Storm(六):数据流的分流与合流
Storm 对数据处理时,不同的数据交给不同的bolt来处理,然后处理好的数据传给同个bolt来存储到数据库,这时就需要分流与合流,我们通过一个例子了解分流与合流。
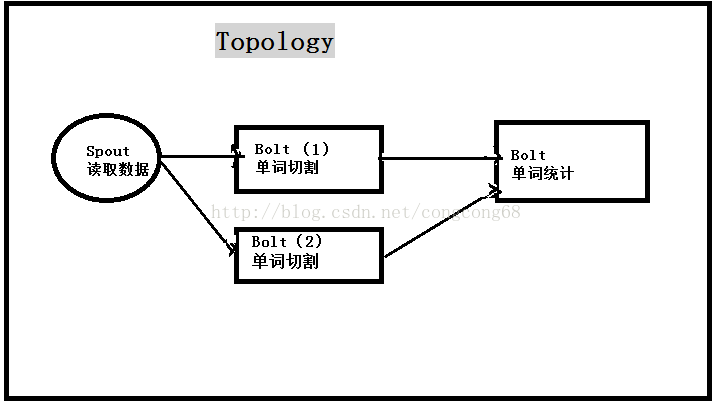
我们通过Spout读取文本,然后发送到第一个bolt对文本进行切割,如果是空格的发给bolt(1),如果是逗号组成的文本发给bolt(2),也就是分流,然后在对切割好单词把相同的单词发送给第二个bolt同一个task来统计(合流),这些过程可以利用多台服务器帮我们完成。
1、分流
1)主要Bolt中通过declareOutputFields先定义
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declareStream("streamId1", new Fields("field"));
declarer.declareStream("streamId2", new Fields("field"));
}
collector.emit("streamId1",new Values(value));
3)最后在构建拓扑时声明bolt对应的数据流ID
builder.setBolt("split1", new SplitSentence1Bolt(), 2).shuffleGrouping("spout","streamId1");
builder.setBolt("split2", new SplitSentence2Bolt(), 2).shuffleGrouping("spout","streamId2");
2、合流
在构建拓扑时声明bolt接收几个bolt就可以
builder.setBolt("count", new WordCountBolt(), 2).fieldsGrouping("split1", new Fields("word"))
.fieldsGrouping("split2", new Fields("word"));接下来我们来看整个例子:
第一步:创建spout数据源
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
/**
* 数据源
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = {
"Apache Storm is a free and open source distributed realtime computation system",
"Storm,makes,it,easy,to,reliably,process,unbounded,streams,of,data",
"doing for realtime processing what Hadoop did for batch processing",
"can,be,used,with,any,programming,language",
"and is a lot of fun to use" };
private int index = 0;
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declareStream("streamId1", new Fields("sentence"));
declarer.declareStream("streamId2", new Fields("sentence"));
}
@SuppressWarnings("rawtypes")
public void open(Map config, TopologyContext context,SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
if(index >= sentences.length){
return;
}
if(index%2==0){
collector.emit("streamId1",new Values(sentences[index]));
}else{
collector.emit("streamId2",new Values(sentences[index]));
}
index++;
Utils.sleep(1);
}
}
第二步:实现单词切割bolt1
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 切割句子
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class SplitSentence1Bolt extends BaseBasicBolt {
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
collector.emit(new Values(word));
}
}
}第三步:实现单词切割bolt2
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 切割句子
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class SplitSentence2Bolt extends BaseBasicBolt {
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(",");
for (String word : words) {
collector.emit(new Values(word));
}
}
}
第四步:对单词进行统计bolt
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
/**
* 统计单词
* @author zhengcy
*
*/
@SuppressWarnings("serial")
public class WordCountBolt extends BaseBasicBolt {
private Map counts = null;
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map stormConf, TopologyContext context) {
this.counts = new HashMap();
}
@Override
public void cleanup() {
for (String key : counts.keySet()) {
System.out.println(key + " : " + this.counts.get(key));
}
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String word = input.getStringByField("word");
Long count = this.counts.get(word);
if (count == null) {
count = 0L;
}
count++;
this.counts.put(word, count);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
} 第五步:创建Topology拓扑
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
/**
* 单词统计拓扑
* @author zhengcy
*
*/
public class WordCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new SentenceSpout(), 1);
builder.setBolt("split1", new SplitSentence1Bolt(), 2).shuffleGrouping("spout","streamId1");
builder.setBolt("split2", new SplitSentence2Bolt(), 2).shuffleGrouping("spout","streamId2");
builder.setBolt("count", new WordCountBolt(), 2).fieldsGrouping("split1", new Fields("word"))
.fieldsGrouping("split2", new Fields("word"));
Config conf = new Config();
conf.setDebug(false);
if (args != null && args.length > 0) {
// 集群模式
conf.setNumWorkers(2);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
// 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}