大学食堂之HMM模型(三)——Baum-Walch算法
- 参数问题
- 理论知识
- 失败的实现
参数问题
(自己挖的坑,跪着也要写完!(╯‵□′)╯︵┻━┻)
理论知识
前面说了HMM的解码和评估,但是这都是建立在我们有了HMM的正确参数的前提条件下。然而如果我们真的想解决实际问题,比如动作识别,语音识别等问题时,很难有最优的参数用来预设值。如果我们有先验知识,可以在初始化的时候使参数向最优值靠近一些,如果没有的时候,甚至我们只能用将概率1均分来赋初值。那么这种时候怎么办,连模型参数都没有,怎么评估,怎么解码?
在第一篇文章中,讲前向算法的地方,我们假设,我们统计了一学期的食堂后厨的轮班记录,也就是说我们有一个小间谍,使得我可以掌握隐藏状态的序列,那么整个模型的状态图就是完全可见的了,只要数据够多,我只需要用最大似然估计去统计频率就可以去无限的逼近真实参数了。
现在问题就是我们无法拿到内部状态序列的数据,无法求HMM的参数Pi,A,B,也就无法进行前向变量、后向变量和维特比算法的计算。这个问题看似无法解决,但是Baum大神还是找到了一个解决这个问题的方法,这类算法都属于一类叫做EM算法的范畴。
我对这类算法的浅显的理解是,在数据量足够的情况下通过一次次的递归来笔记呢模型中的特定隐含参数的真实值。首先随意对内部参数赋值,然后得到一种解释输出的分布,然后对新得到的分布求内部参数的期望,得到新的内部参数值,在重新对可能的分布进行估值,以此类推。我的解释可能不到位,引用《HMM学习最佳范例中七》(http://www.52nlp.cn/hmm-learn-best-practices-seven-forward-backward-algorithm-3)中的解释:
直观地理解EM算法,它也可被看作为一个逐次逼近算法:事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略地给定某个初始参数λ0 ,确定出对应于这组参数的最可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,重新估计参数λ ,并在新的参数下重新确定模型的状态,这样,通过多次的迭代,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
对EM算法的一个简单实现是聚类算法中的K-means算法,实现起来比较简单,可以直观的理解算法背后的EM思想。
那么在Baum-Walch算法中怎么实现了EM思想求内部参数呢,这个算法中定义了两个关键变量,是这个算法的重中之重,符号是 ξ 和 γ ,我在后面就称之为gamma变量和xi变量。
首先解释gamma变量,它的计算方法是:
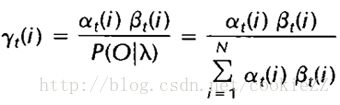
用图来表示就是这个意思:
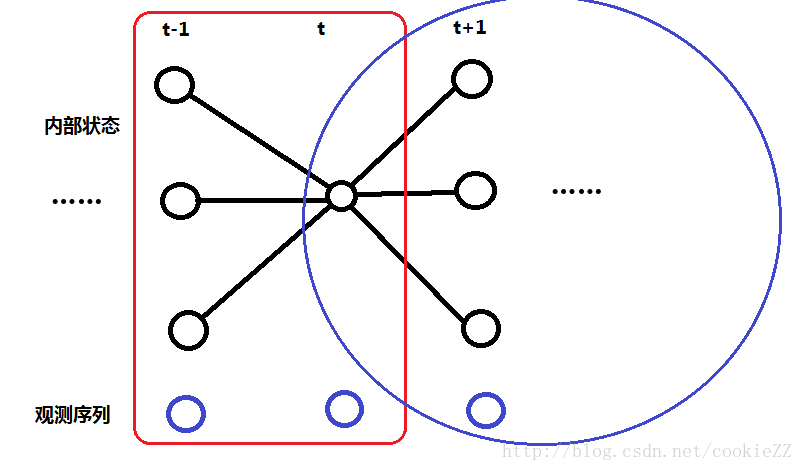
