解开蚂蚁金服自研金融级分布式数据库OceanBase背后的技术秘密
本文根据陈萌萌老师在2018年5月10日【第九届中国数据库技术大会】现场演讲内容整理而成。
讲师简介:

陈萌萌,蚂蚁金服资深技术专家。目前在OceanBase团队负责SQL相关方向的开发工作。2006年毕业于清华大学,2006年到2008年在欧洲核子研究中心(CERN)负责网格计算调度器的开发工作,2009年5月在美国威斯康辛大学麦迪逊分校获得计算机硕士学位,先后在Oracle、华为美国研究所从事数据库的开发和研究。
摘要:
作为自主研发的金融级分布式数据库,多年来OceanBase稳定地支持了蚂蚁金服双十一峰值流量,并于2017年创造了25.6万笔支付每秒的世界纪录。作为新一代的关系数据库,OceanBase在扩展性、高可用、高性能、低成本等方面解决了一系列世界性技术难题,为上层应用提供了“不停机缩扩容”、“弹性大促”、“多地多活”等多项核心能力。今天,我们将为你一一解开OceanBase背后的“技术秘密”。
分享大纲:
1、OceanBase简介
2、核心技术优势
3、下一代OceanBase
正文:
一、OceanBase简介
在加入蚂蚁金服后,我发现很多传统数据库或传统架构难以解决的问题。OceanBase的定位是一个通用关系型数据库,在蚂蚁金服内部支撑了整个的核心交易系统。在架构层面,OceanBase与传统数据库最大的不同在于,它是一个分布式数据库,在数据库层面解决了业务的扩展性,并提供了高可用的数据库服务。与此同时,OceanBase还提供了弹性部署能力,并通过使用廉价PC机极大地降低了系统的成本。
首先,让我们简要回顾OceanBase整个发展过程。2010年,该项目为解决淘宝收藏夹问题落地,此时还不是一个通用数据库产品,功能上还只能通过定制的API进行访问。2013年,OceanBase支持标准SQL接口。2014年,OceanBase第一次支持了蚂蚁金服部分交易系统流量。2016年,第一个金融级云数据库版本正式发布。2017年,蚂蚁内部核心业务全部运行在OceanBase之上。
二、核心技术优势
OceanBase的核心优势可以总结为五点——线性扩展,高可用,一致性,低成本,易用性,以下逐一展开介绍。
1、线性扩展。传统单机数据库因受单机能力限制,所以扩展性有很大影响。OceanBase通过Paxos分布式协议、数据分区等机制对外提供了一致性保证,通过动态添加机器以获得水平扩展能力。
2、高可用。传统企业在解决高可用问题上更依赖高端硬件,成本增加的同时性能也会受损,因为它在软件设计上并不考虑硬件失败。在选择普通PC机的前提下,蚂蚁金服通过底层的分布式数据库解决方案保证系统的高可用性。
3、一致性。对数据库而言,在解决前两大问题的基础上还可保证一致性是困难的。OceanBase在线性扩展和高可用的基础上,保证了数据库ACID的一致性。
4、低成本。随着双十一交易量的超线性增长,数据库性能最终体现在逐年提高的吞吐量上,OceanBase通过使用廉价的PC机,极大的降低了系统的硬件成本,并通过对单机性能的极致优化,在保证高性能的同时有效的降低了整个系统的运行成本,
易用性,OceanBase SQL模块支持智能查询优化与执行,与MySQL高度兼容,以及Oracle增强功能,并提供多租户混部能力,可以支持HTAP的业务使用场景。
要想解决一致性、高可用及可扩展问题,我们需要知道,分布式数据库的高可用和一致性与传统数据库有哪些不同?
传统数据库通常是一主一备或一主多备模式,用户必须在最大可用性与最大一致性之间做选择,实际发生故障时很难切换。如果将数据同时落盘主库和备库,则牺牲了可用性;如果将数据异步同步到备库,很难保障故障发生时的数据一致性。
综上,传统数据库很难给出有效的系统容灾方案。
OceanBase底层基于分布式一致性协议Paxos,当有多份数据时,只要其中的多数派形成一致,就可以应答客户。只要多数派存活,服务就不受影响,在保证一致性的情况下最大地兼顾系统可用性。
业务层面,OceanBase可以保证发生故障时,RTO小于30秒,RPO等于0。这意味着数据库在任何故障下可在30秒内恢复服务,并且保证在恢复服务的过程中没有任何的数据丢失。
OceanBase的一致性通过数据分区实现。在传统数据库中,数据分区(partitioning)是数据逻辑层的概念,可以把数据按照预定义逻辑方式分区。在OceanBbase中,该分区同时也是一致性或同步单元。下图是一个三副本结构,其最小粒度可细化到数据分区,数据分区通过Paxos协议确保一致性,系统可在故障时自动选主,确保服务的自动恢复。
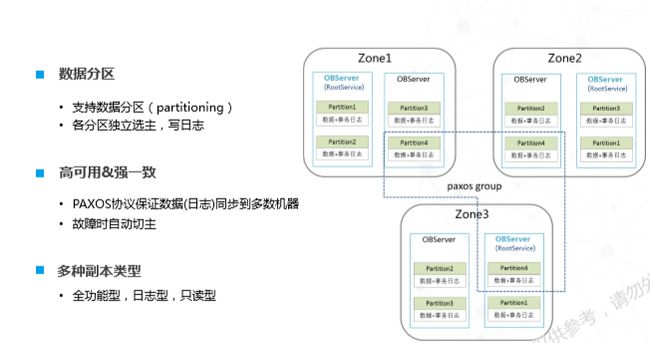
企业目前普遍使用的异地多活方案基本都是两地三中心,这也是蚂蚁金服内部早期使用的部署方案,所需的硬件条件是两地三机房(三个Zone)。假设,深圳有一个两机房,杭州有一个单机房,三个机房形成多数派投票,只要两个副本存在,服务就可正常使用。此时,我可以容忍任何一个单机房或者单机故障。但是,如果深圳整个城市垮掉,多数派就不存在,系统就无法对上提供服务,但也不会发生数据丢失,因为所有同步方案都要保证多数派,如果两个失败,日志就不会被同步或者提交。
另外,该方案的问题是缺乏二次容灾能力,只允许单节点失败,三副本是最基本的容灾部署方式。
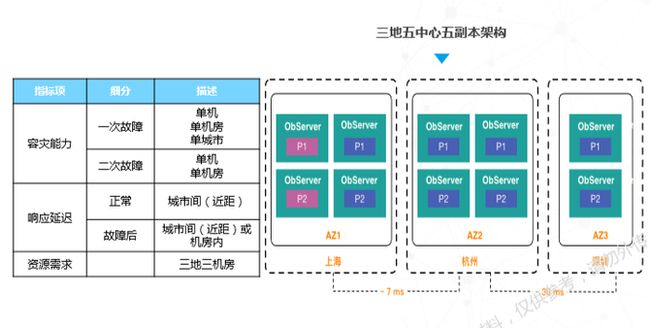
蚂蚁金服对此提出的解决方案是三地五中心五副本架构。举例说明,假设我在上海、杭州和深圳均有机房,且按照五副本方式部署,这里的多数派为3个,这就意味着五个副本至少要同步3个。与两地三中心的架构方式相比,新的架构增加了城市级容灾能力,其中的两个副本挂掉,依然符合多数派协议,同时具备抗二次故障的能力,。
该方案的不足之处是两个城市之间的延时问题,每次事务提交都需要等待,延迟大概在几毫秒左右。要想部署该方案,企业必须具备三地多机房的部署能力,这使得该方案并不适合所有用户。
接下来是蚂蚁金服弹性缩扩容问题解决方案讲解。对蚂蚁金服而言,弹性缩扩容方案最大的应用场景和挑战就是每年的双十一大促。对数据库比较了解的都知道,当日常流量与系统峰值流量相差极大时,日常运营就需要尽可能降低成本,但高峰时又需要支撑极高吞吐量。对任何系统而言,都要考虑性能和成本之间的平衡。2016年,蚂蚁金服开始尝试通过弹性缩扩容的方式解决该问题。
