Hadoop之hive学习_01
Hive是构建在hdfs上的一个数据仓库,本质上就是数据库,用来存储数据
数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,用于支持企业或组织的决策分析处理。
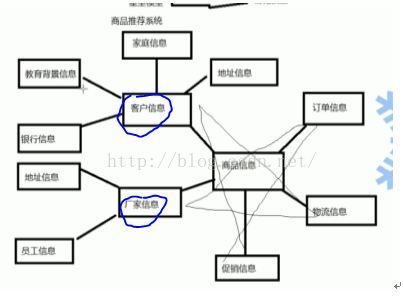
1. 面向主题:数据仓库的主题是按照一定得主题进行组织的,即用户所关注的重点对象,比如商品推荐系统。
2. 集成的:将分散的数据(文本文件,oracle数据,mysql数据。。。)进行加工处理才能够成为数据仓库的存储对象。
3. 不可更新的:数据仓库中的数据起主要用途是用于决策分析,所以主要的数据操作主要是查询操作。
4. 随时间不变化:
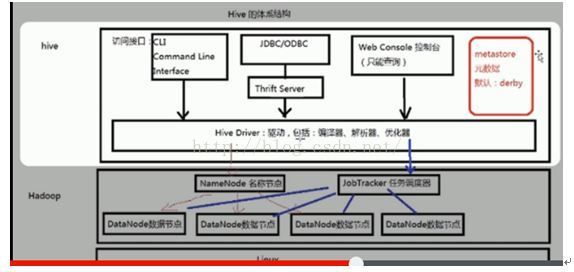
Hive体系结构:
1. 数据源:业务数据系统,文档资料,其他数据
2. 数据存储及管理:(ETL过程),[按一定的格式]对数据进行抽取(extract),转换(transform),装载(load)。经过etl操作的数据存放在数据仓库中。
3. 数据仓库引擎:包含服务器(不同服务器用不同的服务,如数据查询,数据报表,数据分析,应用等)。
OLTP应用:联机事务处理过程(面向交易的处理过程),面向事务操作,比如银行转账。
Oltp数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。
Oltp特征(百度):
支持大量并发用户定期添加和修改数据。
反映随时变化的单位状态,但不保存其历史记录。
包含大量数据,其中包括用于验证事务的大量数据。
结构复杂。
可以进行优化以对事务活动做出响应。
提供用于支持单位日常运营的技术基础结构。
个别事务能够很快地完成,并且只需访问相对较少的数据。OLTP 旨在处理同时输入的成百上千的事务。
实时性要求高。
数据量不是很大。
交易一般是确定的,所以OLTP是对确定性的数据进行存取。(比如存取款都有一个特定的金额)
并发性要求高并且严格的要求事务的完整、安全性。(比如这种情况:有可能你和你的家人同时在不同的银行取同一个帐号的款)
OLAP应用:联机分析处理过程,用于支持复杂的分析操作,侧重于对决策人员和高层管理人员的决策支持。针对历史数据操作,主要面向查询,比如商品推荐系统
数据模型:
1. 星型模型:以商品信息为主题的星型数据模型

2. 雪花模型:基于星型模型所发展起来的更复杂的数据模型。
Hive:由于Hive是构建在hdfs上的一个数据仓库,所以hive数据保存在hdfs上的。
Hive可以通过etl方式对数据进行操作。他提供hql(类似于sql)方便用户查询数据。
Hive允许udf用户自定义函数操作(比如用户自定义mapper和reducer)。
Hive本质上是SQL解析引擎,是将SQL语句转换为MR Job,然后在Hadoop上执行。
Hive的表就是hdfs的目录/文件:表—目录,数据—文件
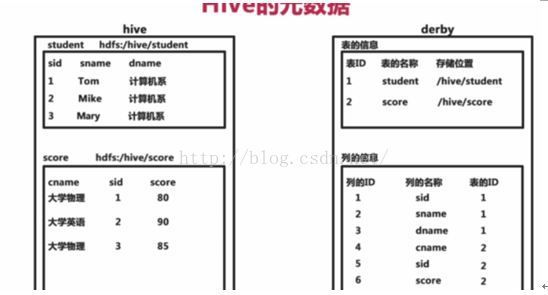
Hive的元数据:
Hive 将元数据(metastore)存在默认数据库derby中,支持myql,derby等数据库;
Hive的元数据包括表名,表的列和分区机器属性,表的属性(是否为外部表等),表的数据所在目录等。
Hql语句的执行过程:
解释器,编译器,优化器完成hql查询语句从词法分析,语法分析,编译,优化以及查询计划的生成。生成的查询计划存储在hdfs上,以供MR电泳执行。
HQL à解析器(词优化器法分析)à编译器(生成HQL的执行计划javac命令)à优化器(生成最优的执行计划)à执行
| sqlplus 数据库名/密码@ip:1521/orcl --打开 oracle explain plan for select * from emp where depid=10;--执行解释计划 select * from table(dbms_xplan.display); --查看select的执行计划 create index myindex on emp(deptno); --创建索引 |
Archive.apache.org下载旧版本
Hive的安装模式:
1. 嵌入模式:
元数据信息被存储在hive自带的derby数据库中。
只允许创建一个连接:相同时间下只能有一个用户操作。
多用于Demo演示
2. 本地模式
元数据信息存储在Mysql数据库中
Mysql数据库与hive运行在同一台物理机器上
多用于开发与测试
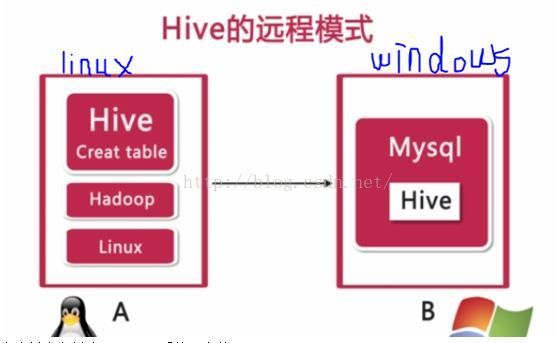
3. 远程模式
元数据信息存储在mysql数据库中
Mysql数据库和Hive数据仓库不在同一台物理机器上
用于生产环境,允许创建多个连接
嵌入式安装:
安装之前要确保Hadoop运行启动(jps命令查看);
tar –zxvf xxx.tar.gz --解压tar包
cd bin
./hive –创建hive数据仓库
可以将hive的目录加到系统path路径中,vi ~/.bash_profiles
HIVE_HOME =/home/soft/apache-hive-0.13.0-bin
export PATH =$HIVE_HOME/bin:$PATH
source~/.bash_profiles
在任何目录下执行:hive,都可以进入hive数据仓库(初次浸入式会在当前目录下创建一个metastore_db)
远程模式安装:
在虚拟中在创建wondows系统,安装mysql
mysql –uroot –p–进入mysql