在前面说过,前向变量表示的是在t时刻以状态Si结束时总的概率(给定观测序列 O1...t ),也就是计算的是图中的红色框部分。后向变量的意思就是假定时间t时的内部状态是Si,模型输出 Ot+1...T 的概率,也就是计算上图中的蓝色圆圈中的部分。那么在此基础上,gamma变量的分子的意思就好理解了,它表示的是,在输出完整的观测序列 O1...T 的条件下,t时刻的内部状态是Si的概率。而分母就是在输出完整的观测序列的情况下,所有可能的内部状态的和,也就是我们在第一篇文章中说的,整个序列的概率。所以gamma变量的意义就是t时刻出现内部状态Si的概率,这个概率在t时刻是归一的,就是说t时刻的所有gamma变量相加为一。
然后xi变量比gamma变量稍微复杂一点,但是基本思想是一样的,表示的是:由t时刻到t+1时刻出现内部状态Si到Sj的这种转移的概率,公式如下:

示意图:
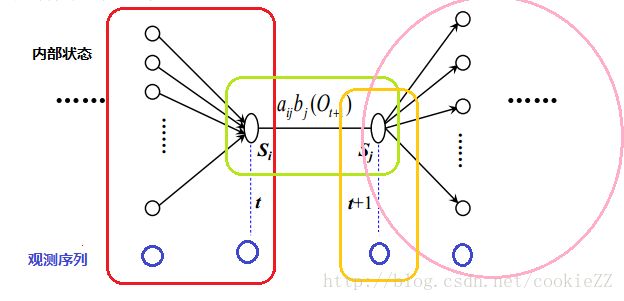
图中的红色框还是前向变量,粉色圈还是后向变量,就不过多解释了。然后绿色框是Si向Sj的内部状态转移概率,黄色框是t+1时刻的输出概率,这两个值分别通过A、B矩阵求得。这样才能把这个序列所有的内部状态和外部状态都考虑全面,不然大家可以看图中,少了任何一个框,都会有节点不被框到。公式中的分母就是t时刻到t+1时刻共 N2 种可能的转移方式求和,这也是为什么这个公式可以归一化。
理解了两个变量的含义就不难理解下面的这两个变量之间的关系:
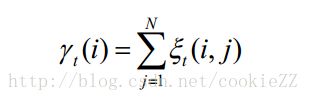
也就是gamma变量可以通过xi变量来计算,这个公式用白话说就是:t时刻Si状态向t+1时刻全部Sj转换的可能性的和就是t时刻内部状态是Si的概率。这个事也好理解,举一个例子,假设你上午可以学习或者睡觉,下午可以打球或者游泳,那么你一年中午学习下午打球的天数,加上上午学习下午游泳的天数就是你这一年中上午在学习的天数。
看到这,我们不禁要问:“所以呢?!这不是关键之处吗?!忍住把这篇破文章关掉的冲动看到这!看完了怎么也没有豁然开朗呢?!没有茅塞顿开呢?!”(╯‵□′)╯︵┻━┻
呃……好,我们往下说~(“就这么无视观众的吐槽真的好吗!该配合你演出的我演视而不见吗!”)我当然不会无视这个问题了……
关键是只明白定义是没有用的,这个变量的意义在于给了我们一种手段去统计内部观测序列,我们依然没有办法去得知真正的内部序列,但是我们即使有了真实的观测序列我们不也是为了统计求最大似然估计吗。而现在xi变量表示的是t时刻到t+1时刻各个内部状态之间的转移矩阵,把所有时刻的对应值相加不就是总的转移矩阵了吗。gamma变量表示的是t时刻的内部状态可能性的向量,那么结合输出序列就可以计算出输出概率矩阵(这一点后面还会详细说)。也就是说我们可以通过xi和gamma重新计算HMM的三个参数Pi,A,B。并且xi变量和gamma变量的计算需要alpha变量,beta变量,状态转移矩阵A和输出概率矩阵B。也就是我们可以不停地迭代这个过程直到我们的每轮的改动小于阈值。
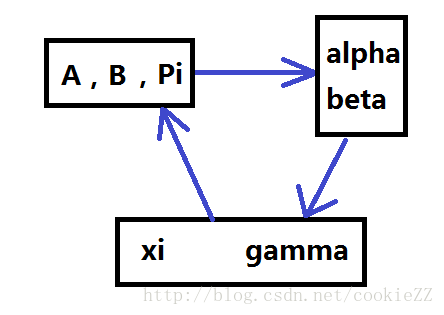
具体的重新计算HMM参数的方式是:



公式解释:(我的内部状态用S表示,外部状态用O表示。公式图片中分别用q和v表示)
1. gamma(t,i)变量的含义就是在输出观测序列的情况下,t时刻内部状态是Si的概率,并且满足局部的归一化。那么t=1的gamma变量就是第一个时刻输出观测序列的概率,并以此作为此次迭代的初始向量的值。
2. 这个公式中表达的很清楚了,分子是所有时刻的Si向Sj转移的概率,分母是所有时刻的内部状态为Si的概率,两者相除就是Si向Sj转移的概率,并且自然的满足A矩阵每行元素和为一的要求。
3. 这个公式中需要留神的是 δ 这个符号,这个不是我们前面用到的维特比变量,而是表示Kronecker函数,听起来高大上,实际上就是判断两个输入值是否相等,相等的话函数值为一,否则是零。每一次计算只有输出符合当前求解的输出时分子才参与计算。
结合我们之前提到的EM算法的思想,我们实际上可以开始时为HMM随机赋值(当然要满足归一化的要求),然后xi和gamma表示了该组参数下内部状态可能的统计规律,然后利于这两个参数重新为无法观测的内部状态赋值,以此类推。这里就不给出栗子了。毕竟自己实现的这个算法。。。并不是很理想。
失败的实现
前面的两篇文章都已经在写文章的时候把代码也敲出来了,本来想着这最后一个算法也实现出来,也算把自己的坑填好了,这部分HMM的文章也算可以告一段落。可惜可惜,事不遂人愿,最后的BaumWelch算法实现起来比前面两个算法遇到困难都多。最后的算法不能保证正确率单调收敛,即使如此我还是把遇到的问题都列出来,方便自己以后再看这块内容。
关于下溢出问题:在计算前向和后向变量的时候,如果输入序列过长,由于每一步都会降低数量级,到最后可能导致全部溢出,变量为零的情况。这里注意,用前向变量举例,这个变量是全局归一的,也就是说,把所有可能的观测序列用前向变量计算其出现概率,最后的相加为一,然而对单个观测序列内部的前向变量是没有归一化的。这种解决办法应该比较容易想到,就是把连乘转换为对数的加,这部分代码大家如果下载一些开源的HMM实现应该都会发现有Forward**WithScale**这种方式的实现。这种改进实际会将前向变量(或后向变量)的每个时刻的所有值进行归一,然后最后输出也不是最后一个时刻的求和(因为归一了,最后一个时刻求和就是1),而是对每个时刻的局部和进行求对数再求和。我觉得这可能是一种log-linear model的类似方式,但是我也没有进行数学推导,所以也是稀里糊涂不敢下定论。
关于阈值判断问题:教材上给出的算法结束的判断是依据|log Pt -log Pt−1 |是否小于阈值来判断是否收敛,就是用新的HMM去求解给定观测序列的概率,知道两次迭代之间的插值小于阈值。我看到有的实现中,判断相对误差,就是用两次迭代的插值除以上次的概率,用这个去和与之进行比较。
关于多个观测序列:有时可能给出多个观测序列,处理方式可以在一次迭代中去统计所有概率计算xi与gamma,然后如果所有的观测序列等长,那么整体除以观测序列数,如果不等长,就每个值除以自己在不同观测序列相同位置的计算次数。
参考文献:
1. 宋庆成《统计自然语言处理基础》
2. 宋庆成老师的《自然语言理解》的课件
3. 《使用python实现HMM》(http://blog.csdn.net/u014365862/article/details/50412978)
4. 《HMM学习最佳范例》(http://www.52nlp.cn/)