hadoop 超详细入门wordcount
概述
今天博客收到了第一条评论,感觉很赞哦,最近一直在学习hadoop,主要是结合《实战Hadop:开启通向云计算的捷径(刘鹏)》,然后apache官网的doc(还是要以官网为主,虽然是全英文的,但总比那些版本都不对的博客来开得多得多),自己尝试了一下hadoop的hello world之后,有继续尝试了使用docker来模拟多机的集群分布式环境,最后再返回来看hadoop的核心框架hdfs和mapreduce的设计原理时方才恍然大悟,这个东西很厉害!本人在下博客中学习到了很多,本章描述也会借用博客中的一些描述,注明来源如下。(如有不妥,请告知删除)。
http://blog.csdn.net/zhongwen7710/article/details/39376247
目标
这次博客时,感觉对hadoop的框架已经有了一个基本的认识,大体的知道了如何去操作以及一些基本原理,本文尝试记录下此过程,不仅作为自己的记录同时也与大家分享。
1.安装并完成单机上的hadoop hello world(wordCount被认为是其上的hello world程序)。
2.从数据处理流程和任务调度流程两个方面解析wordcount发生了啥。
hello world hadoop
个人使用hadoop-2.7.3,其他版本在官网上有404的情况,不太清楚什么原因,这个版本暂且可用。以下是基础教程链接:https://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html
需要软件安ssh java(本人使用自带openjdk-8)
jdk
ssh
下载解压hadoop
wget http://www-us.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.43tar.gz
tar xzfv hadoop-2.7.3.tar.gz
在etc/hadoop/hadoop-env.sh中配置java_home
update-alternatives --config
 图1
图1
# set to the root of your Java installation
export JAVA_HOME=/usr/java/latest(这里设置你自己的Java位置)
设置完成后应该可以使用Hadoop了
bin/hadoop
按照官网的指令,运行实例代码,可以看到输出结果
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
$ cat output/*
此处单节点的任务就完成了,这个时候仅仅没有啥调度就是一个节点完成的。下面接着看伪分布。这里我觉得应该是没有涉及到HDFS的,因为都还没有开启hdfs嘛,这里都是在本地文件系统上操作的,充分说明这个mapreduce可以跑一般文件系统上!(废话)Pseudo-Distributed Operation
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process
首先需要配置几个核心文件
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>然后检查一下ssh,一般的ubuntu自带了ssh,可以使用ps -e|grep ssh来检查是否开启,service ssh start是开启命令。
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys然后你就可以开始hdfs分布式文件系统之旅咯,官网上直接使用/tmp作为默认namenode目录,个人建议保存到自己的目录下,不然每次关机上次的东西都没了。操作如下
在etc/hadoop/core-sites.xml里加入
<property>
<name>hadoop.tmp.dirname>
<value>这里随意把/namenode/hadoop_${user.name}value>
property>
格式化操作系统
bin/hdfs namenode -format
sbin/start-dfs.sh
你就可以在 http://localhost:50070/里面看到namenode的情况了
然后我们接着在分布式文件系统里面跑上述的例子,以下大家可以看到很多熟悉的操作,dfs 后面的操作都是hdfs下的文件相关操作选项,具体可以参看hdfs更多的教程,此处不多述。
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/
$ bin/hdfs dfs -put etc/hadoop input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
$ bin/hdfs dfs -get output output
$ cat output/*
$ bin/hdfs dfs -cat output/*
$ sbin/stop-dfs.sh 好了,如果大家是第一次接触,那么到了这里应该差不多就可以有个大致的感觉了,其实我特别不喜欢写这个,没有什么思想,全是抄的官网文档,但是对于特别新手来说,可以参看一下,那么我们接着来讲一下真正的hello wolrd,到这个地方我们还没有写代码,也谈不上啥框架理解,就是先跑起来再说。接着讲wordcount之前,我说一下我的感受,为什么会有hadoop这种东西呢,因为数据量大嘛,数据大了之后很自然的一个想法就是把数据分布式处理。这样就有了hdfs,之后那我分布式了之后怎么计算呢,我数据存在不同的地方,我算的时候把数据移动肯定是会浪费很大的带宽的,mapreduce+hdfs实现了一个很妙的思路,就是说我不移动数据,我移动计算,这听起来很不错,计算本地化,那么我们就可以不错的解决大数据问题了。另外一个事情,mapreduce我现在的感觉并不是一个啥都能看的事情,海量数据的处理过程也可能是单一的,比方我们接下来要讲的计算文章单词的个数,或者一些常规的操作,我们利用map-reduce的编程思路试着去解决这些问题。好了,说多了大神也不看,小白也看不懂了,我们继续往下吧。
hello world maprecude
仍然是搬运官网,教程如下,如有错误对着教程做吧,看博客错了也不要怪我,谁叫你懒看官网呢^_^!