create databasehive --创建hive数据库
mysql图形化工具:mysql-Frent
在linux中:
,首先进行解包:tar –zxvfxxx.tar.gz
由于元数据信息保存在mysql中,所以我们必须在hive中访问mysql数据库,必须见mysql驱动jar包加载到hive/lib中
创建并编辑hive-site.Xml文件(可以参考hive-default.xml)。
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin#AdminManualMetastoreAdmin-RemoteMetastoreDatabase
|
***如果使用root权限,要设置mysql可以远程连接 |
启动bin/hive命令(必要时将hive添加到系统PATH中去)。
Hql语句
| create table test( id int, tname string ); --创建表 |
本地模式基本和本地安装基本一致,区别是
/dabasename(hive)
Hive的管理—CLI方式
Hive管理方式:
1. CLI命令行方式
1.1 输入#
1.2 CTRL+L或 !clear ---清屏
1.3 show tables; ---查看所有表
1.4 show functions; ---查看数据仓库内置的函数
1.5 desc 表名 ----查看表结构
1.6 dfs -ls 目录 --查看hdfs上的文件 dfs –lsr 目录 ---递归方式查看
1.7 ! 命令 ---执行操作系统的命令 !pwd !ls
1.8 select * from test ; 查询语句,除了这条语句外,其他select语句会将sql转换为Mapreduce作业查询。
1.9 source 文件 ----使用source命令执行sql语句。 创建my.sql文件。写入select* from test;保存; 在hive命令中输入source/root/my.sql 执行sql语句
1.10 hive –S --使用静默模式操作cli,即不打印日志只打印输出结果
1.11 hive –e sql语句 --直接执行sql语句 hive –e ‘show tables’;
2. Web界面
2.1 #hive –service hwi ---web启动方式,默认端口9999. URl:http://[IP]:9999/hwi/
该命令会加载hive的war包,即源码包,所以我们必须下载源码包并解压,并将hwi/web目录打包:jar cvfM0 hive-hwi-0.13.0.war –C web/ . ,然后将war包拷贝到$HIVE_HOME/lib下:cphive-hwi-0.13.0.war ~/$HIVE_HOME/lib/,修改conf/hive-site.xml,添加:
| |
1.2 拷贝$JAVA_HOME/lib/tools.jar到$HIVE_HOME/lib/
1.3 重新启动,打开网页,web上只能做查询操作,create session执行查询操作
3. 远程服务启动方式
3.1 #hive –service hiveserver ----启动远程服务 port:10000
**如果以jdbc或odbc的程序登录到hive中操作数据时,必须用远程服务启动方式
该命令启动hive ThriftServer
Hive数据类型:
基本数据类型:
tinyint/smallint/int/bigint:整型
float/double:浮点数类型
string/varchar/char:字符串类型
varchar(20),最大字符串为20;char(20),固定长度为20
复杂数据类型:
array:数组类型,有一系列相同数据类型的元素组成
map:集合类型,包含
struct:结构类型(他妈的不会是泛型吧),包含不同数据类型的元素,通过“点语法”方式获得。
时间类型:
data:hive0.12.0版本后
timeStamp:hive0.8.0后
| create table person( pid tinyint, pname string, married Boolean, salary double );
复杂数据类型: create table student( sid int, sname string, grade array ); 存储的格式为:{1,’Tom’,[90,90,75]}
create table student1( sid int, sname string, grade map ); 存储格式:{2,’Mike’,<’语文’,50>}
create table student2( sid int, sname string, grade array ); 存储格式:{1,’Tom’,[<’语文’,83>,<’数学’,90>]}
create table student( sid int, info struct ); 存储格式:{1,{‘Tom’,30,’男’}} |
时间数据类型:
timestamp 与时区无关的:selectunix_timestamp();---查看当前系统时间戳的偏移量
date描述的是一个特定的时间(年,月,日YYYY-MM-DD)
Hive 的数据存储:
进入50070NN节点网页:查看hdfs的目录文件系统
Hive中没有专门的数据存储格式,默认下一制表符为分隔符
hive存储结构主要包括:数据库,文件,表,视图
hive可以直接加载文本文件
在创建表时,可以指定hive数据的列分隔符与行分隔符
