pandas系列学习(五):数据连接
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
pandas系列学习(一):pandas入门
pandas系列学习(二):Series
pandas系列学习(三):DataFrame
pandas系列学习(四):数据提取
pandas系列学习(五):数据连接
利用 Python 处理任何实际的数据时,你就需要将 pandas DataFrame 合并或者链接在一起来分析数据集,但是这个过程还是非常花费时间的,大约是 10 分钟。合并(merge)和连接(join)数据框 是任何有抱负的数据分析师需要掌握的核心过程。这篇文章介绍了合并和连接数据集的过程,即根据它们之间的公共列将两个数据集连接在一起。主要分为这些主题:
- 什么是两个数据帧的合并和连接?
- 什么是内合并,外合并,左合并,右合并?
- 如何合并具有不同公共列名称的两个数据帧?(left_on 和 right_on 语法)

示例数据
对于这篇文章,我从 KillBiller 应用程序和一些别的地方下载的数据,这些数据包含在三个 CSV 文件中:
- user_usage.csv: 第一个数据集包含用户每月移动使用情况统计信息;
- user_device.csv: 第二个数据集包含系统的单独 “使用” 的详细信息,包括日期和设备信息;
- android_devices.csv: 第三个数据集包含设备和制造商数据,其中列出了从Google获取的所有Android设备及其型号代码;
我们可以使用 pandas read_csv() 命令将这些 csv 文件作为 pandas DataFrame 加载到 pandas中,并使用 DataFrame head() 命令检查内容。
user_usage.head()
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | |
|---|---|---|---|---|
| 0 | 21.97 | 4.82 | 1557.33 | 22787 |
| 1 | 1710.08 | 136.88 | 7267.55 | 22788 |
| 2 | 1710.08 | 136.88 | 7267.55 | 22789 |
| 3 | 94.46 | 35.17 | 519.12 | 22790 |
| 4 | 71.59 | 79.26 | 1557.33 | 22792 |
来自 KillBiller 应用程序的示例使用信息,显示一部分用户的每月移动使用情况统计信息。
user_device.head()
| use_id | user_id | platform | platform_version | device | use_type_id | |
|---|---|---|---|---|---|---|
| 0 | 22782 | 26980 | ios | 10.2 | iPhone7,2 | 2 |
| 1 | 22783 | 29628 | android | 6.0 | Nexus 5 | 3 |
| 2 | 22784 | 28473 | android | 5.1 | SM-G903F | 1 |
| 3 | 22785 | 15200 | ios | 10.2 | iPhone7,2 | 3 |
| 4 | 22786 | 28239 | android | 6.0 | ONE E1003 | 1 |
来自 KillBiller 应用程序的用户信息,为 KillBiller 应用程序的各个 “用途” 提供设备和操作系统版本。
devices.head(10)
| Retail Branding | Marketing Name | Device | Model | |
|---|---|---|---|---|
| 0 | NaN | NaN | AD681H | Smartfren Andromax AD681H |
| 1 | NaN | NaN | FJL21 | FJL21 |
| 2 | NaN | NaN | T31 | Panasonic T31 |
| 3 | NaN | NaN | hws7721g | MediaPad 7 Youth 2 |
| 4 | 3Q | OC1020A | OC1020A | OC1020A |
| 5 | 7Eleven | IN265 | IN265 | IN265 |
| 6 | A.O.I. ELECTRONICS FACTORY | A.O.I. | TR10CS1_11 | TR10CS1 |
| 7 | AG Mobile | AG BOOST 2 | BOOST2 | E4010 |
| 8 | AG Mobile | AG Flair | AG_Flair | Flair |
