爬虫学习之16:爬取简书网用户动态信息(异步加载页面的爬取)
网上很多页面均采用异步加载,采用普通的request方法得不到结果。使用Chrome浏览器的Network选项卡可以查看网页加载过程中的所有文件信息,通过对这些文件的查看和筛选,就可以找出需抓取的数据,另外,异步加载网页的分页文件大部分在XHR(可扩展超文本传输请求)中,选中该选项,在向下滑动网页的过程中可以发现在加载文件,这些文件的header部分即为分页的URL,Response部分即为动态加载的网页的内容。以简书网某一用户的页面为例观察XHR 特点:
第一页:
Request URL:https://www.jianshu.com/users/9104ebf5e177/timeline?_pjax=%23list-container
最后一个
第二页:
Request URL:https://www.jianshu.com/users/9104ebf5e177/timeline?max_id=320645424&page=2
最后一个
第三页:
Request URL:https://www.jianshu.com/users/9104ebf5e177/timeline?max_id=317062800&page=3
最后一个
第四页:
Request URL:https://www.jianshu.com/users/9104ebf5e177/timeline?max_id=313597010&page=4
最后一个
从URL规律可以发现,其中的max_id是上一页的最后一个
import requests
from lxml import etree
import pymongo
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36'
}
client = pymongo.MongoClient('localhost',27017)
mydb = client['mydb']
timeline = mydb['timeline']
def get_time_info(url,page):
#从链接获取用户id
user_id = url.split('/')[4]
if url.find('page='):
page = page+1
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//ul[@class="note-list"]/li')
for info in infos:
dd = info.xpath('div/div/div/span/@data-datetime')[0]
type = info.xpath('div/div/div/span/@data-type')[0]
timeline.insert_one({'data':dd,'type':type})
id_infos =selector.xpath('//ul[@class="note-list/li/@id"]')
if len(id_infos)>1:
feed_id =id_infos[-1]
max_id = feed_id.split('-')[1]
next_url = 'https://www.jianshu.com/users/%s/timeline?max_id=%s&page=%s ' % (user_id,str(max_id-1),page)
get_time_info(next_url,page)
if __name__=='__main__':
get_time_info('https://www.jianshu.com/users/9104ebf5e177/timeline',1)
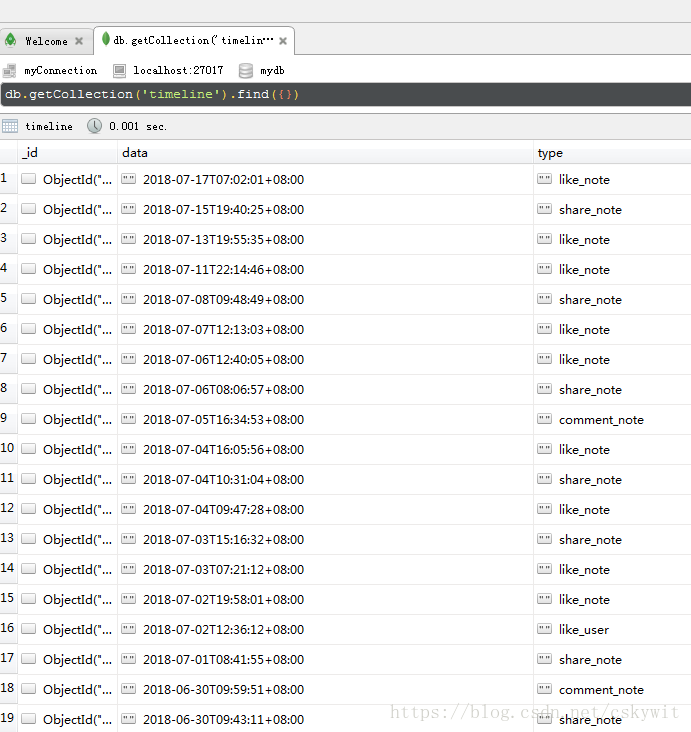
结果如下: