0 | 5.0 | 15.0 | 15.0 | 15 | 15 |
| 21474 | ZW | 181 | Zimbabwe | 2960 | Fish, Seafood | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 18.0 | 14.0 | 17.0 | 14.0 | 15.0 | 18.0 | 29.0 | 40.0 | 40 | 40 |
| 21475 | ZW | 181 | Zimbabwe | 2961 | Aquatic Products, Other | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 |
| 21476 | ZW | 181 | Zimbabwe | 2928 | Miscellaneous | 5142 | Food | 1000 tonnes | -19.02 | 29.15 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 |
10 rows × 63 columns
列的数据类型(dtypes)
许多 DataFrame 都有混合数据类型,也就是说,有些列是数字,有些是字符串,有些是日期等。在内部,csv 文件不包含每列中包含哪些数据类型的信息;所有数据都只是字符。pandas 在加载数据时推断数据类型,例如,如果列只包含数字,则 pandas 会将该列的数据类型设置为 numeric:integer 或者 float。
你可以使用数据框的 .dtypes 属性来检查示例中每列的类型。
data.dtypes
Area Abbreviation object
Area Code int64
Area object
Item Code int64
Item object
Element Code int64
Element object
Unit object
latitude float64
longitude float64
Y1961 float64
Y1962 float64
Y1963 float64
Y1964 float64
Y1965 float64
Y1966 float64
Y1967 float64
Y1968 float64
Y1969 float64
Y1970 float64
Y1971 float64
Y1972 float64
Y1973 float64
Y1974 float64
Y1975 float64
Y1976 float64
Y1977 float64
Y1978 float64
Y1979 float64
Y1980 float64
....
在某些情况下,自动推断数据类型可能会产生意外结果。请注意,字符串作为“对象”数据类型加载,要更改特定列的数据类型,请使用 .astype() 函数。例如,要将 “项目代码” 列视为字符串,请使用:
data['Item Code'].astype(str)
使用 .describe() 描述数据
最后,要查看有关特定列的一些核心统计信息,我们可以使用 describe() 函数。
- 对于数字列,describe() 返回基本统计信息:列中数据的值计数,平均值,标准差,最小值,最大值以及第 25,第 50和第75的中位数;
- 对于字符串列,describe() 返回值计数,唯一条目数,最常出现的值(top value) 以及最高值出现的次数(freq);
利用 [] 选择要进行描述的列,并调用 describe() ,如下所示:
data['Y2013'].describe()
count 21477.000000
mean 575.557480
std 6218.379479
min -246.000000
25% 0.000000
50% 8.000000
75% 90.000000
max 489299.000000
Name: Y2013, dtype: float64
data['Area'].describe()
count 21477
unique 174
top Spain
freq 150
Name: Area, dtype: object
使用 describe() 函数获取 DataFrame 中列的基本统计信息。请注意具有 numeric 数据类型的列与字符串和字符列之间的差异。
请注意,如果在整个 DataFrame 上调用 describe,则仅返回具有 numeric 数据类型的列的统计信息,并返回 DataFrame 格式。
data.describe()
| Area Code | Item Code | Element Code | latitude | longitude | Y1961 | Y1962 | Y1963 | Y1964 | Y1965 | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 21477.000000 | 21477.000000 | 21477.000000 | 21477.000000 | 21477.000000 | 17938.000000 | 17938.000000 | 17938.000000 | 17938.000000 | 17938.000000 | … | 21128.000000 | 21128.000000 | 21373.000000 | 21373.000000 | 21373.000000 | 21373.000000 | 21373.000000 | 21373.000000 | 21477.000000 | 21477.000000 |
| mean | 125.449411 | 2694.211529 | 5211.687154 | 20.450613 | 15.794445 | 195.262069 | 200.782250 | 205.464600 | 209.925577 | 217.556751 | … | 486.690742 | 493.153256 | 496.319328 | 508.482104 | 522.844898 | 524.581996 | 535.492069 | 553.399242 | 560.569214 | 575.557480 |
| std | 72.868149 | 148.973406 | 146.820079 | 24.628336 | 66.012104 | 1864.124336 | 1884.265591 | 1861.174739 | 1862.000116 | 2014.934333 | … | 5001.782008 | 5100.057036 | 5134.819373 | 5298.939807 | 5496.697513 | 5545.939303 | 5721.089425 | 5883.071604 | 6047.950804 | 6218.379479 |
| min | 1.000000 | 2511.000000 | 5142.000000 | -40.900000 | -172.100000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -169.000000 | -246.000000 |
| 25% | 63.000000 | 2561.000000 | 5142.000000 | 6.430000 | -11.780000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | … | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 120.000000 | 2640.000000 | 5142.000000 | 20.590000 | 19.150000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | … | 6.000000 | 6.000000 | 7.000000 | 7.000000 | 7.000000 | 7.000000 | 7.000000 | 8.000000 | 8.000000 | 8.000000 |
| 75% | 188.000000 | 2782.000000 | 5142.000000 | 41.150000 | 46.870000 | 21.000000 | 22.000000 | 23.000000 | 24.000000 | 25.000000 | … | 75.000000 | 77.000000 | 78.000000 | 80.000000 | 82.000000 | 83.000000 | 83.000000 | 86.000000 | 88.000000 | 90.000000 |
| max | 276.000000 | 2961.000000 | 5521.000000 | 64.960000 | 179.410000 | 112227.000000 | 109130.000000 | 106356.000000 | 104234.000000 | 119378.000000 | … | 360767.000000 | 373694.000000 | 388100.000000 | 402975.000000 | 425537.000000 | 434724.000000 | 451838.000000 | 462696.000000 | 479028.000000 | 489299.000000 |
8 rows × 58 columns
describe() 最后返回的是一个统计信息,格式是另一个 DataFrame 。
选择和操作数据
pandas 的数据选择方法非常灵活。在本文章中,我们来查看列和行的基本操作。
选择列
在 pandas 中选择列有三种主要方式:
- 使用点符号,例如,data.column_name;
- 使用方括号和列的名称作为字符串,例如 data[‘column_name’];
- 使用数字索引和 iloc 选择器 data.iloc[:,
];
data.Area.head()
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
Name: Area, dtype: object
data['Area'].head()
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
Name: Area, dtype: object
data.iloc[:,2].head()
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
Name: Area, dtype: object
使用任何这些方法选择列时,最后生成的都是 Series 数据类型。pandas Series 是一维数据结构。了解可以对这些 Series 数据执行的基本操作是非常有用的,包括求和( .sum() ),求平均值( .mean() ),计数( .count() ),得到中位数( .median() ),并替换缺失值( .fillna(new_value) )。
[data['Y2007'].sum(), # Total sum of the column values
data['Y2007'].mean(), # Mean of the column values
data['Y2007'].median(), # Median of the column values
data['Y2007'].nunique(), # Number of unique entries
data['Y2007'].max(), # Maximum of the column values
data['Y2007'].min()] # Minimum of the column values
[10867788.0, 508.48210358863986, 7.0, 1994, 402975.0, 0.0]
同时选择多个列会从现有 DataFrame 中提取新的 DataFrame 。要选择多列,语法为:
- 带有列名列表的方括号选择,例如:data[ [ ‘column_name_1’, ‘column_name_2’ ] ];
- 使用带有 iloc 选择器的数字索引和列号列表,例如:data.iloc[:, [0,1,3,4]];
data[['Area Code', 'Area']].head()
| Area Code | Area | |
|---|---|---|
| 0 | 2 | Afghanistan |
| 1 | 2 | Afghanistan |
| 2 | 2 | Afghanistan |
| 3 | 2 | Afghanistan |
| 4 | 2 | Afghanistan |
data.iloc[:,[1,2]].head()
| Area Code | Area | |
|---|---|---|
| 0 | 2 | Afghanistan |
| 1 | 2 | Afghanistan |
| 2 | 2 | Afghanistan |
| 3 | 2 | Afghanistan |
| 4 | 2 | Afghanistan |
选择行
通常使用 iloc / loc 选择方法或使用逻辑选择器(基于另一列或者变量的值进行选择)来选择 DataFrame 中的行。以下是一些基本选择行的方式:
- 使用 iloc 选择器进行数字选择,例如 data.iloc[0:10, : ] ,这就能选择前 10 行;
- 使用 loc 选择器进行基于标签的行选择,例如 data.loc[2, : ];
- 使用评估语句的基于逻辑的行选择,例如 data[ data[ “Area” ] == “Ireland” ] 选择 Area 值为 Ireland 的行;
data.iloc[[1,2], : ].head()
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | AF | 2 | Afghanistan | 2805 | Rice (Milled Equivalent) | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 419.0 | 445.0 | 546.0 | 455.0 | 490.0 | 415.0 | 442.0 | 476.0 | 425 | 422 |
| 2 | AF | 2 | Afghanistan | 2513 | Barley and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 58.0 | 236.0 | 262.0 | 263.0 | 230.0 | 379.0 | 315.0 | 203.0 | 367 | 360 |
2 rows × 63 columns
data.loc[2, : ]
Area Abbreviation AF
Area Code 2
Area Afghanistan
Item Code 2513
Item Barley and products
Element Code 5521
Element Feed
Unit 1000 tonnes
latitude 33.94
longitude 67.71
Y1961 76
....
