吴恩达机器学习(Machine Learning)课程总结笔记---Week9
文章目录
- 0 概述
- 1. 课程大纲
- 2. 课程内容
- 2.1 异常检测
- 2.1.1 什么是异常检测
- 2.1.2 高斯分布
- 2.1.3 高斯分布算法
- 2.1.4 评估系统
- 2.1.5 异常检测和监督学习对比
- 2.1.6 特征选择
- 2.1.7 多元高斯分布
- 2.1.7.1 多元高斯分布模型
- 2.1.7.2 多元高斯分布的变化
- 2.1.7.2.1 改变$\Sigma$
- 2.1.7.2.1 改变$\mu$
- 2.1.7.3 算法流程
- 2.1.7.4 多元高斯分布模型与一般高斯分布模型的差异
- 2.1.7.4.1 模型定义
- 2.1.7.4.2 对比
- 2.2 推荐系统
- 2.2.1 假设函数和优化目标
- 2.2.2 协同过滤
- 2.2.2.1 协同过滤优化目标
- 2.2.2.2 算法流程
- 2.2.3 向量化:低秩矩阵分解
- 2.2.4 均值归一化
- 2.2.4.1 为什么采用均值归一化
- 2.2.4.2 均值归一化算法
- 3. 课后编程作业
- 4. 总结
0 概述
我们前边几章学习的基本上都属于机器学习算法范畴,本章将就两个机器学习应用实例来进行学习:异常检测和推荐系统。
二者都是机器学习的典型应用,让我们开始吧!
1. 课程大纲
2. 课程内容
2.1 异常检测
2.1.1 什么是异常检测
异常检测是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
比如,判断是一个飞机引擎出厂时候是否正常,异常检测问题就是:要知道这个新的飞机引擎 x t e s t x_{test} xtest 是否有某种异常,或者希望判断这个引擎是否需要进一步测试,希望知道新的数据 x t e s t x_{test} xtest 是不是异常的,即这个测试数据不属于该组数据的几率如何。
如下图所示:
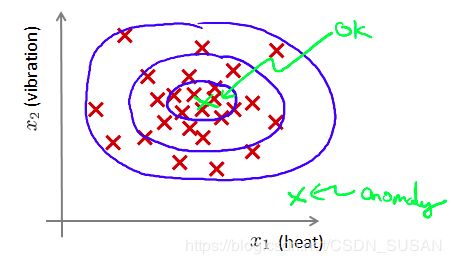
蓝圈内的数据属于该组数据的可能性较高,越是偏远的数据,属于该组数据的可能性就越低。
这种方法称为密度估计,表达如下:
i f p ( x ) { < ε anomaly > = ε normal if \quad p(x)\left\{\begin{array}{ll}{<\varepsilon} & {\text { anomaly }} \\ {>=\varepsilon} & {\text { normal }}\end{array}\right. ifp(x){<ε>=ε anomaly normal
典型的应用还有,
-
识别欺骗
例如在线采集而来的有关用户的数据,一个特征向量中可能会包含如:用户多久登录一次,访问过的页面,在论坛发布的帖子数量、甚至是打字速度等。尝试根据这些特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户 -
检测一个数据中心
特征可能包含:内存使用情况,被访问的磁盘数量,CPU 的负载,网络的通信量等。根据这些特征可以构建一个模型,用来判断某些计算机是不是有可能出错。
2.1.2 高斯分布
上一节我们知道,异常检测是通过所谓密度估计来判断一个新的样本是否是正常的。那么按什么分布来进行密度估计,就是一个关键问题。大部分情况下,我们可以假设样本符合高斯分布,然后按照高斯分布来处理新的检测样本,进行判断。
高斯分布,也叫作正态分布,假如 x 服从高斯分布,那么我们将表示为: x ∼ N ( μ , σ 2 ) x\sim N(\mu,\sigma^2) x∼N(μ,σ2) 。其分布概率为:
p ( x ; μ , σ 2 ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) p(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2}) p(x;μ,σ2)=2πσ1exp(−2σ2(x−μ)2)
其中 μ \mu μ 为期望值(均值), σ 2 \sigma^2 σ2 为方差。
-
期望值: μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum_{i=1}^{m}{x^{(i)}} μ=m1∑i=1mx(i)
-
方差: σ 2 = 1 m ∑ i = 1 m ( x ( i ) − μ ) 2 \sigma^2=\frac{1}{m}\sum_{i=1}^{m}{(x^{(i)}-\mu)}^2 σ2=m1∑i=1m(x(i)−μ)2
这里方差除以m而不是m-1,是因为虽然在统计学上两者的理论特性有所不同,但是在机器学习中两者区别很小,不影响最终结果。
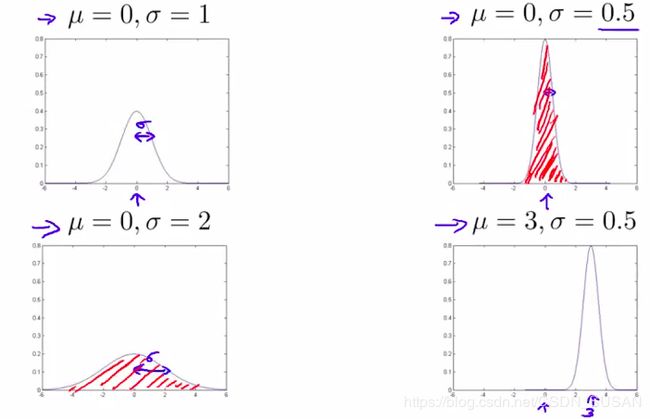
可以看到,
- μ \mu μ决定了高斯分布的中心点位置
- σ \sigma σ决定了高斯分布的峰值和宽度。
2.1.3 高斯分布算法
假如我们有一组 m 个无标签训练集,其中每个训练数据又有 n 个特征,那么这个训练集应该是 m 个 n 维向量构成的样本矩阵。
step 1 :在概率论中,对有限个样本进行参数估计
μ j = 1 m ∑ i = 1 m x j ( i ) , δ j 2 = 1 m ∑ i = 1 m ( x j ( i ) − μ j ) 2 \mu_j = \frac{1}{m} \sum_{i=1}^{m}x_j^{(i)}\;\;\;,\;\;\; \delta^2_j = \frac{1}{m} \sum_{i=1}^{m}(x_j^{(i)}-\mu_j)^2 μj=m1i=1∑mxj(i),δj2=m1i=1∑m(xj(i)−μj)2
这里对参数 μ \mu μ 和参数 δ 2 \delta^2 δ2 的估计就是二者的极大似然估计。
