如何解决难题?从计算两个日期之间的天数到A*算法实现
两个多月前我参加了Udacity的无人驾驶入门课程,里面有一个专题是关于如何解决难题的,在这里希望总结一下自己的收获和体会。文章的主要内容如下:
- 启发问题:如何计算两个日期之间的天数?
- 解决问题的思路
- 程序实现的过程
- 如何借助已有的成熟思路?
- 用python实现A*寻路算法
- 这次解决问题的思路是什么?
- 收获和体会
启发问题:如何计算两个日期之间的天数?
给定两个日期date_a和date_b(默认规定date_a是在时间上早于或者等于date_b,也没有时间穿越之类的特殊情况 :-P),请计算这两个日期之间的天数。
面对一个问题,第一步应该做的肯定是分析问题。如果理解上就出现了偏差,那么求解的过程一定是曲折的,而且基本上无法得到期望中的输出。
对于上述这个问题,我们可以得知:
输入:两个任意的日期,第一个日期应该要早于第二个日期(但是为了程序的严谨性,仍需要判断一下);
输出:一个表示天数的正整数。
要点:闰年和非闰年的一年总天数不同,因为对应的二月份其天数分别为29和28.
解决问题的思路
如果是由你用笔算来解决这个问题,你的计算过程是怎么样的呢?
这是一个很好的切入点,因为我们可以借鉴自己的计算过程,看是否能够把这个计算过程转变成程序写出来。比如说给定的两个日期分别是20151125和20170509,我们可能想到的是:
总天数 = 20151125到20151231的天数 + 20160101到20161231的天数 + 20170101到20170509的天数
又或者是:
总天数 = 20150101到20170509的天数 - 20150101到20151125的天数
计算过程中都需要判断哪一年是闰年,这个闰年的二月份是否包含在需要计算的日期里面,如果是按照这样类似的“人类思维”来编写程序,一定是能够实现的,但这对于计算机而言,是否是最优解呢?
我们都知道计算机最擅长的事情就是循环简单的动作,那么针对这个问题,我们是否可以让计算机从20151125开始,一天一天地数到20170509呢?
OK,我们来试一下。
程序实现的过程
1. 所需的函数
days_between_dates() : 计算两个日期之间的天数,返回一个正整数;
date_is_before() : 判断某一个日期是否在另一个日期之前,除了检验输入的两个日期的前后关系以后,还可以用于判断是否已经数到了第二个日期(此时需要结束数数的循环);
next_day() : 返回下一个日期;
is_leap_year() : 判断某一年是否是闰年
days_in_month() : 返回某一个月的天数;
2. 简化问题(关键所在)
从整体出发,一开始并不需要考虑哪一年是闰年,哪个月多少天,我们可以简化为假设每个月都是30天(令函数days_in_month()直接return 30),如果计算结果正确,那么再往下走,完善days_in_month()函数返回具体每个月多少天就可以得到一个完整的解决方案了。
3. 完整代码如下
def is_leap_year(year):
if year % 4 == 0:
return True
else:
return False
def days_in_month(year, month):
leap_year = {1:31, 2:29, 3:31, 4:30, 5:31, 6:30, 7:31, 8:31, 9:30, 10:31, 11:30, 12:31}
not_leap_year = {1:31, 2:28, 3:31, 4:30, 5:31, 6:30, 7:31, 8:31, 9:30, 10:31, 11:30, 12:31}
days = 0
if is_leap_year(year):
days = leap_year[month]
else:
days = not_leap_year[month]
return days
def date_is_before(year1, month1, day1, year2, month2, day2):
"""
Returns True if year1-month1-day1 is before
year2-month2-day2. Otherwise, returns False.
"""
if year1 < year2:
return True
if year1 == year2:
if month1 < month2:
return True
if month1 == month2:
return day1 < day2
return False
def next_day(year, month, day):
if day < days_in_month(year, month):
day = day + 1
else:
day = 1
if month < 12:
month = month + 1
else:
month = 1
year = year + 1
return(year, month, day)
def days_between_dates(year1, month1, day1, year2, month2, day2):
"""
Calculates the number of days between two dates.
"""
assert not date_is_before(year2, month2, day2, year1, month1, day1)
days = 0
while date_is_before(year1, month1, day1, year2, month2, day2):
year1, month1, day1 = next_day(year1, month1, day1)
days += 1
return days如何借助已有的成熟思路?
计算两个日期之间的天数的问题,是从头开始,思考问题的解题思路,然后编码实现,但是面对已有最优解的问题,如果根据成熟的思路,编码实现呢?比如接下来的A*算法问题。
用python实现A*寻路算法
面对一个约束较多的问题,在具体实现上就要考虑所有的约束条件。(本次的实验环境是jupyter notebook)
给定的地图是以pickle文件的形式存储,已经写好函数提供地图上各点的坐标以及各个点之间的连接情况:
比如加载地图(40个点)并显示:
map_40 = load_map('map-40.pickle')
show_map(map_40)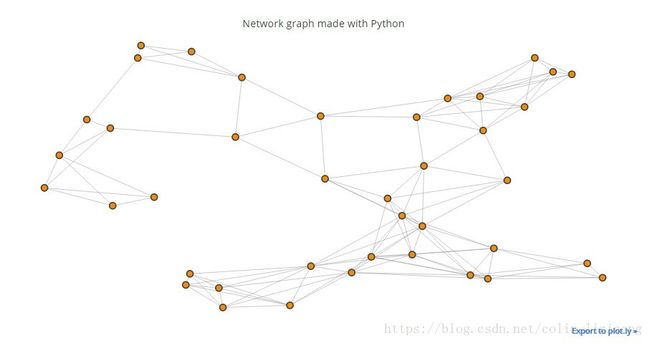
查看点的坐标,会返回一个字典(key是点的编号,value是点的坐标):
map_40.intersections查看点的链接情况(会返回一个二维数组,一维下标和点的编号是一一对应的,其值就是一个包含连接点的数组):
map_40.roads另外,实际距离与估算距离均采用两点之间的直线距离。
这次解决问题的思路是什么?
