pandas系列学习(四):数据提取
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
pandas系列学习(一):pandas入门
pandas系列学习(二):Series
pandas系列学习(三):DataFrame
pandas系列学习(四):数据提取
pandas 数据选择
有多种方法可以从 pandas DataFrame 中选择和索引行列。在这篇文章中,我们来讲一些高级的提取数据方法。
选择方式
在 pandas 中实现选择和索引的有三个主要选项,这可能会令人困惑。本文涉及的三个选择案例和方法是:
- 按照行号选择数据
.iloc; - 按照标签或者条件状态
.loc选择数据; - 选择混合方法
.ix,但是这个方法在 0.20.1 之后的版本就不在使用了;
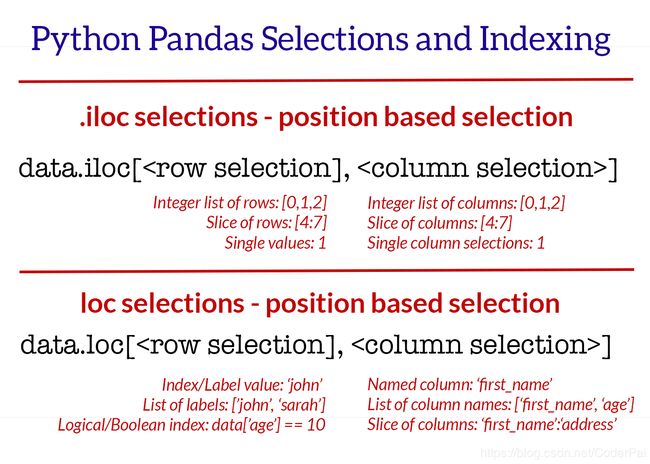
DataFrame 的选择和索引方法
对于这些探索,我们需要一些示例数据,我从 www.briandunning.com 下载了 uk-500 样本数据集。此数据包含虚拟英国字符的人工名称,地址,公司和电话号码。还要继续,你可以点击此处下载 csv 文件。按如下方式加载数据:
import pandas as pd
import random
# read the data from the downloaded CSV file.
data = pd.read_csv('https://s3-eu-west-1.amazonaws.com/shanebucket/downloads/uk-500.csv')
# set a numeric id for use as an index for examples.
data['id'] = [random.randint(0,1000) for x in range(data.shape[0])]
data.head(5)
| first_name | last_name | company_name | address | city | county | postal | phone1 | phone2 | web | id | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Aleshia | Tomkiewicz | Alan D Rosenburg Cpa Pc | 14 Taylor St | St. Stephens Ward | Kent | CT2 7PP | 01835-703597 | 01944-369967 | [email protected] | http://www.alandrosenburgcpapc.co.uk | 217 |
| 1 | Evan | Zigomalas | Cap Gemini America | 5 Binney St | Abbey Ward | Buckinghamshire | HP11 2AX | 01937-864715 | 01714-737668 | [email protected] | http://www.capgeminiamerica.co.uk | 919 |
| 2 | France | Andrade | Elliott, John W Esq | 8 Moor Place | East Southbourne and Tuckton W | Bournemouth | BH6 3BE | 01347-368222 | 01935-821636 | [email protected] | http://www.elliottjohnwesq.co.uk | 222 |
| 3 | Ulysses | Mcwalters | Mcmahan, Ben L | 505 Exeter Rd | Hawerby cum Beesby | Lincolnshire | DN36 5RP | 01912-771311 | 01302-601380 | [email protected] | http://www.mcmahanbenl.co.uk | 269 |
| 4 | Tyisha | Veness | Champagne Room | 5396 Forth Street | Greets Green and Lyng Ward | West Midlands | B70 9DT | 01547-429341 | 01290-367248 | [email protected] | http://www.champagneroom.co.uk | 878 |
1. 使用 iloc 选择 pandas 数据
pandas DataFrame 的 iloc 索引器用于按位置进行基于整数位置的索引或者选择。
iloc 索引器语法是 data.iloc [row selection, column selection] ,pandas 中的 iloc 用于按照数字选择行和列,按照它们在数据框中的显示顺序。你可以想象每行的行号从 0 到总行数(data.shape[0]),而 iloc[0] 允许根据这些数字进行选择。选择列也是同理的,范围从 0 到 data.shape[1] 。
iloc 有两个参数,一个行选择器和一个列选择器。例如:
# Single selections using iloc and DataFrame
# Rows:
data.iloc[0] # first row of data frame (Aleshia Tomkiewicz) - Note a Series data type output.
