JanusGraph -- 简介
目录
- 简介
- 历史
- 基本概念
- 关键点(来自官网)
- 整体架构(来自官网)
- 如何使用:
- 其他:
- ETL
- OLTP与OLAP
简介
图数据库源起欧拉和图理论,也可称为面向/基于图的数据库,对应的英文是Graph Database。
图数据库的基本含义是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
图将实体表现为节点,实体与其他实体连接的方式表现为联系。我们可以用这个通用的、富有表现力的结构来建模各种场景,从宇宙火箭的建造到道路系统,从食物的供应链及原产地追踪到人们的病历,甚至更多其他的场景。
图形数据库是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。最常见的例子,就是社会网络中人与人之间的关系。关系型数据库用于存储关系型数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。
目前主流的图数据库有:Neo4j,FlockDB,GraphDB,InfiniteGraph,Titan,JanusGraph,Pregel等。下面说一下JanusGraph
官网上:
JanusGraph is a scalable graph database optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. JanusGraph is a transactional database that can support thousands of concurrent users executing complex graph traversals in real time.
JanusGraph是一个可扩展的图形数据库,专门用于存储和查询分析分布在多机集群中的数千亿个顶点和关系边的图形。
JanusGraph是一个事务数据库,可以支持数千个并发用户实时执行复杂的图遍历。
历史
- JanusGraph是2016年12月27日从Titan fork出来的一个分支,之后TiTan的开发团队在2017年陆续发了0.1.0rc1、0.1.0rc2、0.1.1、0.2.0等四个版本,最新的版本是2017年10月12日。
- titan是从2012年开始开发,到2016年停止维护的一个分布式图数据库。最初在2012年启动titan项目的公司是Aurelius,2015年此公司被 DataStax(DataStax是开发apache Cassandra 的公司)收购,DataStax公司吸收了TiTan的图存储能力,形成了自己的商业产品DataStax Enterprise Graph。
- TiTan开发者们希望把TitTan放到Apache Software Foundation下,不过,DataStax不愿意这样做(可能考虑到要保护自己的商业产品DataStax Enterprise Graph的技术优势吧,其实这点优势是从Titan来的),而且自从2015年9月DataStax收购了Titan的母公司后,TiTan一直处于停滞状态(应该是DataStax收购之后,忙于推出自己的商业产品DataStax Enterprise Graph,忙于整合Titan进自己的商业产品吧,可是Titan本身没有得到发展)。鉴于此,2016年6月,TiTan的开发者们fork了一个TiTan的分支(因为Titan已经属于DataStax了,所以他们必须另外弄一个商标),重命名为JanusGraph,并将其置于Linux Software Foundation下。
- 2017年4月6日发布了第一个版本0.1.0-rc1,目前最新版本是2017年10月12日发布的0.2.0版。
JanusGraph项目启动的初衷是“通过为其增加新功能、改善性能和扩展性、增加后端存储系统来增强分布式图系统的功能,从而振兴分布式图系统的开发”,JanusGraph从Apahce TinkerPop中吸收了对属性图模型(Property Graph Model)的支持和对属性图模型进行遍历的Gremlin遍历语言。
基本概念
同大多数图数据库一样,JanusGraph采用 属性图 进行建模。基于属性图的模型,JanusGraph有如下基本概念:
- Vertex Label:节点的类型,用于表示现实世界中的实体类型,比如"人”,“车”。在JanusGraph中,每一个节点有且只有一个Vertex Label。当不显式指定Vertex Label时,采用默认的Vertex Label。
- Vertex:节点/顶点,用于表示现实世界中的实体对象。
- Edge Label:边的类型,用于表示现实世界中的关系类型,比如“通话关系”,“转账关系”,“微博关注关系”等;
- Edge: 边,用于表示一个个具体的联系。JanusGraph的边都是单向边。如果需要双向边,则通过两条相反方向的单向边组成。JanusGraph不存在无向边。
- Property Key:属性的类型,比如“姓名”,“年龄”,“时间”等。Property Key有Cardinality的概念。Cardinality有SINGLE、LIST和SET三种选项。这三种选项分别用于表示一个Property中,对于同一个Property Key是只允许有一个值、允许多个可重复的值,还是多个不可重复的值。
- Property:属性,用于表示一个个具体的附加信息,采用Key-Value结构。Key就是Property Key,Value就是具体的值。
关键点(来自官网)
- 弹性和线性可扩展性,适用于不断增长的数据和用户群。
- 用于性能和容错的数据分发和复制。
- 多数据中心高可用性和热备份。
- 支持ACID和 最终的一致性。
- 支持各种存储后端:
- Apache Cassandra
- Apache HBase
- Google Cloud Bigtable
- Oracle BerkeleyDB
- 通过与大数据平台集成,支持全局图形数据分析,报告和ETL:
- Apache Spark
- Apache Giraph
- ApacheHadoop
- 支持以下方式进行geo、数据范围搜索和全文搜索:
- ElasticSearch
- Apache Solr
- Apache Lucene
- 与Apache TinkerPop图形堆栈本机集成:
- Gremlin图查询语言
- Gremlin图服务器
- Gremlin应用程序
- Apache 2许可下的开源
- 工具可视化存储在JanusGraph中的图形:
- Cytoscape
- Apache TinkerPop 的 Gephi插件
- Graphexp
- Cambridge Intelligence 的 KeyLines
- Linkurious
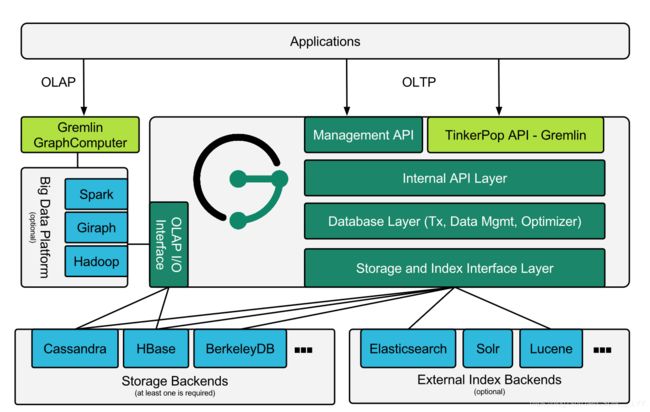
整体架构(来自官网)
JanusGraph是一个图形数据库引擎。JanusGraph本身专注于紧凑图形序列化,丰富的图形数据建模和高效的查询。
JanusGraph利用Hadoop进行图形分析和批处理图处理。
JanusGraph为数据持久性、数据索引和客户端访问实现了强大的模块化接口。JanusGraph的模块化架构使其能够与各种存储、索引和客户端技术进行互操作; 模块化架构还简化了JanusGraph简化了支持新的一个 模块的流程。
如何使用:
作为一个数据库系统,它是要用来为应用程序存储数据用的,那么应用程序应该如何使用JanusGraph来为自己存储数据呢?
一般来说,应用程序可以通过两种不同的方式来使用JanusGraph:
- 第一种方式:可以把JanusGraph嵌入到应用程序中去,JanusGraph和应用程序处在同一个JVM中。应用程序中的客户代码(相对JanusGraph来说是客户)直接调用Gremlin去查询JanusGraph中存储的图,这种情况下外部存储系统可以是本地的,也可以处在远程
- 第二种方式:应用程序和Janus Graph处在两个不同JVM中,应用通过给JanusGraph提交Gremlin查询给GremlinServer,来使用JanusGraph,因为JanusGraph原生是支持Gremlin Server的。
Gremlin Server是Apache Tinkerpop中的一个组件
JanusGraph集群包含一个、或者多个JanusGraph实例。每次启动一个JanusGraph实例的时候,都必须指定JanusGraph的配置。在配置中,可以指定JanusGraph要用的组件,可以控制JanusGraph运行的各个方面,还可以指定一些JanusGraph集群的调优选项。
- 最小的JanusGraph配置只需要指定一下JanusGraph的后端存储系统,也就是它的持久化引擎。
- 如果要JanusGraph支持高级的图查询,就需要为JanusGraph指定一个索引后端。
- 若果要提升JanusGraph的查询性能,就必须为JanusGraph指定缓存,指定性能调优的选项。
以上提到的后端存储系统、索引后端、缓存、调优选项等都可以在JanusGraph的配置文件中进行指定。默认情况下它的配置文件存放在JanusGraph_home/conf目录下。
storage.backend=cassandra
storage.hostname=localhost
index.search.backend=elasticsearch
index.search.hostname=
index.search.elasticsearch.client-only=true
也可以在写测试用例时代码控制:
/**
* 创建一个JanusGraph实例
* @return JanusGraph的一个实例
*/
private static JanusGraph create() {
try {
return JanusGraphFactory.build()
.set("storage.backend", "hbase")
.set("storage.hostname", "")
.set("storage.port", "")
.set("storage.hbase.table", "")
.set("cache.db-cache", "true")
.set("cache.db-cache-clean-wait", "20")
.set("cache.db-cache-time", "180000")
.set("cache.db-cache-size", "0.5")
.set("index.relationalNetwork.backend", "elasticsearch")
.set("index.relationalNetwork.hostname", "")
.set("index.relationalNetwork.port", 9000)
.open();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
其他:
ETL
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。
目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计ETL的时候我们也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到ODS(Operational Data Store,操作型数据存储)中——这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高ETL的运行效率。ETL三个部分中,花费时间最长的是“T”(Transform,清洗、转换)的部分,一般情况下这部分工作量是整个ETL的2/3。数据的加载一般在数据清洗完了之后直接写入DW(Data Warehousing,数据仓库)中去.
详情:https://www.cnblogs.com/yjd_hycf_space/p/7772722.html
OLTP与OLAP
- 用于联机事务图的持久化技术(通常直接实时地从应用程序中访问)。这类技术被称为图数据库,它们和“通常的”关系型数据库世界中的联机事务处理(Online Transactional Processing,OLTP)数据库是一样的。
- 用于离线图分析的技术(通常都是按照一系列步骤执行)。这类技术被称为图计算引擎。它们可以和其他大数据分析技术看做一类,如数据挖掘和联机分析处理(Online Analytical Processing,OLAP)。
refer:
http://www.cnblogs.com/zhangzl419/p/9100498.html
http://www.itboth.com/d/NBVZjy/hbase