在双11之前,蚂蚁金服使用弹性云机房将系统能力临时扩充。双11以后,通过内部机制缩容。在数据库层面,简单来说可在不停服务的前提下,将数据库资源数据弹出去并按照同样方式收回。
具体操作步骤如下:
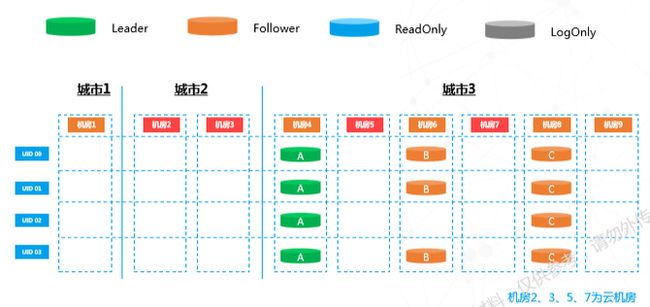
日常运营中,一个机房就足以装下所有流量。当流量上升时,需要将其弹到云机房,上图中机房2、3、5、7为云机房。此时,需要用到底层Paxos架构增减副本机制。
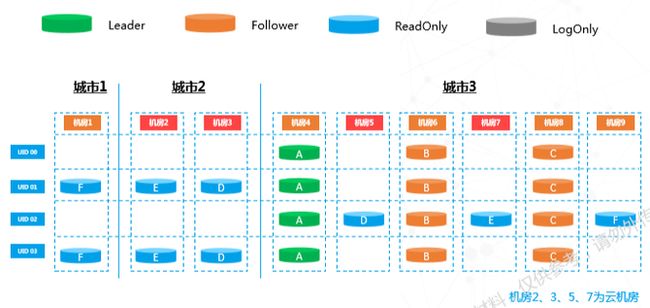
在要弹的机房中增加只读副本,该副本不参与一致性投票,只负责数据同步。增加只读副本后,数据会在系统内异步复制。当数据逐渐接近,下一个操作就会执行。
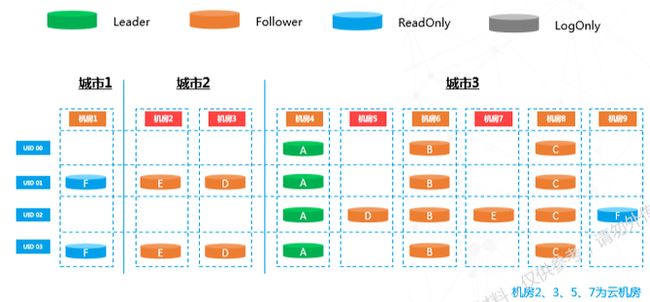
上图中部分副本的颜色发生改变,这意味着我们将之前的只读副本升级为全功能副本,Paxos的投票成员个数也由三个变为五个。注意:从三副本升级五副本,主不会发生变化。
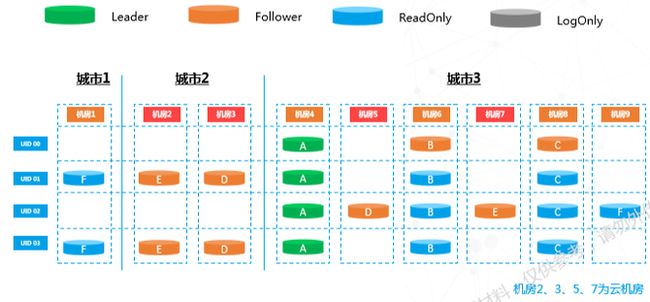
注意上图中节点颜色变化。从五副本状态到这,从投票节点变成不投票异部复制节点,内部会进行一次主改选。为了自动容灾,选主随时都可进行。通过改选,主被打散到机房2、3、4、5四个机房,流量也被拆成四份,相当于机房能力扩了四倍。选主完成后再对之前去掉的数据做成员变更,对之前的节点进行角色互换。虽然这部分操作较多,但选主和增加副本都是常规操作,不影响整个内部投票机制,并且在这个过程中,业务是无感知的。以上是底层的工作方式,上层需要通过路由把流量打到需要的机房,上下层互相配合最终完成弹性扩容。
以上是弹性扩容机制讲解,接下来是存储架构解读。OceanBase存储架构类似LSM tree,动态数据与静态数据分离。与传统数据库原地修改方式不同,OceanBase所有动态修改(增删改查)都在内存里完成,静态数据(不被修改的数据)存放在磁盘之上。我们在开始做OceanBase之时就意识到SSD会是主流存储形态,该存储方案可避免SSD随机写放大问题。由于动态数据与静态数据分离,只在动态数据和静态数据合并时需要写盘,并且我们对写盘进行了很多优化,保证数据块按照一定粒度写入,不会随机修改某一页面或某一地方。对SSD来说,整个生命周期没有任何随机写操作。
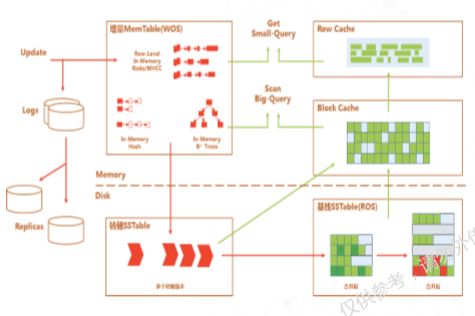
同时,该架构支持静态数据极致压缩,允许对数据进行编码操作,因为这部分数据平时不修改,所以可用字典编码,整个存储成本非常低。因为金融级数据对安全性非常敏感,因此,整个过程加入了多次数据强校验环节。
接下来,我简单介绍查询优化部分工作。从1979年开始至今,传统数据库已经将查询优化武装到牙齿,蚂蚁金服的查询优化和传统数据库有什么不一样呢?
