centos6.5安装Hadoop2.4.1(完全分布式)
1、集群部署介绍
1.1 网络环境
集群中包括2个节点:1个Master,1个Slave,节点之间局域网连接,可以相互ping通,节点IP地址分布如下:
| 机器名称 | IP地址 |
|---|---|
| Master.Hadoop | 192.168.1.2 |
| Salve1.Hadoop | 192.168.1.3 |
| Salve2.Hadoop | 192.168.1.4 |
两个节点上均是CentOS6.5系统,并且有一个相同的用户hadoop。Master机器主要配置NameNode,负责总管分布式数据和分解任务的执行;Salve机器配置DataNode,负责分布式数据存储以及任务的执行。
1.2 网络配置
下面的例子我们将以Master机器为例,即主机名为”Master.Hadoop”,IP为”192.168.1.2”进行一些主机名配置的相关操作。其他的Slave机器以此为依据进行修改。
1)查看当前机器名称
用下面命令进行显示机器名称,如果跟规划的不一致,要按照下面进行修改。
hostname
上图中,用”hostname”查”Master”机器的名字为”Master.Hadoop”,与我们预先规划的一致。
2)修改当前机器名称
假定我们发现我们的机器的主机名不是我们想要的,通过对”/etc/sysconfig/network”文件修改其中”HOSTNAME”后面的值,改成我们规划的名称。
这个”/etc/sysconfig/network”文件是定义hostname和是否利用网络的不接触网络设备的对系统全体定义的文件。
“/etc/sysconfig/network”的设定项目如下:
NETWORKING 是否利用网络
GATEWAY 默认网关
IPGATEWAYDEV 默认网关的接口名
HOSTNAME 主机名
DOMAIN 域名
用下面命令进行修改当前机器的主机名(备注:修改系统文件一般用root用户)从”/etc/sysconfig/network”中找到”HOSTNAME”进行修改,查看内容如下:

3)配置hosts文件(必须)
“/etc/hosts”这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName和IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名(或域名)对应的IP地址。
我们要测试两台机器之间知否连通,一般用”ping 机器的IP”,如果想用”ping 机器的主机名”发现找不见该名称的机器,解决的办法就是修改”/etc/hosts”这个文件,通过把LAN内的各主机的IP地址和HostName的一一对应写入这个文件的时候,就可以解决问题。
例如:机器为”Master.Hadoop:192.168.1.2”对机器为”Slave1.hadoop: 192.168.1.3”用命令”ping”记性连接测试。测试结果如下:

从上图中的值,直接对IP地址进行测试,能够ping通,但是对主机名进行测试,发现没有ping通,提示”unknown host——未知主机”,这时查看”Master.Hadoop”的”/etc/hosts”文件内容。

发现里面没有”192.168.1.3 Slave1.Hadoop”内容,故而本机器是无法对机器的主机名为”Slave1.Hadoop” 解析。
在进行Hadoop集群配置中,需要在”/etc/hosts”文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的”/etc/hosts”文件末尾中都要添加如下内容:
192.168.1.2 Master.Hadoop
192.168.1.3 Slave1.Hadoop
添加结果如下:

现在我们在进行对机器为”Slave1.Hadoop”的主机名进行ping通测试,看是否能测试成功。
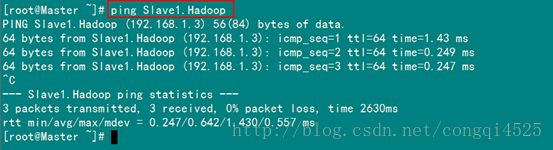
从上图中我们已经能用主机名进行ping通了,说明我们刚才添加的内容,在局域网内能进行DNS解析了,那么现在剩下的事儿就是在其余的Slave机器上进行相同的配置。然后进行测试。
1.3 系统环境
1) 操作系统:CentOS6.5
2) JDK:jdk_1.8.0
3) Hadoop版本:hadoop-2.4.1
2、SSH无密码验证配置
2.1 安装和启动SSH协议
我们需要两个服务:ssh和rsync已经安装了。可以通过下面命令查看结果显示如下:
rpm –qa | grep openssh
rpm –qa | grep rsync
假设没有安装ssh和rsync,可以通过下面命令进行安装。
yum install ssh 安装SSH协议
yum install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
service sshd restart 启动服务2.2 配置Master无密码登录所有Slave
1)SSH无密码原理
Master(NameNode )作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
2)Master机器上生成密码对
在Master节点上执行以下命令:
ssh-keygen –t rsa –P ''这条命令生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在”/home/hadoop/.ssh”目录下。

查看”/home/hadoop/”下是否有”.ssh”文件夹,且”.ssh”文件下是否有两个刚生产的无密码密钥对。

接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys在验证前,需要做两件事儿。第一件事儿是修改文件”authorized_keys”权限(权限的设置非常重要,因为不安全的设置安全设置,会让你不能使用RSA功能),另一件事儿是用root用户设置”/etc/ssh/sshd_config”的内容。使其无密码登录有效。
1)修改文件”authorized_keys”
chmod 600 ~/.ssh/authorized_keys
2)设置SSH配置
用root用户登录服务器修改SSH配置文件”/etc/ssh/sshd_config”的下列内容。
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
设置完之后记得重启SSH服务,才能使刚才设置有效。
service sshd restart退出root登录,使用hadoop普通用户验证是否成功。
ssh localhost
从上图中得知无密码登录本级已经设置完毕,接下来的事儿是把公钥复制所有的Slave机器上。使用下面的命令格式进行复制公钥:
scp ~/.ssh/id_rsa.pub 远程用户名@远程服务器IP:~/
例如:
scp ~/.ssh/id_rsa.pub hadoop@192.168.1.3:~/上面的命令是复制文件”id_rsa.pub”到服务器IP为”192.168.1.3”的用户为”hadoop”的”/home/hadoop/”下面。
下面就针对IP为”192.168.1.3”的Slave1.Hadoop的节点进行配置。
1)把Master.Hadoop上的公钥复制到Slave1.Hadoop上

