论文笔记-MTCNN-Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Network
MTCNN-Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Network.
2016.11 Kaipeng Zhang.
https://kpzhang93.github.io/MTCNN_face_detection_alignment/
https://github.com/kpzhang93/MTCNN_face_detection_alignment
摘要
由于多样性的姿势、照明和场景,在非约束环境下人脸检测和校准具有一定挑战性。最近研究表明深度学习方法可以在这两个任务上达到很好的效果。本文提出一个deep cascaded multi-task 框架,利用它们之间内在的联系提高性能。本框架采用一个有三阶段精心设计的深度卷积网络的级联架构以coarse-to-fine形式去预测人脸和关键点定位。另外,在学习过程中,本文提出一个新的online hard sample mining strategy可以不用手动采样选择而自动改善性能。
Introduction
本文提出一个新的框架使用统一的级联CNN通过多任务学习来集成人脸检测和特征点定位两个任务。
提出的CNN包括三个阶段:
(1)通过一个shallow CNN迅速产生candidate windows.
(2)通过一个稍复杂的CNN丢弃大部分没有人脸的windows.
(3)使用一个更强大的CNN精炼结果,同时显示面部特征点定位。设计lightweight CNN可以提高实时性能。
Approach
A. Overall Framework
整体流程如下图所示:对于给定的图片,首先resize到不同的尺寸建立一个image pyramid,作为接下来三层级联框架的输入。

Stage 1:采用全卷积神经网络,即Proposal Network(P-Net),去获得候选窗体和它们的边界盒回归向量(bounding box regression vectors)。然后,使用估算的边界盒回归向量来校准候选窗体。然后,利用NMS(non-maximum suppression)方法去除高度重叠的窗体。

Stage 2:所有候选窗体被送入另一个CNN: Refine Network(R-Net),更进一步地去除大量的错误候选窗体,再使用bounding box regression进行校准和NMS法。