在算法/解题思路都已经确定的情况下,其实就是考虑使用什么样的数据结构来存储数据,才能达到方便调用的目的,从而避免在编码的过程中陷入“既要担心循环步骤又要考虑如何取数”的纠结境地。当然前提条件还是要把算法(这里是A*算法)的过程理解透彻。
整个A*算法最关键的地方是:
把frontier中 f 值最小的点移除(同时添加到explored中),对于与被移除的点相连接的每一个点都有:
1. 如果该点已经存在explored中,则不对其做任何操作;
2. 如果该点不在frontier中,则将其直接添加到frontier中;
3. 如果该点已经存在frontier中,则比较当前路径下与原路径下到达该点的 f 值的大小,如果当前路径下更小,则更新 f 值和父节点,否则不对其做任何操作。

在数据结构的选择上也是很关键的:
1. 用集合类型表示frontier和explored,查找速度快。
2. 用字典存储各个点的编号及其node数据类型(以提前定义node数据类型,存储的内容是父节点以及当前的实际消耗,即g值),形式如下:
{0: node(father, g),1:node(father, g), … , n:node(father, g)}
这样的好处有:
每次比较frontier或者explored中是否存在某个点时,可以直接用in或者not in来判断;并且,如果用node直接存放到集合中,每次更新g以后,对于判断是否是同一个点(此时也变为了判断是否是同一个node数据结构)很麻烦,而使用字典来绑定点的编号和其对应的node数据结构,则只需要判断字典的key值(点的编号)即可。
完整项目代码
from math import sqrt
## Calculate the distance between two points.
def distance(point1_x, point1_y, point2_x, point2_y):
return sqrt(pow((point1_x-point2_x), 2) + pow((point1_y-point2_y), 2))
## Calculate all the distances between two connected points.
def distance_list(M):
result_list = []
for i in range(len(M.roads)):
row = []
for j in M.roads[i]:
row.append(distance(M.intersections[i][0], M.intersections[i][1],
M.intersections[j][0], M.intersections[j][1]))
result_list.append(row)
return result_list
## Calculate the heuristic (estimated distance) for every point to the goal.
def heuristic(M, goal):
result_dict = {}
for key, value in M.intersections.items():
result_dict[key] = distance(value[0], value[1],
M.intersections[goal][0], M.intersections[goal][1])
return result_dict
## Define the structure of nodes
class node:
def __init__(self, parent, g):
self.parent = parent
self.g = g
## Initialize nodes
def node_dict(M):
node_dict = {}
for i in range(len(M.intersections)):
node_dict[i] = node(None, 0)
return node_dict
## Find the shortest path
def shortest_path(M,start,goal):
# Complete the map
map_roads = M.roads
dis_list = distance_list(M)
estimated_dict = heuristic(M, goal)
n_dict = node_dict(M)
# Initialize the frontier and the explored set
frontier = {start}
explored = set()
# Loop when frontier is not empty
while len(frontier) != 0:
# Calculate the value f for each node in frontier set
f_dict = {}
for node in frontier:
f_dict[node] = n_dict[node].g + estimated_dict[node]
# Select the node with the minimum f
node_with_min_f = [key for key, value in f_dict.items() if value == min(f_dict.values())][0]
# Remove this node from frontier set
frontier.remove(node_with_min_f)
# Add this node to explored set
explored.add(node_with_min_f)
# If reach the goal, break the loop
if goal in explored:
break
# Check nodes that connect with node_with_min_f
for node in map_roads[node_with_min_f]:
if node in explored:
continue
elif node not in frontier:
frontier.add(node)
n_dict[node].parent = node_with_min_f
n_dict[node].g = n_dict[node_with_min_f].g + dis_list[node_with_min_f][map_roads[node_with_min_f].index(node)]
else:
new_f = n_dict[node_with_min_f].g + dis_list[node_with_min_f][map_roads[node_with_min_f].index(node)] + estimated_dict[node]
if new_f < n_dict[n_dict[node].parent].g + dis_list[n_dict[node].parent][map_roads[n_dict[node].parent].index(node)] + estimated_dict[node]:
n_dict[node].parent = node_with_min_f
n_dict[node].g = new_f - estimated_dict[node]
# Generate the path
node = goal
reverse_path = []
path = []
while node != start:
reverse_path.append(node)
node = n_dict[node].parent
reverse_path.append(start)
path = reverse_path[::-1]
return path仅用于交流学习,如果感兴趣大家也可以参加该课程,其实能学到挺多东西的。
收获和体会
Udacity的这个无人驾驶入门课程,除了介绍入门知识以外,还在培养解决问题的思路上给了我挺大的帮助和启发。比如面对一个难题,千万不要慌张,细细分析,简化问题,整体流程能够跑通了再做细节的优化是一个很好的解体思路。但是这个思路不是固定不变的,如果问题已有成熟的解题思路,那么重点就应该放在数据结构上。
有了正确的思路,再用高效的数据结构表达,那么编码实现也就水到渠成了。