爬虫学习之15:多进程爬取58二手交易市场数据保存到mongodb,并实现简单断点续爬
本代码继续使用多进程的方式爬取58同城二手交易数据,并保存到mongoDB,在爬取商品详情时,使用Python集合操作来实现简单的断点续爬。
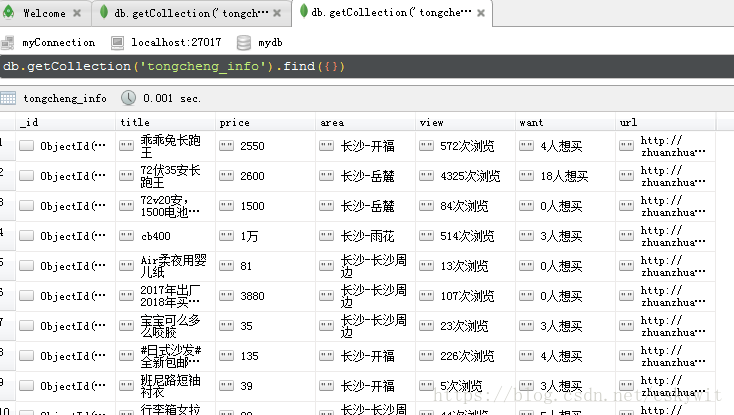
25二手市场如图
首先要获取不同频道的链接,编写代码channel_extract.py获取左边大类导航的链接,底下的channel_list是用代码爬取出来的,为了方便后面用,直接print出来用三引号转换为多行字符串。
import requests
from lxml import etree
start_url = 'http://cs.58.com/sale.shtml'
url_host = 'http://cs.58.com/'
#获取二手商品类目-+
def get_channel_urls(url):
html = requests.get(url)
selector = etree.HTML(html.text)
infos = selector.xpath('//*[@id="ymenu-side"]/ul/li')
for info in infos:
class_urls = info.xpath('span/a/@href')
for class_url in class_urls:
print(url_host+class_url)
#get_channel_urls(start_url)
channel_list="""
http://cs.58.com//shouji/
http://cs.58.com//tongxunyw/
http://cs.58.com//danche/
http://cs.58.com//diandongche/
http://cs.58.com//diannao/
http://cs.58.com//shuma/
http://cs.58.com//jiadian/
http://cs.58.com//ershoujiaju/
http://cs.58.com//yingyou/
http://cs.58.com//fushi/
http://cs.58.com//meirong/
http://cs.58.com//yishu/
http://cs.58.com//tushu/
http://cs.58.com//wenti/
http://cs.58.com//kaquan/
http://cs.58.com//shebei.shtml
http://cs.58.com//chengren/
"""
编写页面爬取函数,如进入手机频道,爬取各个手机的链接,由get_links函数实现
并需要进入商品详情页获取商品标题,价格、地址,浏览人数,想要的人数。由get_info()函数实现。
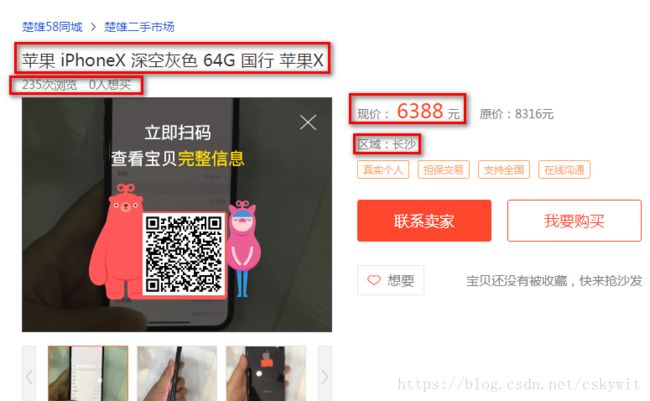
以上两个函数均写在page_spider.py中
import requests
from lxml import etree
import time
import pymongo
client = pymongo.MongoClient('localhost',27017)
mydb = client['mydb']
tongcheng_url = mydb['tongcheng_url']
tongcheng_info = mydb['tongcheng_info']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36',
'Connection':'keep-alive'
}
#获取商品URL的函数
def get_links(channel,pages):
list_view = '{}pn{}/'.format(channel,str(pages))
try:
html = requests.get(list_view,headers=headers)
time.sleep(2)
selector = etree.HTML(html.text)
if selector.xpath('//tr'):
infos = selector.xpath('//tr')
for info in infos:
if info.xpath('td[2]/a/@href'):
url = info.xpath('td[2]/a/@href')[0]
tongcheng_url.insert_one({'url':url})
else:
pass
else:
pass
except requests.exceptions.ConnectionError:
pass #pass掉请求连接错误
#获取商品详细信息
def get_info(url):
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
try:
title = selector.xpath('//h1/text()')[0]
if selector.xpath('//span[@class="price_now"]/i/text()'):
price = selector.xpath('//span[@class="price_now"]/i/text()')[0]
else:
price = "无价格"
if selector.xpath('//div[@class="palce_li"]/span/i/text()'):
area = selector.xpath('//div[@class="palce_li"]/span/i/text()')[0]
else:
area ="无区域"
view = selector.xpath('//p/span[1]/text()')[0]
if selector.xpath('//p/span[2]/text()'):
want = selector.xpath('//p/span[2]/text()')[0]
else:
want ="无人想要"
info = {
'title':title,
'price':price,
'area':area,
'view':view,
'want':want,
'url':url
}
tongcheng_info.insert_one(info)
except IndexError:
pass编写获取并存储商品url的文件,将URL存储到MongoDB的mydb数据库下的tongcheng_url collection下,数据量由点大,耗时较长。
##爬取所有商品url并存储在mongodb
import sys
sys.path.append("..")
from multiprocessing import Pool
from page_spider import get_links
from channel_extract import channel_list
def get_all_links_from(channel):
for num in range(1,101):
get_links(channel,num)
if __name__=='__main__':
pool = Pool(processes=4)
pool.map(get_all_links_from,channel_list.split())
从下图可见数据量之大:

编写获取所有商品详情的代码,将数据存入MongoDB的tongcheng_info collection,,在爬取数据过程中可能被网站方中断,使用set之差实现简单的断点续传,可以多次运行爬虫,每次都会从没有爬取过的URL继续。
import sys
sys.path.append("..")
from multiprocessing import Pool
from page_spider import get_info
from page_spider import tongcheng_url
from page_spider import tongcheng_info
db_urls = [item['url'] for item in tongcheng_url.find()]
db_infos = [item['url'] for item in tongcheng_info.find()]
#通过两个集合相减,实现断点续爬
x = set(db_urls)
y = set(db_infos)
rest_urls = x-y
if __name__=='__main__':
pool =Pool(processes=4)
pool.map(get_info,rest_urls)部分结果截图如下: