【学习笔记】NLP之影评情感分类
本文对影评数据进行NLP情感分类,数据分为标注数据(含sentiment)和非标注数据(不含sentiment),数据25000条,列出前五条如下:

自然语言处理和文本分析的问题中,词袋(Bag of Words, BOW)和词向量(Word Embedding)是两种最常用的模型。对模型的讲解,可以参考博客:http://blog.csdn.net/wangongxi/article/details/51591031。下文程序采用Jupyter Notebook编辑。
一、词袋模型
import os
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import itertools
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
import nltk
from nltk.corpus import stopwords
df = pd.read_csv('../data/labeledTrainData.tsv', sep='\t', escapechar='\\')
print('Number of reviews: {}'.format(len(df)))
stopwords = {}.fromkeys([ line.rstrip() for line in open('../stopwords.txt')])
eng_stopwords = set(stopwords)
def clean_text(text):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
words = [w for w in words if w not in eng_stopwords]
return ' '.join(words)
df['clean_review'] = df.review.apply(clean_text)
vectorizer = CountVectorizer(max_features = 5000)
train_data_features = vectorizer.fit_transform(df.clean_review).toarray()
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train, y_train)
y_pred = LR_model.predict(X_test)
cnf_matrix = confusion_matrix(y_test,y_pred)
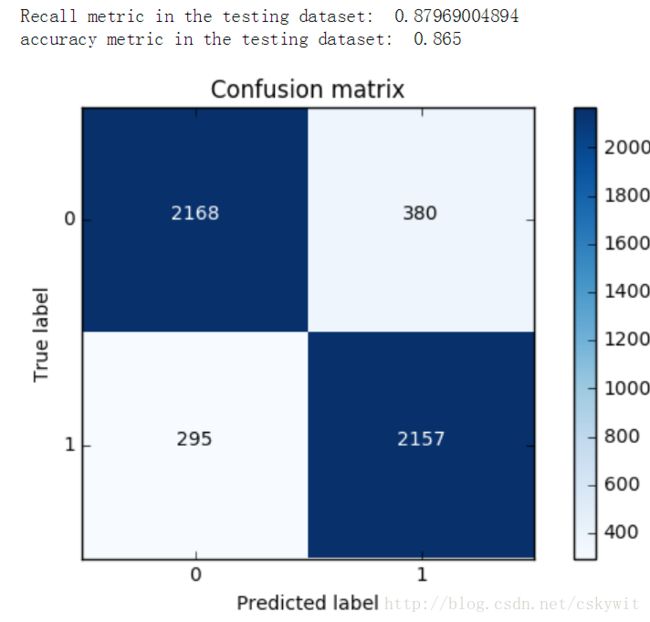
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
结果如下:

2、Word2Vec模型
#训练模型
import os
import re
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
import nltk
from nltk.corpus import stopwords
df = pd.read_csv('../data/unlabeledTrainData.tsv', sep='\t', escapechar='\\')
print('Number of reviews: {}'.format(len(df)))
df['clean_review'] = df.review.apply(clean_text)
review_part = df['clean_review']
import warnings
warnings.filterwarnings("ignore")
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
def split_sentences(review):
raw_sentences = tokenizer.tokenize(review.strip())
sentences = [clean_text(s) for s in raw_sentences if s]
return sentences
sentences = sum(review_part.apply(split_sentences), [])
sentences_list = []
for line in sentences:
sentences_list.append(nltk.word_tokenize(line))
# 设定词向量训练的参数
num_features = 300 # Word vector dimensionality
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)
from gensim.models.word2vec import Word2Vec
model = Word2Vec(sentences_list, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context)
# If you don't plan to train the model any further, calling
# init_sims will make the model much more memory-efficient.
model.init_sims(replace=True)
# It can be helpful to create a meaningful model name and
# save the model for later use. You can load it later using Word2Vec.load()
model.save(os.path.join('..', 'models', model_name))
print(model.doesnt_match(['man','woman','child','kitchen']))
[('girl', 0.7018299698829651),
('astro', 0.6647905707359314),
('teenage', 0.6317306160926819),
('frat', 0.60948246717453),
('dad', 0.6011481285095215),
('yr', 0.6010577082633972),
('teenager', 0.5974895358085632),
('brat', 0.5941195487976074),
('joshua', 0.5832049250602722),
('father', 0.5825375914573669)]#使用模型进行回归
df = pd.read_csv('../data/labeledTrainData.tsv', sep='\t', escapechar='\\')
from nltk.corpus import stopwords
eng_stopwords = set(stopwords.words('english'))
def clean_text(text, remove_stopwords=False):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
if remove_stopwords:
words = [w for w in words if w not in eng_stopwords]
return words
def to_review_vector(review):
global word_vec
review = clean_text(review, remove_stopwords=True)
#print (review)
#words = nltk.word_tokenize(review)
word_vec = np.zeros((1,300))
for word in review:
#word_vec = np.zeros((1,300))
if word in model:
word_vec += np.array([model[word]])
#print (word_vec.mean(axis = 0))
return pd.Series(word_vec.mean(axis = 0))
train_data_features = df.review.apply(to_review_vector)
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data_features,df.sentiment,test_size = 0.2, random_state = 0)
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train, y_train)
y_pred = LR_model.predict(X_test)
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()