https://hadoop.apache.org/docs/r2.7.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
本来先写了一段介绍的,但是还是先上代码吧。大家把这段代码无脑跑通之后,我会给大家解释一些东西的,相信你能明白。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 需要设置一些东西
export JAVA_HOME=/usr/java/default
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
$ bin/hadoop com.sun.tools.javac.Main WordCount.java
$ jar cf wc.jar WordCount*.class
然后打包jar
根据上面的文件操作保证你的文件格式如下
$ bin/hadoop fs -ls /user/joe/wordcount/input/ /user/joe/wordcount/input/file01 /user/joe/wordcount/input/file02
这里会有一些输出提示xxxxx
$ bin/hadoop fs -cat /user/joe/wordcount/input/file01
Hello World Bye World
$ bin/hadoop fs -cat /user/joe/wordcount/input/file02
Hello Hadoop Goodbye Hadoop
输入下代码前记得保证output为空,output不为空的话,应该会报错。
$ bin/hadoop jar wc.jar WordCount /user/joe/wordcount/input /user/joe/wordcount/output
查看结果
$ bin/hadoop fs -cat /user/joe/wordcount/output/part-r-00000`
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2`恭喜你已经跑出来一个hello world了,你自己抄了java代码,然后运用了伪分布式文件系统,修修补补之后你就可以完成新的功能了,在此之前,我具体介绍下上述java代码,这出强烈推荐《实战Hadop:开启通向云计算的捷径(刘鹏)》该书第3章对这里的代码做了充分的解读。
wordcount数据处理过程
这里我们主要介绍wordcount过程mapreduce处理里数据都是啥样子的。我这里大概解释一下,mapreduce的过程以键值对的方式传递,然后我们主要是对mapreduce函数进行重写,同样也是要满足键值对的格式。这里map就是以(word,1)的形式展示,然后reduce就是相加统计的过程,思路非常简单。
这里介绍了mapreduce的数据处理流程。
 图2
图2
下图是mapreduce过程的整体概括,map从input到split输入,经过处理后(可能包括sort combine过程)输出中间结果,这些数据会被保存到磁盘而非hdfs中,之后被系统调度分配到各个reduce去继续处理。
 图3
图3
下面是更详细的一个过程图,与上图思想一样。

下面我们看看我们wordcount中每个地方的数据都是什么样子的吧。
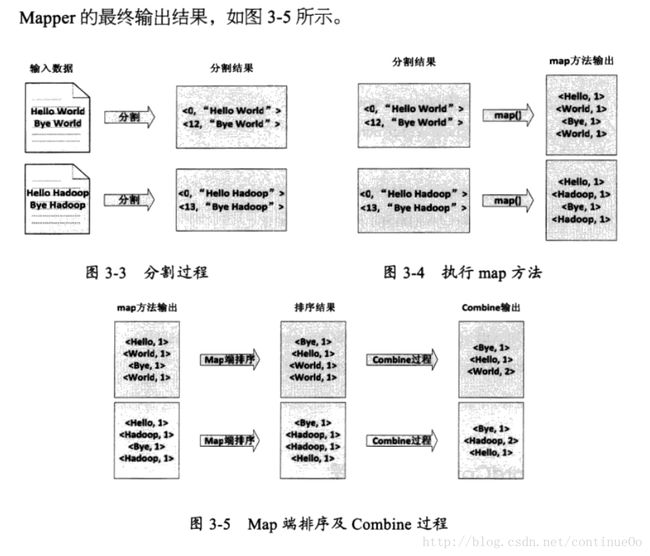 图4
图4