从上图中我们得知,已经把文件”id_rsa.pub”传过去了,因为并没有建立起无密码连接,所以在连接时,仍然要提示输入输入Slave1.Hadoop服务器用户hadoop的密码。
2)追加到授权文件”authorized_keys”
到目前为止Master.Hadoop的公钥也有了,文件夹”.ssh”也有了,且权限也修改了。这一步就是把Master.Hadoop的公钥追加到Slave1.Hadoop的授权文件”authorized_keys”中去。使用下面命令进行追加并修改”authorized_keys”文件权限:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
3)用root用户修改”/etc/ssh/sshd_config”
具体步骤参考前面Master.Hadoop的”设置SSH配置”,具体分为两步:第1是修改配置文件;第2是重启SSH服务。
4)用Master.Hadoop使用SSH无密码登录Slave1.Hadoop
当前面的步骤设置完毕,就可以使用下面命令格式进行SSH无密码登录了。
ssh 远程服务器IP

从上图我们主要3个地方,第1个就是SSH无密码登录命令,第2、3个就是登录前后”@”后面的机器名变了,由”Master”变为了”Slave1”,这就说明我们已经成功实现了SSH无密码登录了。
最后记得把”/home/hadoop/”目录下的”id_rsa.pub”文件删除掉。
到此为止,我们经过前5步已经实现了从”Master.Hadoop”到”Slave1.Hadoop”SSH无密码登录,下面就是重复上面的步骤把Slave1.Hadoop到Master.Hadoop的ssh配置好。这样,我们就完成了”配置Master与Slave服务器间的ssh互相访问”。
3、Java环境安装
所有的机器上都要安装JDK,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装JDK以及配置环境变量,需要以”root”的身份进行。
3.1 配置环境变量
编辑”/etc/profile”文件,在后面添加Java的”JAVA_HOME”、”CLASSPATH”以及”PATH”内容。
1)编辑”/etc/profile”文件
在”/etc/profile”文件的尾部添加以下内容:
export JAVA_HOME=**/jdk1.8.0
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin2)使配置生效
保存并退出,执行下面命令使其配置立即生效。
source /etc/profile3.2 验证安装成功
配置完毕并生效后,用下面命令判断是否成功。
java -version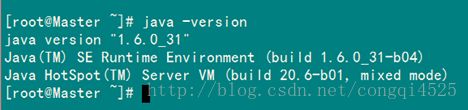
从上图中得知,我们以确定JDK已经安装成功。
4、Hadoop集群安装
所有的机器上都要安装hadoop,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装和配置hadoop需要以”root”的身份进行。
4.1 安装hadoop
首先用root用户登录”Master.Hadoop”机器,将Hadoop安装包解压到选定的目录位置,然后把Hadoop的安装路径添加到”/etc/profile”中,修改”/etc/profile”文件(配置java环境变量的文件),将以下语句添加到末尾,并使其有效:
export HADOOP_HOME=/**/hadoop
export PATH=$PATH :$HADOOP_HOME/bin:HADOOP_HOME/sbin重启”/etc/profile”,令配置生效
source /etc/profile4.2 配置hadoop
1)配置hadoop-env.sh 和 yarn-env.sh : 在结尾添加如下环境变量
export JAVA_HOME=**/jdk1.8.0
2)配置core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://Master.Hadoop:9000value>
<final>truefinal>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/program/hadoop-2.4.1/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
configuration>3)配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>Master.Hadoop:50090value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/program/hadoop-2.4.1/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/program/hadoop-2.4.1/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>hadoop-cluster1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>在对应位置创建dfs目录和name、data子目录。
4)配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobtracker.http.addressname>
<value>Master.Hadoop:50030value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>Master.Hadoop:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>Master.Hadoop:19888value>
property>
<property>
<name>mapred.job.trackername>
<value>http://Master.Hadoop:9001value>
property>
configuration>5)配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>Master.Hadoop:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>Master.Hadoop:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>Master.Hadoop:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>Master.Hadoop:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>Master.Hadoop:8088value>
property>
configuration>6)配置slaves文件(Master主机特有)
去掉”localhost”,每行只添加一个主机名,把剩余的Slave主机名都填上。
例如:添加形式如下
Slave1.Hadoop
4.3 启动及验证
1)格式化HDFS文件系统
在”Master.Hadoop”上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode -format2)启动hadoop
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
service iptables stop使用下面命令启动。
start-all.sh3)验证hadoop
(1)验证方法一:用”jps”命令
在Master上用 java自带的小工具jps查看进程。

在Slave1上用jps查看进程。

如果在查看Slave机器中发现”DataNode”和”TaskTracker”没有起来时,先查看一下日志的,如果是”namespaceID”不一致问题,采用”常见问题FAQ6.2”进行解决,如果是”No route to host”问题,采用”常见问题FAQ6.3”进行解决。
(2)验证方式二:用”hadoop dfsadmin -report”
用这个命令可以查看Hadoop集群的状态。
4.4 网页查看集群
1)访问”http://192.168.1.2:50070”
2)访问”http://192.168.1.2:8088”