在这一点上,我们面临三大挑战。一是LSM tree存储引擎架构决定了整个代价模型与传统数据库基于数据块的代价模型有很大区别,由于每次读取都要通过合并静态数据和动态数据完成,因此我们在计算执行代价时需要同时考虑两部分代价。
此外,由于很多执行操作基于刚修改过的数据,虽然不是严格意义上的In-Memory状态,但是可认为是准内存数据状态,对内存数据的访问性能优化成为必须要解决的问题。我们在内部进行了一些尝试,比如用编译执行代替传统的解释执行,性能提高了至少十倍不止,至于在何时选择何种解决方案就需要优化器参与决策。
第二大挑战是分布式系统的优化场景比单机复杂得多,做分布式系统优化时需要考虑如何在极短时间内取得较好优化效果。此外,在分区计划执行时,我们需要考虑针对分布式查询的一些特定给的优化手段。
第三大挑战是蚂蚁内部应用场景复杂。蚂蚁金服内部很多场景的数据变化非常剧烈,尤其是用户进行高吞吐量突发性并发操作时,数据变化特征非常明显。我们在数据分片以后,有很多优化决策需要放在执行期来做,SQL的自适应优化与执行也是一个需要研究的课题。
分布式SQL执行引擎的设计也是用户非常关心的话题,对于分布式数据库,分布式执行引擎和查询优化是性能的关键。我们对引擎部分的思考是希望支持OLTP和OLAP混合场景,面临的问题是数据跨分区执行。对于分区内部的并行需求,我们利用单机多线程能力执行。为了将分布式执行(跨分区执行)与并行执行的需求相结合,我们的优化方案分为全局优化和本地单机优化。在整个执行过程中,我们会同时考虑基于数据的水平并行和操作符间的流水线并行。与传统数据库的单级或两级流水线并行操作相比,OceanBase支持多级流水线,把MPP系统的IO能力和CPU能力充分利用起来。我们认为,这是充分发挥整个分布式架构优势的基本保证。
此外,OceanBase在1.0架构时就开始设计考虑云服务的可能性,所以它是多租户架构,这里的租户相当于传统数据库的实例。用户可以通过集群部署的多租户将资源拆分给不同业务。比如,在支付场景下,如果用户可以选择A、B两种支付渠道,A、B很难同时达到峰值流量。对于这种消长或者弥补流量的应用,可以考虑部署在同一集群内。当然,实际考虑要素较多,此处不一一列举。
同时,多租户架构也可带来资源隔离和资源利用率的提升,因为整个隔离并没有按照物理上的虚机等方式做隔离,隔离的粒度可以更精细,overhead也更小。
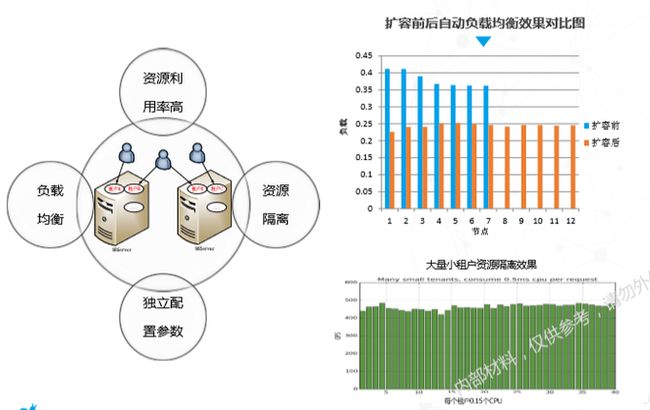
随着租户数量增加,负载均衡是多租户架构面临的一大难题。在分布式系统里,负载均衡属于NP问题,没有绝对优雅的解决方案。考虑到该架构特性,我们的负载均衡方案是,对于小租户的请求,尽量在一台机器上满足,这样可以避免分布式事务;对于有数据分片的租户,我们会将其打散到多个机器,充分利用机器能力。下图为扩容前后负载均衡的变化情况以及大量小租户资源隔离效果图:
下一代OceanBase
预计在今年9月份,OceanBase将会发布2.0版本。新版本主要强调通用性,在传统能力上,提供很多传统数据库的功能,比如全局快照、全局索引,数据编码优化、自适应执行计划、流量回放、兼容性等。从商用角度讲,OceanBase 2.0版本也会是更加成熟的商用版本。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31077337/viewspace-2155068/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31077337/viewspace-2155068/