step 2: 假定每一个特征 x 1 x_{1} x1 到 x n x_{n} xn 均服从正态分布,则其模型的概率为:
p ( x ) = p ( x 1 ; μ 1 , σ 1 2 ) p ( x 2 ; μ 2 , σ 2 2 ) ⋯ p ( x n ; μ n , σ n 2 ) = ∏ j = 1 n p ( x j ; μ j , σ j 2 ) = ∏ j = 1 n 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) \begin{aligned} p(x) &=p\left(x_{1} ; \mu_{1}, \sigma_{1}^{2}\right) p\left(x_{2} ; \mu_{2}, \sigma_{2}^{2}\right) \cdots p\left(x_{n} ; \mu_{n}, \sigma_{n}^{2}\right) \\ &=\prod_{j=1}^{n} p\left(x_{j} ; \mu_{j}, \sigma_{j}^{2}\right) \\ &=\prod_{j=1}^{n} \frac{1}{\sqrt{2 \pi} \sigma_{j}} e x p\left(-\frac{\left(x_{j}-\mu_{j}\right)^{2}}{2 \sigma_{j}^{2}}\right) \end{aligned} p(x)=p(x1;μ1,σ12)p(x2;μ2,σ22)⋯p(xn;μn,σn2)=j=1∏np(xj;μj,σj2)=j=1∏n2πσj1exp(−2σj2(xj−μj)2)
当 p ( x ) < ε p(x)<\varepsilon p(x)<ε时, x x x位为异常样本。
假定我们有两个特征 x 1 x_1 x1 、 x 2 x_2 x2 ,它们都服从于高斯分布,并且通过参数估计,我们知道了分布参数: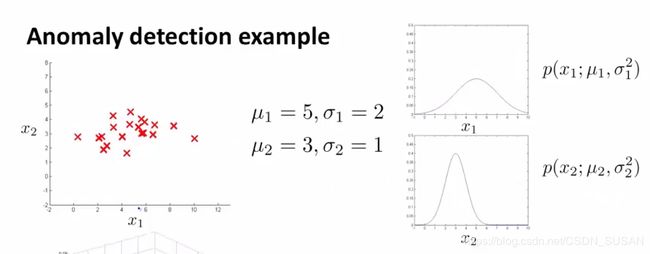
则模型 p ( x ) p(x) p(x) 能由如下的热力图反映,热力图越热的地方,是正常样本的概率越高,参数 ε \varepsilon ε 描述了一个截断高度,当概率落到了截断高度以下(下图紫色区域所示),则为异常样本:
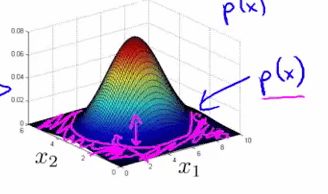
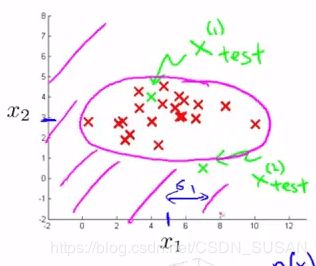
将 p ( x ) p(x) p(x) 投影到特征 x 1 x_1 x1 、 x 2 x_2 x2 所在平面,下图紫色曲线就反映了 ε \varepsilon ε 的投影,它是一条截断曲线,落在截断曲线以外的样本,都会被认为是异常样本:
2.1.4 评估系统
当开发一个异常检测系统时,从带标记(异常或正常)的数据着手,选择一部分正常数据用于构建训练集,用剩下的正常数据和异常数据混合构成交叉验证集和测试集。
例如:有 10000 台正常引擎的数据,有 20 台异常引擎的数据。 分配如下:
6000 台正常引擎的数据作为训练集
2000 台正常引擎和 10 台异常引擎的数据作为交叉检验集
2000 台正常引擎和 10 台异常引擎的数据作为测试集
由于异常样本是非常少的,所以整个数据集是非常偏斜的,不能单纯的用预测准确率来评估算法优劣
具体的评价方法如下:
- 根据测试集数据,估计特征的平均值和方差并构建 p ( x ) p(x) p(x)函数
- 对交叉验证集,尝试使用不同的 ϵ \epsilon ϵ值作为阀值,并预测数据是否异常,根据 F 1 F1 F1值或者查准率与召回率的比例来选择 ϵ \epsilon ϵ
- 选出 ϵ \epsilon ϵ后,针对测试集进行预测,计算异常检验系统的 F 1 F1 F1值,或者查准率与召回率之比
2.1.5 异常检测和监督学习对比
表格一是两者在数据特点上的对比。
| 有监督学习 | 异常检测 |
|---|---|
| 数据分布均匀 | 数据非常偏斜,异常样本数目远小于正常样本数目 |
| 可以根据对正样本的拟合来知道正样本的形态,从而预测新来的样本是否是正样本 | 异常的类型不一,很难根据对现有的异常样本(即正样本)的拟合来判断出异常样本的形态 |
表格二,是二者在应用场景上的对比。
| 有监督学习 | 异常检测 |
|---|---|
| 垃圾邮件检测 | 故障检测 |
| 天气预测(预测雨天、晴天、或是多云天气) | 某数据中心对于机器设备的监控 |
| 癌症的分类 | 制造业判断一个零部件是否异常 |
如果异常样本非常少,特征也不一样完全一样(比如今天飞机引擎异常是因为原因一,明天飞机引擎异常是因为原因二,谁也不知道哪天出现异常是什么原因),这种情况下就应该采用异常检测。
如果异常样本多,特征比较稳定有限,这种情况就应该采用监督学习。
2.1.6 特征选择
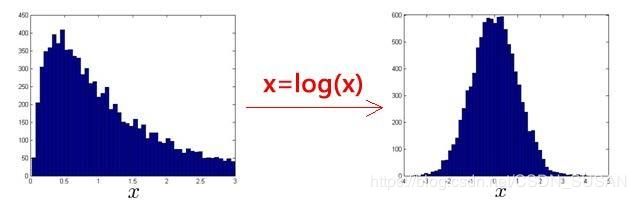
如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:
x = l o g ( x + c ) x = log(x+c) x=log(x+c),其中 c c c为非负常数; 或者 x = x c x = x^c x=xc, c c c 为 0 − 1 0-1 0−1 之间的一个分数。
误差分析:
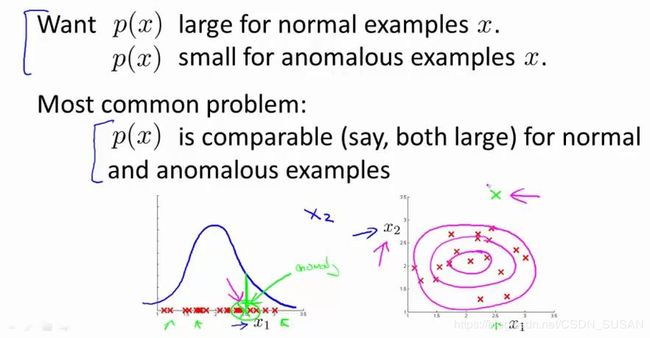
一个常见的问题是一些异常的数据可能也会有较高的p(x)p(x)值,因而被算法认为是正常的。这种情况下误差分析能够分析那些被算法错误预测为正常的数据,观察能否找出一些问题。可能能从问题中发现需要增加一些新的特征,增加这些新特征后获得的新算法能够更好地进行异常检测异常检测误差分析:
通常可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小),在检测数据中心的计算机状况的例子中,用 CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。
2.1.7 多元高斯分布
2.1.7.1 多元高斯分布模型
如图所示:
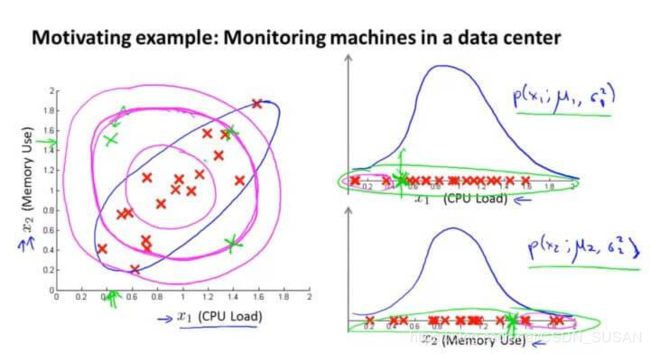
x 1 x_1 x1 是CPU的负载, x 2 x_2 x2 是内存的使用量。
其正常样本如左图红色点所示。假如我们有一个异常的样本(图中左上角绿色点),在图中看很明显它并不是正常样本所在的范围。但是在计算概率 p ( x ) p(x) p(x) 的时候,因为它在 x 1 x_1 x1 和 x 2 x_2 x2 的高斯分布都属于正常范围,所以该点并不会被判断为异常点。
这是因为在高斯分布中,它并不能察觉在蓝色椭圆处才是正常样本概率高的范围,其概率是通过圆圈逐渐向外减小。所以在同一个圆圈内,虽然在计算中概率是一样的,但是在实际上却往往有很大偏差。
所以我们开发了一种改良版的异常检测算法:多元高斯分布。
在一般的高斯分布模型中,计算 p ( x ) p(x) p(x)的方法是: 通过分别计算每个特征对应的几率然后将其累乘起来,在多元高斯分布模型中,将构建特征的协方差矩阵,用所有的特征一起来计算 p ( x ) p(x) p(x)其概率模型为: p ( x ; μ , Σ ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x;\mu,\Sigma)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)) p(x;μ,Σ)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ)) (其中 ∣ Σ ∣ |\Sigma| ∣Σ∣ 是 Σ \Sigma Σ 的行列式, μ \mu μ 表示样本均值, Σ \Sigma Σ 表示样本协方差矩阵。)
2.1.7.2 多元高斯分布的变化
多元高斯分布模型也同样遵循概率分布,曲线下方的积分等于1。多元高斯分布相当于体积为1 。这样就可以通过 μ \mu μ 和 Σ \Sigma Σ (这里是协方差矩阵,原来是 σ \sigma σ )的关系来判断图形的大致形状。
2.1.7.2.1 改变 Σ \Sigma Σ
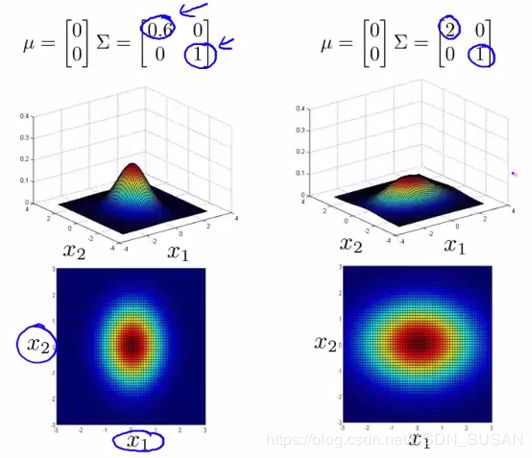
Σ \Sigma Σ 是一个协方差矩阵,所以它衡量的是方差。减小 Σ \Sigma Σ 其宽度也随之减少,增大反之。
- 改变 Σ \Sigma Σ主对角线的数值可以进行不同方向的宽度拉伸:
Σ \Sigma Σ 中第一个数字是衡量 x 1 x_1 x1 的,假如减少第一个数字,则可从图中观察到 x 1 x_1 x1 的范围也随之被压缩,变成了一个椭圆。
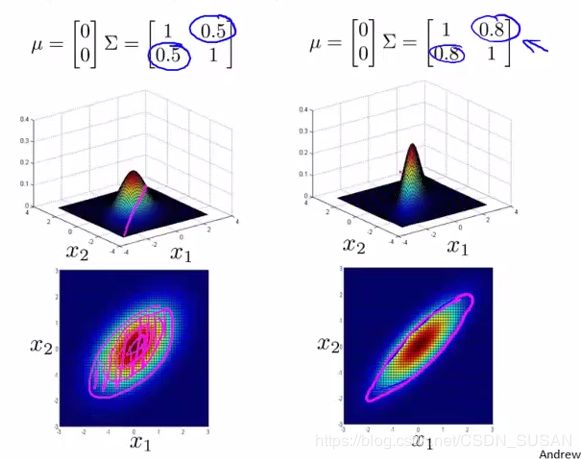
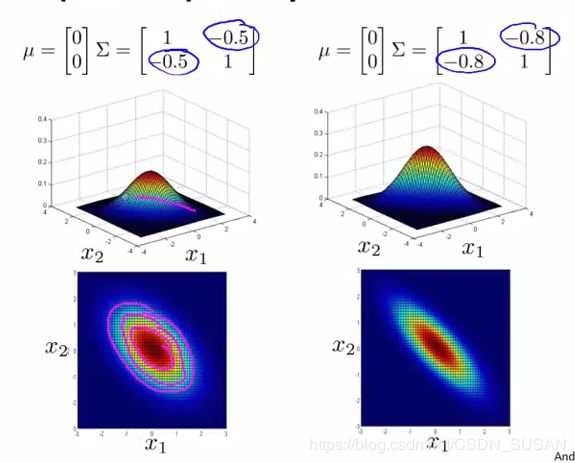
- 改变 Σ \Sigma Σ副对角线的数值可以旋转分布图像:
改变副对角线上的数据,则其图像会根据 y = x y=x y=x 这条直线上进行高斯分布。
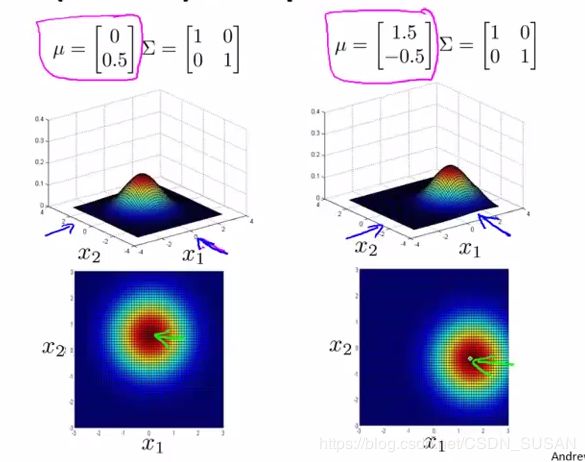
2.1.7.2.1 改变 μ \mu μ
改变 μ \mu μ可以对分布图像进行位移:
2.1.7.3 算法流程
采用了多元高斯分布的异常检测算法流程如下:
- 选择一些足够反映异常样本的特征 x j x_j xj 。
- 对各个样本进行参数估计: μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum_{i=1}^{m}{x^{(i)}} μ=m1i=1∑mx(i) Σ = 1 m ∑ i = 1 m ( x ( i ) − μ ) ( x ( i ) − μ ) T \Sigma=\frac{1}{m}\sum_{i=1}^{m}{(x^{(i)}-\mu)(x^{(i)}-\mu)^T} Σ=m1i=1∑m(x(i)−μ)(x(i)−μ)T
- 当新的样本 x 到来时,计算 p ( x ) p(x) p(x) :
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)) p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
如果 p ( x ) < ε p(x)<\varepsilon p(x)<ε ,则认为样本 x 是异常样本。
2.1.7.4 多元高斯分布模型与一般高斯分布模型的差异
一般的高斯分布模型只是多元高斯分布模型的一个约束,它将多元高斯分布的等高线约束到了如下所示同轴分布(概率密度的等高线是沿着轴向的):
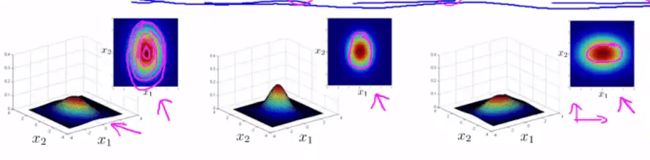
一般的多元高斯模型的轮廓(等高线)总是轴对齐的,也就是 Σ \Sigma Σ 除对角线以外的部分都是 0,当对角线以外的部分不为 0 的时候,等高线会出现斜着的,与两个轴产生一定的斜率。
当: Σ = [ σ 1 2 σ 2 2 σ n 2 ] \Sigma=\left[\begin{array}{cccc}{\sigma_{1}^{2}} & {} & {} & {} \\ {} & {\sigma_{2}^{2}} & {} & {} \\ {} & {} & {} & {\sigma_{n}^{2}}\end{array}\right] Σ=⎣⎡σ12σ22σn2⎦⎤的时候,此时的多元高斯分布即是原来的多元高斯分布。(因为只有主对角线方差,并没有其它斜率的变化)
2.1.7.4.1 模型定义
一般高斯模型:
p ( x ) = p ( x 1 ; μ 1 , σ 1 2 ) p ( x 2 ; μ 2 , σ 2 2 ) ⋯ p ( x n ; μ n , σ n 2 ) = ∏ j = 1 n p ( x j ; μ j , σ j 2 ) = ∏ j = 1 n 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) \begin{aligned} p(x) &=p\left(x_{1} ; \mu_{1}, \sigma_{1}^{2}\right) p\left(x_{2} ; \mu_{2}, \sigma_{2}^{2}\right) \cdots p\left(x_{n} ; \mu_{n}, \sigma_{n}^{2}\right) \\ &=\prod_{j=1}^{n} p\left(x_{j} ; \mu_{j}, \sigma_{j}^{2}\right) \\ &=\prod_{j=1}^{n} \frac{1}{\sqrt{2 \pi} \sigma_{j}} e x p\left(-\frac{\left(x_{j}-\mu_{j}\right)^{2}}{2 \sigma_{j}^{2}}\right) \end{aligned} p(x)=p(x1;μ1,σ12)p(x2;μ2,σ22)⋯p(xn;μn,σn2)=j=1∏np(xj;μj,σj2)=j=1∏n2πσj1exp(−2σj2(xj−μj)2)
多元高斯模型:
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)) p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
2.1.7.4.2 对比
| 一般高斯模型 | 多元高斯模型 |
|---|---|
| 需要手动创建一些特征来描述某些特征的相关性 | 利用协方差矩阵 Σ \Sigma Σ 获得了各个特征相关性 |
| 计算复杂度低,适用于高维特征 | 计算复杂 |
| 在样本数目 mm 较小时也工作良好 | 需要 Σ \Sigma Σ 可逆,亦即需要 m > n m>n m>n(通常会考虑 m > 10 n m>10 n m>10n,确保有足够多的数据去拟合这些变量,更好的去评估协方差矩阵 Σ \Sigma Σ ) 各个特征不能线性相关,如不能存在 x 2 = 3 x 1 x_2=3x_1 x2=3x1 或者 x 3 = x 1 + 2 x 2 x_3=x_1+2x_2 x3=x1+2x2 |
结论:基于多元高斯分布模型的异常检测应用十分有限。
2.2 推荐系统
对机器学习来说,特征是很重要的,选择的特征,将对学习算法的性能有很大的影响。
如下图,每个人对电影的评分,我们需要预测某个用户对未看过的电影的可能评分。
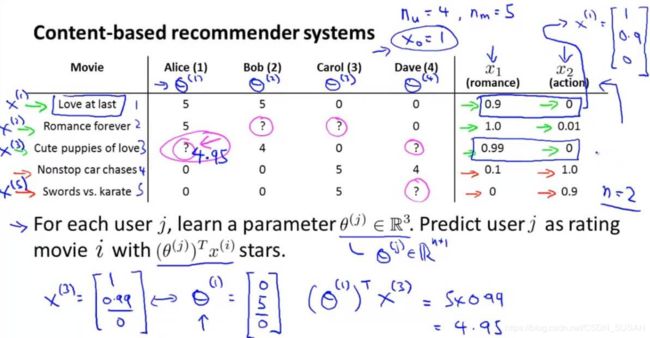
以预测第3部电影第1个用户可能评的分数为例子。
首先我们用 x 1 x_1 x1 表示爱情浪漫电影类型, x 2 x_2 x2 表示动作片类型。上图左表右侧则为每部电影对于这两个分类的相关程度。我们默认 x 0 = 1 x_0=1 x0=1 。则第一部电影与两个类型的相关程度可以这样表示: x ( 3 ) = [ 1 0.99 0 ] x^{(3)}=\left[ \begin{array}{ccc}1 \\0.99 \\0 \end{array} \right] x(3)=⎣⎡10.990⎦⎤ 。然后用 θ ( j ) \theta^{(j)} θ(j) 表示第 j 个用户对于该种类电影的评分。这里我们假设已经知道(详情下面再讲) θ ( 1 ) = [ 0 5 0 ] \theta^{(1)}=\left[ \begin{array}{ccc}0 \\5 \\0 \end{array} \right] θ(1)=⎣⎡050⎦⎤ ,那么我们用 ( θ ( j ) ) T x ( i ) (\theta^{(j)})^Tx^{(i)} (θ(j))Tx(i) 即可计算出测第3部电影第1个用户可能评的分数。这里计算出是4.95。
2.2.1 假设函数和优化目标
假设函数:
假设对每一个用户,都训练一个线性回归模型,如下:
y ( i , j ) = ( θ ( j ) ) T x ( i ) y^{(i, j)}=\left(\theta^{(j)}\right)^{T} x^{(i)} y(i,j)=(θ(j))Tx(i)
其中, θ ( j ) \theta^{(j)} θ(j)是用户 j j j的参数向量; x ( i ) x^{(i)} x(i)是电影 i i i的特征向量。
优化目标:
针对用户 j 打分状况作出预测,我们需要:
min ( θ ( j ) ) = 1 2 ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T ( x ( i ) ) − y ( i , j ) ) 2 + λ 2 ∑ k = 1 n ( θ k ( j ) ) 2 \min_{(\theta^{(j)})}=\frac{1}{2}\sum_{i:r(i,j)=1}^{}{((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2}+\frac{\lambda}{2}\sum_{k=1}^{n}{(\theta_k^{(j)})^2} (θ(j))min=21i:r(i,j)=1∑((θ(j))T(x(i))−y(i,j))2+2λk=1∑n(θk(j))2
其中, i : r ( i , j ) = 1 i : r(i, j)=1 i:r(i,j)=1,表示只计算用户 j j j评价过的电影。
在一般的线性回归模型中,误差项和正则想都应该乘以 1 2 m \frac{1}{2 m} 2m1,在这里将 m m m去掉,并且不对 θ 0 ( j ) \theta_{0}^{(j)} θ0(j)进行正则化处理,对所有用户 1 , 2 , … , n u 1,2, \ldots, n_{u} 1,2,…,nu计算代价函数:
J ( θ ( 1 ) , ⋯ , θ ( n u ) ) = min ( θ ( 1 ) , ⋯ , θ ( n u ) ) = 1 2 ∑ j = 1 n u ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T ( x ( i ) ) − y ( i , j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 J(\theta^{(1)},\cdots,\theta^{(n_u)})=\min_{(\theta^{(1)},\cdots,\theta^{(n_u)})}=\frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}^{}{((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2}+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^{n}{(\theta_k^{(j)})^2} J(θ(1),⋯,θ(nu))=(θ(1),⋯,θ(nu))min=21j=1∑nui:r(i,j)=1∑((θ(j))T(x(i))−y(i,j))2+2λj=1∑nuk=1∑n(θk(j))2
与前面所学线性回归内容的思路一致,为了计算出 J ( θ ( 1 ) , ⋯ , θ ( n u ) ) J(\theta^{(1)},\cdots,\theta^{(n_u)}) J(θ(1),⋯,θ(nu)),使用梯度下降法来更新参数:
更新偏置(插值):
θ 0 ( j ) = θ 0 ( j ) − α ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) x 0 ( i ) \theta^{(j)}_0=\theta^{(j)}_0-\alpha \sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i,j)})x^{(i)}_0 θ0(j)=θ0(j)−αi:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))x0(i)
更新权重:
θ k ( j ) = θ k ( j ) − α ( ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) x k ( i ) + λ θ k ( j ) ) , k ≠ 0 \theta^{(j)}_k=\theta^{(j)}_k-\alpha \left( \sum_{i:r(i,j)=1}((\theta^{(j)})^Tx^{(i)}-y^{(i,j)})x^{(i)}_k+\lambda \theta^{(j)}_k \right),\;\;\; k \neq 0 θk(j)=θk(j)−α⎝⎛i:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))xk(i)+λθk(j)⎠⎞,k̸=0
其中, n u n_{u} nu代表用户的数量; n m n_{m} nm代表电影的数量; r ( i , j ) r(i, j) r(i,j)如果用户 j j j给电影评过分则 r ( i , j ) = 1 r(i, j)=1 r(i,j)=1; y ( i , j ) y^{(i, j)} y(i,j)代表用户 j j j给电影 i i i的评分; m ( j ) m^{(j)} m(j)代表用户 j j j评过分的电影的总数;
2.2.2 协同过滤
拥有了评价用户的 θ \theta θ和评价商品的 x x x,因此可以做到,
- 给定 θ \theta θ及用户对商品的评价,可以估计 x x x;
- 给定 x x x及用户对商品的评价,可以估计 θ \theta θ。
这样就构成了 θ → x → θ → x . . \theta \rightarrow x \rightarrow \theta \rightarrow x . . θ→x→θ→x..优化序列,构成了协同过滤算法,即能够同时优化 θ \theta θ和 x x x。
2.2.2.1 协同过滤优化目标
- 推测用户喜好,给定 x ( 1 ) , … , x ( n m ) x^{(1)}, \ldots, x^{\left(n_{m}\right)} x(1),…,x(nm),估计 θ ( 1 ) , … , θ ( n u ) \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)} θ(1),…,θ(nu):
min θ ( 1 ) , … , θ ( n u ) = 1 2 ∑ j = 1 n u ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) 2 + λ 2 ∑ j = 1 n u ∑ k = 1 n ( θ k ( j ) ) 2 \min _{\theta(1), \ldots, \theta^{\left(n_{u}\right)}}=\frac{1}{2} \sum_{j=1}^{n_{u}} \sum_{i : r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right)^{2}+\frac{\lambda}{2} \sum_{j=1}^{n_{u}} \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2} θ(1),…,θ(nu)min=21j=1∑nui:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λj=1∑nuk=1∑n(θk(j))2 - 推测商品内容,给定 θ ( 1 ) , … , θ ( n u ) \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)} θ(1),…,θ(nu),估计 x ( 1 ) , … , x ( n m ) x^{(1)}, \ldots, x^{\left(n_{m}\right)} x(1),…,x(nm):
min x ( i ) , … , x ( n m ) = 1 2 ∑ i = 1 n m ∑ j : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k = 1 n ( x k ( i ) ) 2 \min _{x^{(i)}, \ldots, x^{\left(n_{m}\right)}}=\frac{1}{2} \sum_{i=1}^{n_{m}} \sum_{j : r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right)^{2}+\frac{\lambda}{2} \sum_{i=1}^{n_{m}} \sum_{k=1}^{n}\left(x_{k}^{(i)}\right)^{2} x(i),…,x(nm)min=21i=1∑nmj:r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λi=1∑nmk=1∑n(xk(i))2 - 协同过滤,同时优化 x ( 1 ) , … , x ( n m ) x^{(1)}, \ldots, x^{\left(n_{m}\right)} x(1),…,x(nm)及 θ ( 1 ) , … , θ ( n u ) \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)} θ(1),…,θ(nu):
J ( x ( 1 ) , … x ( n n ) , θ ( 1 ) , … , θ ( n n ) ) = 1 2 ∑ ( i , j ) ∗ r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k = 1 n ( x k ( j ) ) 2 + λ 2 ∑ j = 1 n i ∑ k = 1 n ( θ k ( j ) ) 2 J\left(x^{(1)}, \ldots x^{\left(n_{n}\right)}, \theta^{(1)}, \ldots, \theta^{\left(n_{n}\right)}\right)=\frac{1}{2} \sum_{(i, j) * r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right)^{2}+\frac{\lambda}{2} \sum_{i=1}^{n_{m}} \sum_{k=1}^{n}\left(x_{k}^{(j)}\right)^{2}+\frac{\lambda}{2} \sum_{j=1}^{n_{i}} \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2} J(x(1),…x(nn),θ(1),…,θ(nn))=21(i,j)∗r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λi=1∑nmk=1∑n(xk(j))2+2λj=1∑nik=1∑n(θk(j))2
2.2.2.2 算法流程
Step 1:初始化 x ( 1 ) , … , x ( n m ) , θ ( 1 ) , … , θ ( n u ) x^{(1)}, \ldots, x^{\left(n_{m}\right)}, \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)} x(1),…,x(nm),θ(1),…,θ(nu)为随机小值。
Step 2:使用梯度下降法最小化代价函数,
x k ( i ) : = x k ( i ) − α ( ∑ j : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) θ k j + λ x k ( i ) ) x_{k}^{(i)} :=x_{k}^{(i)}-\alpha\left(\sum_{j : r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)} \theta_{k}^{j}+\lambda x_{k}^{(i)}\right)\right. xk(i):=xk(i)−α(∑j:r(i,j)=1((θ(j))Tx(i)−y(i,j)θkj+λxk(i))
θ k ( i ) : = θ k ( i ) − α ( ∑ i : r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) x k ( i ) + λ θ k ( j ) ) \theta_{k}^{(i)} :=\theta_{k}^{(i)}-\alpha\left(\sum_{i : r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)} x_{k}^{(i)}+\lambda \theta_{k}^{(j)}\right)\right. θk(i):=θk(i)−α(∑i:r(i,j)=1((θ(j))Tx(i)−y(i,j)xk(i)+λθk(j))
Step 3:如果用户偏好向量为 θ \theta θ,而商品的特征为 x x x,则可以预测用户的评价为 θ T x \theta^{T} x θTx。
因为协同过滤算法 θ \theta θ 和 x 相互影响,因此,二者都没必要使用偏置 θ 0 \theta_0 θ0 和 x 0 x_0 x0,即, x ∈ R n x \in \mathbb{R}^n x∈Rn、 θ ∈ R n \theta \in \mathbb{R}^n θ∈Rn 。
2.2.3 向量化:低秩矩阵分解
将下图中,用户对电影的评价表示成为一个矩阵 Y Y Y.