表:
1. Table内部表
每一个Table在hive中都有一个响应的目录存储数据,所有Table数据都保存在该目录中。
删除表时,元数据和数据都会被删除。
| create table t1( tid int,tname string,age int );
create table t2( tid int,tname string,age int )location ‘/mytable/hive/t2’ ---指定文件存储在hdfs上的文件路径 row format delimited fields terminated by ‘|’ ----指定分隔符;
create table t4 row format delimited fields terminated by ‘|’ as select * from test; -----利用test表数据创建t4 hdfs dfs –cat /…/00000.0 ---查看hdfs文件系统内容
alter table t1 add columns(English int); ---添加数据 drop table t1;删除表 |
2. Partition分区表
Partition对应于数据库的partition列的密集索引
在hive中,表中的partition对应于表下的一个目录,所有的partition数据都存储在对应的目录中
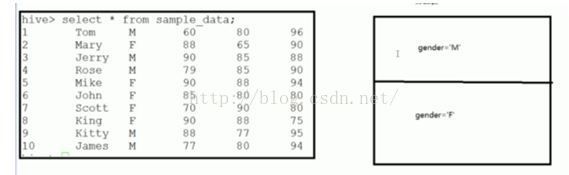
| create table patition_1( sid int,sname string )partitioned by (gender string) row format delimited fields terminated by ‘,’; eg.insert into table partition_1 partition(gender=’M’) select sid,sname from test where gender=’M’; insert into table partition_1 partition(gender=’F’) select sid,sname from test where gender=’F’; 会在hdfs中生成/user/hive/warhourse/partition_1/gender=M和gender=F两个目录 通过sql执行计划来查看查询效率 |
3. External Table 外部表
外部表指向已经在HDFS中存在的数据,可以创建partition
他和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异;
外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中只是与外部数据建立一个链接。当删除外部表时,仅删除该链接。
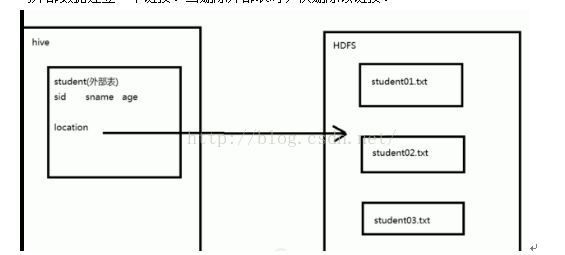
创建student01.txt,student02.txt,student03.txt并插入数据
student01.txt:Tom,23..
student02.txt:Mike,33..
student03.txt:Jams,49..
| hdfs dfs –put student01.txt /input hdfs dfs –put student02.txt /input hdfs dfs –put student03.txt /input create external table ext_student( sid int, sname string, age int )location ‘/input’ row format delimited fileds terminated by ‘|’; |
创建完成后使用select * from ext_student;可以看到ext_student表中插入了/input中的三个文件数据。
当使用hdfs dfs –rm /input/student03.txt删除某一个文件后,在使用select查询,可以看到03.txt的数据没有了,如此验证了删除了文件代表删除了链接,从而不能获取数据。
1. Bucket Table桶表
桶表是对数据进行哈希取值,然后放到不同的文件中存储。
| create table bucket_table( sid int, sname string, age int; )clustered by(sname) into 5 buckets; |
视图:
视图是一种虚表,是一种逻辑概念;
可以跨越多张表;
视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
建立视图其好处是可以简化复杂的查询
| 这里有两张表: emp :empno,ename,sal,age,sex,deptno dept:deptno,dname 多表查询:查找员工信息:empno,ename,sal,dname 使用视图: create view empinfo as select e.empno,e.ename,e.sal*12 sal,d.dname from emp e,dept d where e.deptno = d.deptno; 执行select语句查询视图 |
**物化视图:
由上面的操作可以明显看出,视图的建立可以大大提高数据查询效率,所以如果存在这样一个实际的表是很有帮助的,我们成为物化视图。
可惜的是在hive数据仓库中没有这种物化操作,在oracle和mysql中存在.