data.iloc[1] # second row of data frame (Evan Zigomalas)
data.iloc[-1] # last row of data frame (Mi Richan)
# Columns:
data.iloc[:,0] # first column of data frame (first_name)
data.iloc[:,1] # second column of data frame (last_name)
data.iloc[:,-1] # last column of data frame (id)
我们还可以使用 .iloc 选择器来选择多个列和行。
# Multiple row and column selections using iloc and DataFrame
data.iloc[0:5] # first five rows of dataframe
data.iloc[:, 0:2] # first two columns of data frame with all rows
data.iloc[[0,3,6,24], [0,5,6]] # 1st, 4th, 7th, 25th row + 1st 6th 7th columns.
data.iloc[0:5, 5:8] # first 5 rows and 5th, 6th, 7th columns of data frame (county -> phone1).
以这种方式使用 iloc 时要记住两个问题:
1.请注意,.iloc 在选择一行时返回的也是一个 pandas Series,在选择多行时返回 pandas DataFrame,或者如果选择了任何完整列。要解决此问题,请在需要 DataFrame 输出时传递单值列表。
print(type(data.iloc[100])) # result of type series because only one row selected.
print(type(data.iloc[[100]])) # result of type DataFrame because list selection used.
print(type(data.iloc[2:10])) # result of type dataframe sinc there are two rows selected.
print(type(data.iloc[1:2, 3])) # Series result because only one column selected.
print(type(data.iloc[1:2, [3]])) # DataFrame result with one column be only one column selected.
print(type(data.iloc[1:2, 3:6])) # DataFrame results because multiple columns and multiple rows.
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
2.当以这种方式选择多列或者多行时,请记住在你的选择中,例如 [1:5],所选的行或者列将从第一个数字到第二个数字减去 1。例如 [1:5] 将是1,2,3,4。
在实际的数据处理过程中,我很少使用 iloc 索引器,除非我想要数据帧的第一行( .iloc[0] )或最后一行( .iloc[-1] )。
2. 使用 loc 选择 pandas 数据
pandas loc 索引器可以与 DataFrame 一起用于两种不同的用例:
- 按照标签或者索引进行选择行;
- 按照布尔或者条件进行选择行;
loc 索引器的使用方法与 iloc 相同:data.loc [, ] 。
2a. 使用 .loc 进行基于标签或者基于索引的方法
使用 loc 方法的选择基于数据帧的索引(如果有的话)。我们还可以使用 df.set_index() 在 DataFrame 上设置索引的位置,.loc 方法直接根据任何行的索引值进行选择。例如,将测试数据的索引设置为人员的 last_name 。
data.set_index("last_name", inplace=True)
data.head()
| first_name | company_name | address | city | county | postal | phone1 | phone2 | web | id | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| last_name | |||||||||||
| Tomkiewicz | Aleshia | Alan D Rosenburg Cpa Pc | 14 Taylor St | St. Stephens Ward | Kent | CT2 7PP | 01835-703597 | 01944-369967 | [email protected] | http://www.alandrosenburgcpapc.co.uk | 641 |
| Zigomalas | Evan | Cap Gemini America | 5 Binney St | Abbey Ward | Buckinghamshire | HP11 2AX | 01937-864715 | 01714-737668 | [email protected] | http://www.capgeminiamerica.co.uk | 452 |
| Andrade | France | Elliott, John W Esq | 8 Moor Place | East Southbourne and Tuckton W | Bournemouth | BH6 3BE | 01347-368222 | 01935-821636 | [email protected] | http://www.elliottjohnwesq.co.uk | 777 |
| Mcwalters | Ulysses | Mcmahan, Ben L | 505 Exeter Rd | Hawerby cum Beesby | Lincolnshire | DN36 5RP | 01912-771311 | 01302-601380 | [email protected] | http://www.mcmahanbenl.co.uk | 381 |
| Veness | Tyisha | Champagne Room | 5396 Forth Street | Greets Green and Lyng Ward | West Midlands | B70 9DT | 01547-429341 | 01290-367248 | [email protected] | http://www.champagneroom.co.uk | 878 |
现在使用索引集,我们可以使用 .loc[] 直接为不同的 last_name 值选择行 —— 单个或者多个。例如:
data.loc['Andrade']
first_name France
company_name Elliott, John W Esq
address 8 Moor Place
city East Southbourne and Tuckton W
county Bournemouth
postal BH6 3BE
phone1 01347-368222
phone2 01935-821636
email france.andrade@hotmail.com
web http://www.elliottjohnwesq.co.uk
id 222
Name: Andrade, dtype: object
data.loc[['Andrade', 'Veness']]
| first_name | company_name | address | city | county | postal | phone1 | phone2 | web | id | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| last_name | |||||||||||
| Andrade | France | Elliott, John W Esq | 8 Moor Place | East Southbourne and Tuckton W | Bournemouth | BH6 3BE | 01347-368222 | 01935-821636 | [email protected] | http://www.elliottjohnwesq.co.uk | 777 |
| Veness | Tyisha | Champagne Room | 5396 Forth Street | Greets Green and Lyng Ward | West Midlands | B70 9DT | 01547-429341 | 01290-367248 | [email protected] | http://www.champagneroom.co.uk | 878 |
使用带有 pandas 的 .loc 索引选择单行或者多行。请注意,第一个示例返回一个 Series,但是第二个示例返回的是一个 DataFrame 。你可以通过将单元素列表传递给 .loc 操作来实现单列 DataFrame 。
使用列的名称选择带 .loc 的列。在我的大多数数据工作中,通常我已经命令了列,并使用这些命名选择。
data.loc[['Andrade', 'Veness'], ['first_name', 'address', 'city']]
| first_name | address | city | |
|---|---|---|---|
| last_name | |||
| Andrade | France | 8 Moor Place | East Southbourne and Tuckton W |
| Veness | Tyisha | 5396 Forth Street | Greets Green and Lyng Ward |
使用 .loc 索引器时,列使用字符串列表或“:” 切片通过名称引用。
你可以选择索引标签的范围 —— 选择 data.loc[‘Bruch’:‘Julio’] 将返回 “Bruch” 和 “Julio” 的索引条目之间数据框中的所有行。以下实例现在应该有意义:
# Select rows with index values 'Andrade' and 'Veness', with all columns between 'city' and 'email'
data.loc[['Andrade', 'Veness'], 'city':'email']
# Select same rows, with just 'first_name', 'address' and 'city' columns
data.loc['Andrade':'Veness', ['first_name', 'address', 'city']]
# Change the index to be based on the 'id' column
data.set_index('id', inplace=True)
# select the row with 'id' = 487
data.loc[487]
请注意,在最后一个示例中,data.loc[487](索引值为 487 的行)不等于 data.iloc[487](数据中的第 487 行)。DataFrame 的索引可以是数字顺序,字符串等等。
2b. 使用 .loc 进行布尔值 / 逻辑索引
使用 data.loc[] 的布尔数组的条件选择是我最常用的方法。使用布尔索引或者逻辑选择,可以将数组或者 True/False 值传递给 .loc 索引器,以选择 Series 具有 True 值的行。
在大多数用例中,你将根据数据集中不同列的值进行选择。例如,语句 data[‘first_name’] == ‘Antonio’ 为 data 中的每一行生成一个带有 True/False 值的 pandas Series,其中 first_name 的值为 Antonio。这些类型的布尔数组可以直接传递给 .loc 索引器,如下所示:
data.loc[data['first_name'] == 'Antonio']
| first_name | company_name | address | city | county | postal | phone1 | phone2 | web | ||
|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||
| 221 | Antonio | Combs Sheetmetal | 353 Standish St #8264 | Little Parndon and Hare Street | Hertfordshire | CM20 2HT | 01559-403415 | 01388-777812 | [email protected] | http://www.combssheetmetal.co.uk |
| 427 | Antonio | Saint Thomas Creations | 425 Howley St | Gaer Community | Newport | NP20 3DE | 01463-409090 | 01242-318420 | [email protected] | http://www.saintthomascreations.co.uk |
| 827 | Antonio | Radisson Suite Hotel | 35 Elton St #3 | Ipplepen | Devon | TQ12 5LL | 01324-171614 | 01442-946357 | [email protected] | http://www.radissonsuitehotel.co.uk |
使用布尔 True / False Sereis 选择 pandas 数据框中的行 —— 选择名为 “Antonio” 的所有行。
和以前一样,可以将第二个参数传递给 .loc 以从数据框中选择特定列。同样,列由 loc 索引器的名称引用,可以是单个字符串,列表或者切片 “:”操作。
data.loc[data['first_name'] == 'Erasmo', ['company_name', 'email', 'phone1']]
| company_name | phone1 | ||
|---|---|---|---|
| id | |||
| 312 | Active Air Systems | [email protected] | 01492-454455 |
| 821 | Pan Optx | [email protected] | 01445-796544 |
| 532 | Martin Morrissey | [email protected] | 01507-386397 |
使用 loc 选择多个列可以通过将列名传递给 .loc[] 的第二个参数来实现。
请注意,在选择列时,如果仅选择了一列,则 .loc 运算符将返回一个 Series。对于单列 DataFrame,使用单元素列表来保留 DataFrame 格式,例如:
data.loc[data['first_name'] == 'Erasmo', 'email']
id
312 erasmo.talentino@hotmail.com
821 egath@hotmail.com
532 erasmo_rhea@hotmail.com
Name: email, dtype: object
data.loc[data['first_name'] == 'Erasmo', ['email']]
| id | |
| 312 | [email protected] |
| 821 | [email protected] |
| 532 | [email protected] |
为了更加清楚的认识 .loc 选项,可以做如下示例:
# Select rows with first name Antonio, # and all columns between 'city' and 'email'
data.loc[data['first_name'] == 'Antonio', 'city':'email']
# Select rows where the email column ends with 'hotmail.com', include all columns
data.loc[data['email'].str.endswith("hotmail.com")]
# Select rows with last_name equal to some values, all columns
data.loc[data['first_name'].isin(['France', 'Tyisha', 'Eric'])]
# Select rows with first name Antonio AND hotmail email addresses
data.loc[data['email'].str.endswith("gmail.com") & (data['first_name'] == 'Antonio')]
# select rows with id column between 100 and 200, and just return 'postal' and 'web' columns
data.loc[(data['id'] > 100) & (data['id'] <= 200), ['postal', 'web']]
# A lambda function that yields True/False values can also be used.
# Select rows where the company name has 4 words in it.
data.loc[data['company_name'].apply(lambda x: len(x.split(' ')) == 4)]
# Selections can be achieved outside of the main .loc for clarity:
# Form a separate variable with your selections:
idx = data['company_name'].apply(lambda x: len(x.split(' ')) == 4)
# Select only the True values in 'idx' and only the 3 columns specified:
data.loc[idx, ['email', 'first_name', 'company']]
3. 使用 ix 选择 pandas 数据
注意:在最新版本的 pandas 中,不推荐使用 ix 索引器。
ix [] 索引器是 .loc 和 .iloc 的混合体。通常,ix 是基于标签的,并且与 .loc 索引器一样。但是,.ix 还支持整数类型选择(如 .iloc),其中传递一个整数。这仅适用于 DataFrame 的索引不是基于整数的情况。ix 将接受 .loc 和 .iloc 的任何输入。
稍微复杂一些,我更喜欢明确使用 .loc 和 .iloc 来避免意外结果。
举个例子:
# ix indexing works just the same as .loc when passed strings
data.ix[['Andrade']] == data.loc[['Andrade']]
# ix indexing works the same as .iloc when passed integers.
data.ix[[33]] == data.iloc[[33]]
# ix only works in both modes when the index of the DataFrame is NOT an integer itself.
使用 .loc 在 DataFrame 中设置值
稍微更改语法,你实际上可以在选择的同一语句中更新DataFrame,并使用 .loc 索引器进行过滤。此特定模式允许你根据不同条件更新列中的值。设置操作不会复制数据框,而是编辑原始数据。
举个例子:
# Change the first name of all rows with an ID greater than 2000 to "John"
data.loc[data['id'] > 2000, "first_name"] = "John"
# Change the first name of all rows with an ID greater than 2000 to "John"
data.loc[data['id'] > 2000, "first_name"] = "John"