data[ data["Area"] == 'Ireland' ].head()
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9533 | IE | 104 | Ireland | 2511 | Wheat and products | 5521 | Feed | 1000 tonnes | 53.41 | -8.24 | … | 968.0 | 976.0 | 902.0 | 685.0 | 1063.0 | 804.0 | 783.0 | 760.0 | 650 | 600 |
| 9534 | IE | 104 | Ireland | 2511 | Wheat and products | 5142 | Food | 1000 tonnes | 53.41 | -8.24 | … | 395.0 | 423.0 | 501.0 | 449.0 | 470.0 | 493.0 | 512.0 | 502.0 | 494 | 500 |
| 9535 | IE | 104 | Ireland | 2805 | Rice (Milled Equivalent) | 5521 | Feed | 1000 tonnes | 53.41 | -8.24 | … | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 | 4.0 | 4.0 | 4.0 | 4 | 4 |
| 9536 | IE | 104 | Ireland | 2805 | Rice (Milled Equivalent) | 5142 | Food | 1000 tonnes | 53.41 | -8.24 | … | 11.0 | 6.0 | 6.0 | 9.0 | 14.0 | 15.0 | 16.0 | 14.0 | 14 | 14 |
| 9537 | IE | 104 | Ireland | 2513 | Barley and products | 5521 | Feed | 1000 tonnes | 53.41 | -8.24 | … | 993.0 | 908.0 | 1047.0 | 904.0 | 1242.0 | 1290.0 | 1283.0 | 1182.0 | 1146 | 1380 |
5 rows × 63 columns
我们可以灵活使用多种方式对行和列的组合选择,以实现对数据的操作。
删除行和列(drop)
要从 DataFrame 中删除行和列,pandas 给我们准备了 drop 函数。
要删除一列或者多列,请使用列的名称,并且将轴(axis)指定为 1。或者,如下面的例子所示,在 pandas 中添加了 “columns” 参数,从而不需要指定轴。drop 函数返回的是一个新的 DataFrame,并且删除了列。如果你需要编辑原始 DataFrame,可以将 inplace 参数设置为 True,并且没有返回值。
# Deleting columns
# Delete the "Area" column from the dataframe
data = data.drop("Area", axis=1)
# alternatively, delete columns using the columns parameter of drop
data = data.drop(columns="area")
# Delete the Area column from the dataframe in place
# Note that the original 'data' object is changed when inplace=True
data.drop("Area", axis=1, inplace=True).
# Delete multiple columns from the dataframe
data = data.drop(["Y2001", "Y2002", "Y2003"], axis=1)
也可以使用 drop 函数删除行,方法是指定 axis = 0。drop() 根据标签删除行,而不是数字索引,要根据数字位置 / 索引删除行,请使用 iloc 重新分配数据框值,如下所示:
data.head(3)
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AF | 2 | Afghanistan | 2511 | Wheat and products | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 3249.0 | 3486.0 | 3704.0 | 4164.0 | 4252.0 | 4538.0 | 4605.0 | 4711.0 | 4810 | 4895 |
| 1 | AF | 2 | Afghanistan | 2805 | Rice (Milled Equivalent) | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 419.0 | 445.0 | 546.0 | 455.0 | 490.0 | 415.0 | 442.0 | 476.0 | 425 | 422 |
| 2 | AF | 2 | Afghanistan | 2513 | Barley and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 58.0 | 236.0 | 262.0 | 263.0 | 230.0 | 379.0 | 315.0 | 203.0 | 367 | 360 |
3 rows × 63 columns
data.drop([0,1], axis=0).head(3)
| Area Abbreviation | Area Code | Area | Item Code | Item | Element Code | Element | Unit | latitude | longitude | … | Y2004 | Y2005 | Y2006 | Y2007 | Y2008 | Y2009 | Y2010 | Y2011 | Y2012 | Y2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | AF | 2 | Afghanistan | 2513 | Barley and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 58.0 | 236.0 | 262.0 | 263.0 | 230.0 | 379.0 | 315.0 | 203.0 | 367 | 360 |