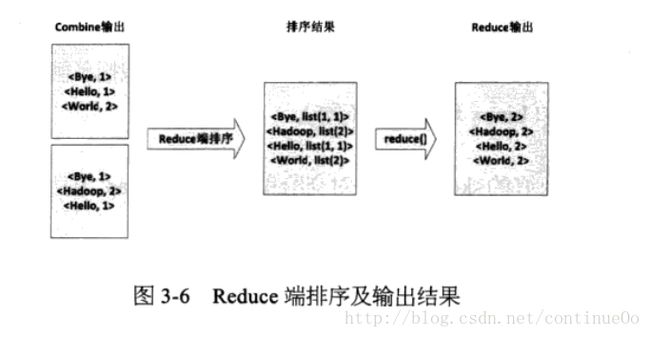 图5
图5
好了,这个地方留一点时间大家自己去看那个书里面的java代码详解,官网也有,不过没有那么详细,书中介绍了java几个大类的用处,介绍了job.setxxxx系列的初始默认条件,这些都是需要掌握的。
小结:上述图中mapreduce的过程,此处只有一个reduce(默认),并且没有涉及到调度过程,没有看到hdfs的参与,只知道有个地方input输入,然后会被切分成split,这里就表现出我写博客的必要了,介绍一些常识split从input来,split不会跨文件生成,比如input文件夹下面有file01,file02,那么就会有2个以上的split,然后hdfs中文件以block的形式存储,每个大文件(128M以上,可以设置大小)会被切分成block,,每个split包括大于等于1的整数个blocks。然后于此同时split决定了map的个数,有多少。
而reduce的个数是可以设置的。
wordcount整个调度过程
上面主要是讲数据处理的过程,这里讲讲调度过程。现在我假设你们知道什么是jobTracker TaskTracker(这是mapreduce的主要调度部分)。第一张图描述了mapreduce如何在hdfs的帮助下完成计算的转移而不是数据的转移。图6中,我们开启mapreduce程序的时候,mapreduce的主节点负责提交一个叫做job的东西,我们代码中设置了很多job的内容,包括用了什么map什么reduce以及其他配置,然后把这个jar包传到hdfs中,这里是非常厉害的,他把代码转移就避免了数据的移动,这样可以做到计算本地化,减小带宽浪费。wordcount input中有2个文件file01 file02就会划分成2个split,完成了图中第6步,系统根据这个划分来分配任务,如果此时有3台电脑,1个master两个slaves(通常datanode也不和master在一起,这里不太确定这个说法对不),那么如果file01 file02的block分别在slave1 slave2上(这里我们是无从得知的,因为hdfs是一个分布式操作系统,对外来说看起来是一个整体,我也不知道他放哪里,但是他内部是有均衡操作的我认为,大神可以指教),那么他可以把2个map任务分配到2个slave节点上。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。

图6
第二张图表示了计算任务的分布,一般集群中1个namenode n个datanode,上述描述针对数据存储,namenode只负责存储元数据,datanode存储实际数据且负责与client交互(我们运行bin/hadoop就是开启 了一个client)。jobTracker和namenode对应,taskTracker和datanode对应。
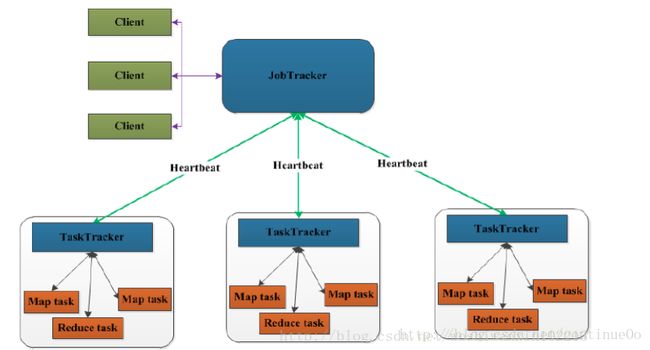 图7
图7
好了,今天就到这里,有机会继续给大家分享,如何使用docker去模拟真实的分布式系统。
参考资料
docker hadoop集群 http://www.tashan10.com/tag/hadoop/
Hadoop生态系统介绍及HDFS与MapReduce原理详细阐述 http://blog.csdn.net/zhongwen7710/article/details/39376247
《实战Hadop:开启通向云计算的捷径(刘鹏)》