| 9 | AG Mobile | AG Go Tab Access 2 | AG_Go_Tab_Access_2 | AG_Go_Tab_Access_2 |
Android 设备数据,包含所有具有制造商和型号详细信息的 Android 设备。
注意重要的样本数据集之间存在连接属性:user_usage 和 user_device 之间共享 use_id ,而 user_device 的 device 列和设备数据集的 Model 列包含公共代码。
举个例子
我们想知道不同设备之间用户的使用模式是否不同。例如,使用三星设备的用户使用通话时间是否比使用 LG 设备的用户多?考虑到这些数据集中的样本量较小,这是一个demo问题,但它是需要合并的完美示例。
我们希望形成一个单独的数据框,其中包含用户使用数字(每月呼叫,每月短信等)以及包含设备信息(模型,制造商等)的列。我们需要将我们的样本数据集进行合并(或者连接)到一个单独的数据集中进行分析。
合并 DataFrame
合并两个数据集是将两个数据集合并为一个数据集,并根据公共属性或者列对齐每个数据集的行的过程。
合并和连接着两个词在 pandas 和其他语言中相对可互换,即 SQL 和 R 。在 pandas 中,有单独的 merge 和 join 函数,两者都做类似的事情。
在这个场景中,我们需要执行两个步骤:
- 对于 user_usage 数据集中的每一行——创建一个包含 user_device 数据帧中的 device 代码的心裂。即对于第一行,use_id 为 22787,因此我们转到 user_devices 数据集,找到 use_id 22787,并复制 device 列中的值;
- 完成此操作后,我们将获取新设备列,并从设备数据集中找到相应的“零售品牌”和“模型”;
- 最后,我们可以查看使用的设备制造商对使用情况进行拆分和分组数据的不同统计数据。
我可以使用 for 循环吗?
是的,你可以为此任务编写 for 循环。第一个循环遍历 user_usage 数据集中的 use_id ,然后在 user_devices 中找到正确的元素。第二个 for 循环将为设备重复此过程。
但是,使用 for 循环比使用 pandas 合并功能要慢得多,也更冗长。所以,如果你遇到这种情况——不要使用 for 循环。
合并 user_usage 和 user_devices
让我们看看如何使用 merge 命令将 device 和 platform 列正确添加到 user_usage 数据帧。
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id')
result.head()
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | platform | device | |
|---|---|---|---|---|---|---|
| 0 | 21.97 | 4.82 | 1557.33 | 22787 | android | GT-I9505 |
| 1 | 1710.08 | 136.88 | 7267.55 | 22788 | android | SM-G930F |
| 2 | 1710.08 | 136.88 | 7267.55 | 22789 | android | SM-G930F |
| 3 | 94.46 | 35.17 | 519.12 | 22790 | android | D2303 |
| 4 | 71.59 | 79.26 | 1557.33 | 22792 | android | SM-G361F |
以上是基于公共列将 user usage 和 user devices 合并的结果。
从结果中,我们看到这个非常有效,而且很容易实现,那么 merge 命令做了一些什么呢?
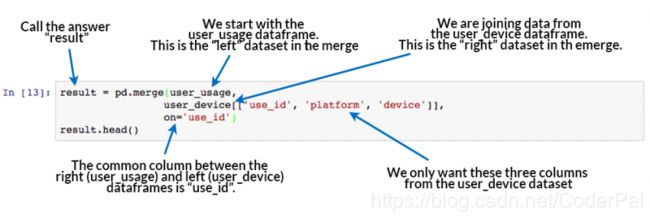
pandas merge 命令如何工作。至少,合并需要左数据集,右数据集和公共列以合并。
merge 命令是这篇文章的主要学习目标。最简单的合并操作采用左数据帧(第一个参数),右数据帧(第二个参数),然后是合并列名称,或合并 “on” 的列。在输出结果中,左侧和右侧数据帧中的行匹配,其中 “on” 指定的合并列的公共值。
有了这个结果,我们现在可以继续从 device 数据集中获取制造商和型号。但是,首先我们需要了解更多有关合并类型和输出数据帧大小的信息。
内部(inner),左侧(left)和右侧(right)合并类型
在上面的例子中,我们将 user_usage 和 user_devices 进行合并。利用 head() 查看结果发现非常棒,但是除此之外,我们还能获得更多的东西。首先,让我们看看 merge 命令的输入和输出的大小:
print("user_usage dimensions: {}".format(user_usage.shape))
print("user_device dimensions: {}".format(user_device[['use_id', 'platform', 'device']].shape))
print("result dimensions: {}".format(result.shape))
user_usage dimensions: (240, 4)
user_device dimensions: (272, 3)
result dimensions: (159, 6)
合并操作后数据集 result 的大小与预期不符合,即它的大小不是两个数据集大小之和。因为默认情况下, pandas merge() 默认为 inner 合并操作。内部合并(或内部连接)仅保留结果的左侧和右侧数据帧中的公共值。在上面的示例中,只有包含 user_usage 和 user_device 之间通用的 use_id 值的行扔保留在 result 数据集中。我们可以通过查看常见的值来验证这一点:
user_usage['use_id'].isin(user_device['use_id']).value_counts()
True 159
False 81
Name: use_id, dtype: int64
默认情况下,在 pandas 中仅保留左右数据帧之间的公共值,即我们使用了内部合并。
user_usage 中有 159 个 use_id 值出现在 user_device 中,这些值也出现在最终结果数据框 159 行中。
其他合并类型
pandas 中有三种不停类型的合并。这些合并类型在大多数数据库和面向数据的语言(SQL,R,SAS)中都很常见,通常称为 join 操作。如果你对合并操作不是很熟悉,可以看看下面的介绍:
- inner merge:默认的 pandas 行为,仅保留左侧和右侧数据框中存在合并 on 值的行;
- left merge:保留左数据框中的每一行。如果右侧数据框中存在 on 变量的缺失值,那么请在结果中添加 NaN 值;
- right merge:保留右数据框中的每一行。如果左侧数据框中存在 on 变量的缺失值,那么请在结果中添加 NaN 值;
- outer merge:完全外部连接返回左侧数据框中的所有行,右侧数据框中的所有行,并在可能额情况下匹配行,其他地方使用 NaN 值;
要使用的合并类型是使用 merge 命令中的 how 参数指定的,取值为 left,right,inner(默认值)或者 outer。具体可以看下图:
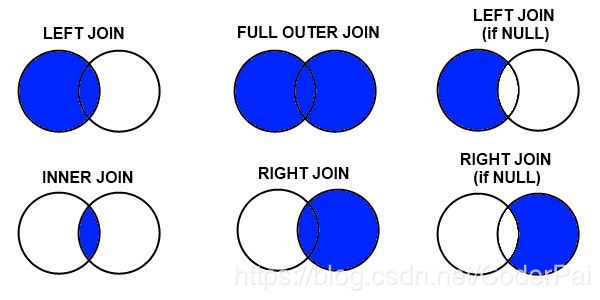
左合并例子
让我们重复我们的合并操作,但这次在 pandas 中执行 “左合并”。
- 最初,result 数据帧有 159 行,因为我们的左右数据帧之间共有 159 个 use_id 值,默认使用 inner 合并。
- 对于我们的左合并,我们期望 result 与我们的左数据帧 user_usage (240行)具有相同的行数,除了 159 个行是没有缺失值的,剩余 81 行都是有缺失值的;
- 我们希望 result 与左数据帧具有相同的行数,因为 user_usage 中的每个 use_id 在 user_device 中只出现一次。一对一的映射并非总是如此。在合并操作中,左侧数据框中的单行与右侧数据框中的多行匹配,将生成多个 result 行。即如果 user_usage 中的 use_id 值在 user_device 数据帧中出现两次,则在连接 result 中将有两行用于该 use_id 。
你可以使用 merge 命令的 how 参数将合并更改为 left merge。result 数据框的顶部包含成功匹配的项,而底部包含 user_usage 中的 user_device 中没有相应 use_id 的行。
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='left')
print("user_usage dimensions: {}".format(user_usage.shape))
print("result dimensions: {}".format(result.shape))
print("There are {} missing values in the result.".format(result['device'].isnull().sum()))
user_usage dimensions: (240, 4)
result dimensions: (240, 6)
There are 81 missing values in the result.