| 3 | AF | 2 | Afghanistan | 2513 | Barley and products | 5142 | Food | 1000 tonnes | 33.94 | 67.71 | … | 185.0 | 43.0 | 44.0 | 48.0 | 62.0 | 55.0 | 60.0 | 72.0 | 78 | 89 |
| 4 | AF | 2 | Afghanistan | 2514 | Maize and products | 5521 | Feed | 1000 tonnes | 33.94 | 67.71 | … | 120.0 | 208.0 | 233.0 | 249.0 | 247.0 | 195.0 | 178.0 | 191.0 | 200 | 200 |
3 rows × 63 columns
Pandas 中的 drop() 函数用于从 DataFrame 中删除行,轴设置为 0。如前所述,inplace 参数可用于更改 DataFrame 而无需重新分配。
# Delete the rows with labels 0,1,5
data = data.drop([0,1,2], axis=0)
# Delete the rows with label "Ireland"
# For label-based deletion, set the index first on the dataframe:
data = data.set_index("Area")
data = data.drop("Ireland", axis=0). # Delete all rows with label "Ireland"
# Delete the first five rows using iloc selector
data = data.iloc[5:,]
重命名列
使用 DataFrame 重命名功能可以在 pandas 中轻松实现列重命名。重命名功能易于使用,而且非常灵活。以这两种方式重命名列:
- 通过使用字典将旧名称映射到新名称进行重命名,格式为 {“old_column_name”: “new_column_name”, …};
- 通过提供更改列名称的函数重命名。函数应用于每个列名称。
# Rename columns using a dictionary to map values
# Rename the Area columnn to 'place_name'
data = data.rename(columns={"Area": "place_name"})
# Again, the inplace parameter will change the dataframe without assignment
data.rename(columns={"Area": "place_name"}, inplace=True)
# Rename multiple columns in one go with a larger dictionary
data.rename(
columns={
"Area": "place_name",
"Y2001": "year_2001"
},
inplace=True
)
# Rename all columns using a function, e.g. convert all column names to lower case:
data.rename(columns=str.lower)
在许多情况下,我使用列名称的整理函数来确保变量名称的标准 camel-case 格式。从可能非结构化数据集加载数据时,使用 lambda 函数删除空格和小写所有列名称会很有用:
# Quickly lowercase and camelcase all column names in a DataFrame
data = pd.read_csv("/path/to/csv/file.csv")
data.rename(columns=lambda x: x.lower().replace(' ', '_'))
导出和保存 pandas DataFrame
在操作或者计算之后,下一步是将数据保存回 csv 文件,pandas 中的数据输出就像加载数据一样简单。
你只需要知道两个函数:第一个 to_csv 函数将 DataFrame 写入 csv 文件,to_excel 函数将 DataFrame 信息写入 Microsoft Excel 文件。
# Output data to a CSV file
# Typically, I don't want row numbers in my output file, hence index=False.
# To avoid character issues, I typically use utf8 encoding for input/output.
data.to_csv("output_filename.csv", index=False, encoding='utf8')
# Output data to an Excel file.
# For the excel output to work, you may need to install the "xlsxwriter" package.
data.to_csv("output_excel_file.xlsx", sheet_name="Sheet 1", index=False)
其他有用的函数功能
数据分组和聚合
加载数据之后,你需要将其按一个或另一个值分组,然后运行一些计算。这个我们会在后续文章 中介绍。
绘制 pandas DataFrame —— 条形图和线条
pandas 内置了一个相对广泛的绘图功能,可用于初步图形化探索 —— 尤其是当你使用 Jupyter 进行数据分析。
你需要安装 matplotlib 绘图包以生成图形,并且导入 matplotlib.pyplot 作为 plt,以便为图标添加图形标签和轴标签。pandas 原生的 plot() 命令提供了大量功能。
import matplotlib.pyplot as plt
data['latitude'].plot(kind='hist', bins=100)
plt.xlabel('Latitude Value')
plt.show()

plot_data = data[data["Element"] == 'Food']
plot_data = plot_data.groupby('Area')['Y2013'].sum()
plot_data.sort_values()[-10:].plot(kind='bar')
plt.title("Top Ten Food Producers")
plt.ylabel("Food produced (tonnes)")
plt.show()
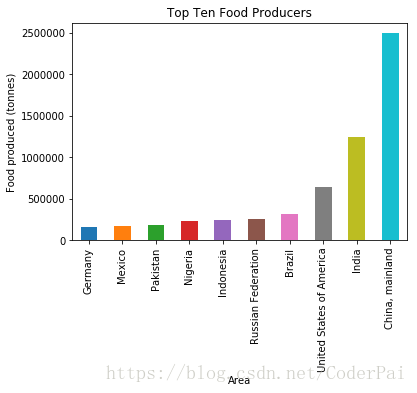
使用 pandas DataFrame 绘图命令,结合数据分析,数据分组和最终绘图。