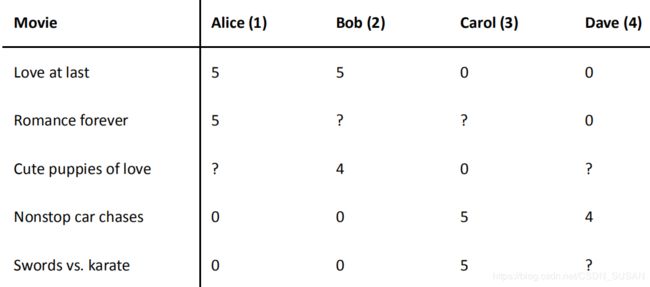
Y = [ 5 5 0 0 5 ? ? 0 ? 4 0 ? 0 0 5 4 0 0 5 0 ] Y=\left[\begin{array}{llll}{5} & {5} & {0} & {0} \\ {5} & {?} & {?} & {0} \\ {?} & {4} & {0} & {?} \\ {0} & {0} & {5} & {4} \\ {0} & {0} & {5} & {0}\end{array}\right] Y=⎣⎢⎢⎢⎢⎡55?005?4000?05500?40⎦⎥⎥⎥⎥⎤
预测矩阵为,
Predicated = [ ( θ ( 1 ) ) T x ( 1 ) ( θ ( 2 ) ) T x ( 1 ) … ( θ ( n u ) ) T x ( 1 ) ( θ ( 1 ) ) T x ( 2 ) ( θ ( 2 ) ) T x ( 2 ) … ( θ ( n u ) ) T x ( 2 ) ⋮ ⋮ ⋮ ⋮ ( θ ( 1 ) ) T x ( n m ) ( θ ( 2 ) ) T x ( n m ) … ( θ ( n u ) ) T x ( n m ) ] \operatorname{Predicated}=\left[\begin{array}{cccc}{\left(\theta^{(1)}\right)^{T} x^{(1)}} & {\left(\theta^{(2)}\right)^{T} x^{(1)}} & {\dots} & {\left(\theta^{\left(n_{u}\right)}\right)^{T} x^{(1)}} \\ {\left(\theta^{(1)}\right)^{T} x^{(2)}} & {\left(\theta^{(2)}\right)^{T} x^{(2)}} & {\dots} & {\left(\theta^{\left(n_{u}\right)}\right)^{T} x^{(2)}} \\ {\vdots} & {\vdots} & {\vdots} & {\vdots} \\ {\left(\theta^{(1)}\right)^{T} x^{\left(n_{m}\right)}} & {\left(\theta^{(2)}\right)^{T} x^{\left(n_{m}\right)}} & {\dots} & {\left(\theta^{\left(n_{u}\right)}\right)^{T} x^{\left(n_{m}\right)}}\end{array}\right] Predicated=⎣⎢⎢⎢⎢⎡(θ(1))Tx(1)(θ(1))Tx(2)⋮(θ(1))Tx(nm)(θ(2))Tx(1)(θ(2))Tx(2)⋮(θ(2))Tx(nm)……⋮…(θ(nu))Tx(1)(θ(nu))Tx(2)⋮(θ(nu))Tx(nm)⎦⎥⎥⎥⎥⎤
这里,令
X = [ ( x ( 1 ) ) T ( x ( 2 ) ) T ⋮ ( x ( n m ) ) T ] , Θ = [ ( θ ( 1 ) ) T ( θ ( 2 ) ) T ⋮ ( θ ( n u ) ) T ] X=\left[\begin{array}{c}{\left(x^{(1)}\right)^{T}} \\ {\left(x^{(2)}\right)^{T}} \\ {\vdots} \\ {\left(x^{\left(n_{m}\right)}\right)^{T}}\end{array}\right], \Theta=\left[\begin{array}{c}{\left(\theta^{(1)}\right)^{T}} \\ {\left(\theta^{(2)}\right)^{T}} \\ {\vdots} \\ {\left(\theta^{\left(n_{u}\right)}\right)^{T}}\end{array}\right] X=⎣⎢⎢⎢⎢⎡(x(1))T(x(2))T⋮(x(nm))T⎦⎥⎥⎥⎥⎤,Θ=⎣⎢⎢⎢⎢⎡(θ(1))T(θ(2))T⋮(θ(nu))T⎦⎥⎥⎥⎥⎤
即 X X X的每一行描述了一部电影的特征, θ T \theta^{T} θT的每一列描述了用户喜好参数,因此预测可以写为:
P r i d i c t e d = Θ T X Pridicted = \Theta^{T} X Pridicted=ΘTX
这个算法是协同过滤的向量化,也称为低秩矩阵分解(因为 Θ \Theta Θ不是满秩矩阵)。
2.2.4 均值归一化
2.2.4.1 为什么采用均值归一化
如下图所示:
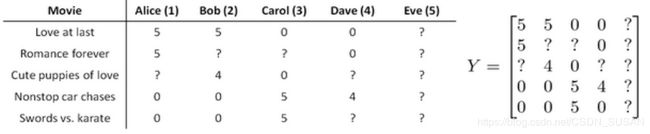
如果我们新增一个用户 Eve,并且 Eve 没有为任何电影评分,那么我们以什么为依据为 Eve 推荐电影呢?