result.head()
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | platform | device | |
|---|---|---|---|---|---|---|
| 0 | 21.97 | 4.82 | 1557.33 | 22787 | android | GT-I9505 |
| 1 | 1710.08 | 136.88 | 7267.55 | 22788 | android | SM-G930F |
| 2 | 1710.08 | 136.88 | 7267.55 | 22789 | android | SM-G930F |
| 3 | 94.46 | 35.17 | 519.12 | 22790 | android | D2303 |
| 4 | 71.59 | 79.26 | 1557.33 | 22792 | android | SM-G361F |
result.tail()
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | platform | device | |
|---|---|---|---|---|---|---|
| 235 | 260.66 | 68.44 | 896.96 | 25008 | NaN | NaN |
| 236 | 97.12 | 36.50 | 2815.00 | 25040 | NaN | NaN |
| 237 | 355.93 | 12.37 | 6828.09 | 25046 | NaN | NaN |
| 238 | 632.06 | 120.46 | 1453.16 | 25058 | NaN | NaN |
| 239 | 488.70 | 906.92 | 3089.85 | 25220 | NaN | NaN |
在 pandas 中左连接示例。在 how 命令中指定连接类型。
右连接的例子
例如,我们可以使用右连接合并重复此过程,只需要在 pandas merge 命令中将 how
==left 替换成 how==right。
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='right')
预期结果将于正确的数据框 user_device 具有相同的行数,但是来源于左数据框中的数据就会具有多个空值或者 NaN 值。user_usage 中的 outgoing_mins_per_month,outgoing_sms_per_month 和 monthly_mb 会有空值,但是右侧数据框 user_device 中的列中没有缺失值。
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='right')
print("user_device dimensions: {}".format(user_device.shape))
print("result dimensions: {}".format(result.shape))
print("There are {} missing values in the 'monthly_mb' column in the result.".format(result['monthly_mb'].isnull().sum()))
print("There are {} missing values in the 'platform' column in the result.".format(result['platform'].isnull().sum()))
user_device dimensions: (272, 6)
result dimensions: (272, 6)
There are 113 missing values in the 'monthly_mb' column in the result.
There are 0 missing values in the 'platform' column in the result.
外部合并的例子
最后,我们将使用 pandas 执行外部合并,也称为 “完全外部连接” 或者 “外部连接”。外连接可以看做是左连接和右连接的组合,或者是内连接的相反。在外部连接中,左侧和右侧数据框中的每一行都会保留在结果中,其中 NaN 为没有匹配到的变量。
因此,我们希望 result 具有与 user_device 和 user_usage 之间的 use_id 的不同值相同的行数,即来自左数据帧的每个连接值将与来自右数据帧的每个值一起出现在 result 中。
print("There are {} unique values of use_id in our dataframes.".format(
pd.concat([user_usage['use_id'], user_device['use_id']]).unique().shape[0]))
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='outer')
print("Outer merge result has {} rows.".format(result.shape))
print("There are {} rows with no missing values.".format((result.apply(lambda x: x.isnull().sum(), axis=1) == 0).sum()))
There are 353 unique values of use_id in our dataframes.
Outer merge result has (353, 6) rows.
There are 159 rows with no missing values.
使用 pandas 的外部合并 result 。左侧和右侧数据帧中的每一行都保留在 result 中,缺少值为 NaN 值。
在下图中,显示了外部合并 result 中的示例行,前两个是 use_id 在数据帧之间最常见的示例,后两个仅来自左侧数据帧,最后两个仅来自右侧数据帧。
使用合并指示器跟踪合并
为了帮助识别行的来源,pandas 提供了一个指标参数,可以与 merge 函数一起使用,该函数在输出中创建一个名为 _merge 的附加列,用于标记每行的原始源。
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='outer',
indicator=True)
result.iloc[[0,1,2,200,201,202]]
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | platform | device | _merge | |
|---|---|---|---|---|---|---|---|
| 0 | 21.97 | 4.82 | 1557.33 | 22787 | android | GT-I9505 | both |
| 1 | 1710.08 | 136.88 | 7267.55 | 22788 | android | SM-G930F | both |
| 2 | 1710.08 | 136.88 | 7267.55 | 22789 | android | SM-G930F | both |
| 200 | 28.79 | 29.42 | 3114.67 | 23988 | NaN | NaN | left_only |
| 201 | 616.56 | 99.85 | 5414.14 | 24006 | NaN | NaN | left_only |
| 202 | 339.09 | 136.88 | 9854.79 | 24037 | NaN | NaN | left_only |
从上图的 _merge 字段我们就可以很清楚的看到每一行是来源于原始数据的左侧数据框还是右侧数据框。
最终合并——将设备详细信息加入到结果中
回到我们原来的问题,我们已经将 user_usage 与 user_device 合并,因此我们为每个用户提供了平台和设备。最初,我们在 pandas 中使用了 inner merge 作为默认值,因此,我们只为具有设备信息的用户提供条目。我们将使用左连接重做此合并以保留所有用户,然后使用第二个左合并最终使设备制造商处于同一数据帧中。