事实上,根据最小化代价函数求解 θ ( 5 ) \theta^{(5)} θ(5):
J ( x ( 1 ) , … x ( n n ) , θ ( 1 ) , … , θ ( n n ) ) = 1 2 ∑ ( i , j ) ∗ r ( i , j ) = 1 ( ( θ ( j ) ) T x ( i ) − y ( i , j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k = 1 n ( x k ( j ) ) 2 + λ 2 ∑ j = 1 n i ∑ k = 1 n ( θ k ( j ) ) 2 J\left(x^{(1)}, \ldots x^{\left(n_{n}\right)}, \theta^{(1)}, \ldots, \theta^{\left(n_{n}\right)}\right)=\frac{1}{2} \sum_{(i, j) * r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right)^{2}+\frac{\lambda}{2} \sum_{i=1}^{n_{m}} \sum_{k=1}^{n}\left(x_{k}^{(j)}\right)^{2}+\frac{\lambda}{2} \sum_{j=1}^{n_{i}} \sum_{k=1}^{n}\left(\theta_{k}^{(j)}\right)^{2} J(x(1),…x(nn),θ(1),…,θ(nn))=21(i,j)∗r(i,j)=1∑((θ(j))Tx(i)−y(i,j))2+2λi=1∑nmk=1∑n(xk(j))2+2λj=1∑nik=1∑n(θk(j))2
由于 r ( i , j ) = 0 r^{(i,j)}=0 r(i,j)=0,因此真正有效的项是 λ 2 [ ( θ 1 ( 5 ) ) 2 + ( θ 2 ( 5 ) ) 2 ] \frac{\lambda}{2}\left[\left(\theta_{1}^{(5)}\right)^{2}+\left(\theta_{2}^{(5)}\right)^{2}\right] 2λ[(θ1(5))2+(θ2(5))2],因此得到的 θ ( 5 ) = [ 0 0 ] \theta^{(5)}=\left[\begin{array}{l}{0} \\ {0}\end{array}\right] θ(5)=[00]。
这样,就导致了计算出来的结果 y ( i , 5 ) = 0 y^{(i, 5)} = 0 y(i,5)=0,意味着什么电影都不推荐,这显然是不符合预想的。
因此,可以采用均值归一化解决这个问题。
2.2.4.2 均值归一化算法
Step 1:先求取各个电影的平均得分 μ \mu μ:
μ = ( 2.5 2.5 2 2.25 1.25 ) \mu=\left(\begin{array}{c}{2.5} \\ {2.5} \\ {2} \\ {2.25} \\ {1.25}\end{array}\right) μ=⎝⎜⎜⎜⎜⎛2.52.522.251.25⎠⎟⎟⎟⎟⎞
Step 2:对Y进行均值归一化:
Y = Y − μ = [ 2.5 2.5 − 2.5 − 2.5 ? 2.5 ? ? − 2.5 ? ? − 2 − 2 ? ? − 2.25 − 2.25 2.75 1.75 ? − 1.25 − 1.25 3.75 − 1.25 ? ] Y=Y-\mu=\left[\begin{array}{ccccc}{2.5} & {2.5} & {-2.5} & {-2.5} & {?} \\ {2.5} & {?} & {?} & {-2.5} & {?} \\ {?} & {-2} & {-2} & {?} & {?} \\ {-2.25} & {-2.25} & {2.75} & {1.75} & {?} \\ {-1.25} & {-1.25} & {3.75} & {-1.25} & {?}\end{array}\right] Y=Y−μ=⎣⎢⎢⎢⎢⎡2.52.5?−2.25−1.252.5?−2−2.25−1.25−2.5?−22.753.75−2.5−2.5?1.75−1.25?????⎦⎥⎥⎥⎥⎤
Step 3:求解 θ ( 5 ) = [ 0 0 ] \theta^{(5)}=\left[\begin{array}{l}{0} \\ {0}\end{array}\right] θ(5)=[00]。
Step 4:计算 y ( i , 5 ) = ( θ ( 5 ) ) T x ( i ) + μ i = μ i y^{(i, 5)}=\left(\theta^{(5)}\right)^{T} x^{(i)}+\mu_{i}=\mu_{i} y(i,5)=(θ(5))Tx(i)+μi=μi
也就是说在未给定任何评价的时候,我们用其他用户的平均评价来作为该用户的默认评价。
貌似利用均值标准化让用户的初始评价预测客观了些,但这也是盲目的,不准确的。实际环境中,如果一个电影确实没被评价过,那么它没有任何理由被推荐给用户。
3. 课后编程作业
我将课后编程作业的参考答案上传到了github上,包括了octave版本和python版本,大家可参考使用。
https://github.com/GH-SUSAN/Machine-Learning-MarkDown/tree/master/week9
4. 总结
本周学习了机器学习的两个重要应用,异常检测和推荐系统。推荐系统虽然学术上的关注比较少,但实际应用却很多,值得关注。