# First, add the platform and device to the user usage - use a left join this time.
result = pd.merge(user_usage,
user_device[['use_id', 'platform', 'device']],
on='use_id',
how='left')
# At this point, the platform and device columns are included
# in the result along with all columns from user_usage
# Now, based on the "device" column in result, match the "Model" column in devices.
devices.rename(columns={"Retail Branding": "manufacturer"}, inplace=True)
result = pd.merge(result,
devices[['manufacturer', 'Model']],
left_on='device',
right_on='Model',
how='left')
print(result.head())
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | platform | device | manufacturer | Model | |
|---|---|---|---|---|---|---|---|---|
| 0 | 21.97 | 4.82 | 1557.33 | 22787 | android | GT-I9505 | Samsung | GT-I9505 |
| 1 | 1710.08 | 136.88 | 7267.55 | 22788 | android | SM-G930F | Samsung | SM-G930F |
| 2 | 1710.08 | 136.88 | 7267.55 | 22789 | android | SM-G930F | Samsung | SM-G930F |
| 3 | 94.46 | 35.17 | 519.12 | 22790 | android | D2303 | Sony | D2303 |
| 4 | 71.59 | 79.26 | 1557.33 | 22792 | android | SM-G361F | Samsung | SM-G361F |
使用 left_on 和 right_on 与不同的列名合并
合并运算符中使用的列不需要在左侧和右侧数据帧中命名相同。在上面的第二个合并中,请注意设备 ID 在左侧数据帧中称为设备,在右侧数据帧中称为 模型。
使用 left_on 和 right_on 参数为 pandas 中的合并指定了不同的列名,而不是仅使用 on 参数。

根据设备计算统计数据
随着我们的合并完成,我们可以使用 pandas 的数据聚合功能来快速计算出基于设备制造商的用户的平均使用情况。请注意,小样本量会创建更小的组,因此我不会将这些特定结果归因于任何统计意义。
result.groupby("manufacturer").agg({
"outgoing_mins_per_month": "mean",
"outgoing_sms_per_month": "mean",
"monthly_mb": "mean",
"use_id": "count"
})
| outgoing_mins_per_month | outgoing_sms_per_month | monthly_mb | use_id | |
|---|---|---|---|---|
| manufacturer | ||||
| HTC | 244.302026 | 105.192099 | 2178.809982 | 548 |
| Huawei | 81.526667 | 9.500000 | 1561.226667 | 3 |
| LGE | 111.530000 | 12.760000 | 1557.330000 | 2 |
| Lava | 60.650000 | 261.900000 | 12458.670000 | 2 |
| Lenovo | 215.920000 | 12.930000 | 1557.330000 | 8 |
| Motorola | 91.092326 | 57.906628 | 3338.662326 | 172 |
| OnePlus | 416.341667 | 43.740000 | 3576.103333 | 18 |
| Samsung | 169.136728 | 87.165864 | 5085.595556 | 162 |
| Sony | 254.425000 | 42.611765 | 4351.370294 | 34 |
| Vodafone | 42.750000 | 46.830000 | 5191.120000 | 4 |
| ZTE | 42.750000 | 46.830000 | 5191.120000 | 4 |