stage 3:该阶段类似于第二阶段,但该阶段目的是描述脸部更多细节,显示五个脸部特征点位置。
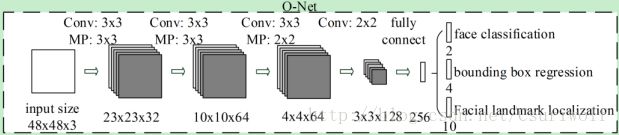
B.CNN Architecture(CNN结构图上面显示)
很多CNN被设计用于人脸检测,但其性能可能受到以下情况的限制:
(1)卷积层中的滤波器缺乏权重的多样性,限制他们的识别能力;
(2)对比其它多类目标检测和分类任务,人脸检测是一个有挑战性的二值分类任务,因此需要较少量但是更高识别力的滤波器。
为了达到这个目的,我们降低滤波器的数量,且将5×5的滤波改为3×3的滤波来减少计算,同时增加深度来提高性能。相比之前的结构有了更好的效果,缩短了训练时间。
C.Training
算法利用三个任务训练CNN检测器:face/non-face classification、bounding box regression、facial landmark localization。
(1)Face classification
two-class classification问题。对每个样本 使用cross-entropy loss(交叉熵损失函数):
Pi表示样本是人脸的概率,![]() 表示ground-truth label(样本是否为人脸的真实取值).
表示ground-truth label(样本是否为人脸的真实取值).
(2)Bounding box regression
对每个候选窗体,得到窗体和最近的ground truth之间的差距(CNN得出的候选窗口和真实窗口的差别)。回归问题,对每个样本 应用Euclidean loss(欧几里得损失函数):
其中, ![]() regression target来自网络,
regression target来自网络,![]() 是四维ground-truth 坐标,包括左上坐标、高和宽。
是四维ground-truth 坐标,包括左上坐标、高和宽。
(3)Facial landmark localization
类似于包围盒回归任务,脸部特征点检测也是回归问题,需最小化Euclidean loss:
其中, ![]() 是网络得到的面部特征点坐标,
是网络得到的面部特征点坐标, ![]() 是10维ground-truth 坐标,包括左眼、右眼、鼻子、左嘴角和右嘴角。
是10维ground-truth 坐标,包括左眼、右眼、鼻子、左嘴角和右嘴角。
(4)Multi-source training
对于级联架构的CNN,每一层有不同的任务,在学习过程中也有不同类型的训练图片,并不是所有的损失函数都同时使用,这可以通过a sample type indicator 实现。
整体学习目标如下:
针对多项任务的级联训练,不同的损失函数{det, box, landmark}的作用和权重各不相同。其中N是训练样本数量, αj 代表了任务的重要性。 βij 是sample type indicator。运用stochastic gradient descent(随机梯度下降)训练CNNs。
(5)Online Hard sample mining
传统hard sample mining是在分类器的训练完成后进行。本文将人脸分类(人脸/非人脸)任务中的online hard sample mining改为在训练过程中是自适应的。在每个mini-batch的训练过程中,把前向传播过程中处理的所有样本,按照loss值进行排序,用其中top 70% as hard samples。然后在反向传播阶段,只计算这些hard samples的梯度。这意味着在训练中忽略了对加强检测器基本没帮助的easy samples。
EXPERIMENTS
使用三个数据集进行训练对比结果:FDDB(Face Detection Set and Benchmark),WINDER FACE,AFLW(Annotated Facial Landmarks in the wild benchmark)。
A.Training Data
因为我们同时进行face detection and alignment,所以在训练过程中使用四种不同类型的数据标注:
(i) Negatives:和任何ground-truth faces 的IoU值小于0.3的regions。
(ii) Positives:和某ground-truth face的IoU值大于0.65。
(iii) Part faces:和某ground-truth face的IoU值在0.4~0.65间。
(iv) Landmark faces:标注了5个特定点位置的脸部。
face classification task:(i) (ii)
bounding box regression:(i) (iii)
facial landmark localization:(iv)
每个网络的训练数据:
(1) P-Net:随机选择WIDER FACE的部分来收集positives,negatives and part faces。从CelebA中选择faces作为landmark faces.
(2) R-Net:用框架的第一阶段从WIDER FACE中检测人脸收集positives,negatives and part faces,从CelebA中选择faces作为landmark faces.
(3) O-net:与R-net类似,但是使用的是框架的前两阶段检测人脸。
B.效果
本文的人脸检测(recall and precision)和人脸特征点定位(mean error)的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在GPU上可达到99fps。
CONCLUSION
本文提出一种基于multi-task cascaded CNNs的框架进行联合人脸检测和特征点检测。实验结果表明该方法在一些比赛测试集上性能一贯优于当前先进算法且速度快,保持实时性能。未来可以研究人脸检测和其他人脸分析任务内在的联系,提升性能。
相关工作
1、Viola和Jones[Robust real-time face detection. International
journal of computer vision-2004]:提出cascade face detector利用 Haar-Like 特征和AdaBoost训练级联分类器,达到很好的性能和实时性。缺点在于针对较为复杂情况下的人脸识别,精确率不够。
2、DPM(Deformable Part Models)方法:缺点在于计算量大,训练样本需要大量的标注。
3、Yang(From facial parts responses to face detection: A deep learning approach-2015)等人训练深度卷积神经网络用于面部属性识别以获得人脸区域更高的响应。由于复杂的CNN结构,时间代价很高。
4、Li(A convolutional neural network cascade for face detection-2015)等人使用级联的CNNs来检测人脸,但是需要bounding box校准,且忽略了人脸的特征定位与bounding box regression内在的联系。
Face alignment也有很多研究:Regression-based methods and template fitting approaches。
Zhang(Facial landmark detection by deep multi-task learning-2014)等提出使用facial attributed recognition作为附加的任务和深度卷积神经网络来增强face alignment性能。
但是大部分可用的人脸检测和人脸校准方法忽略了两个任务之间内在的联系,尽管已经有一些人试图关联解决,但是仍然存在一些限制:
1、Chen(Joint cascade face detection and alignment-2014)等使用pixel value difference用随机森林法联合进行校准和检测。但是人工特征限制了性能。
2、Zhang(Improving multiview face detection with multi-task deep convolutional neural networks-2014)使用multi-task CNN 改善multi-view人脸检测,但是检测准确度被若人脸检测器产生的初始检测窗口限制。
另外,训练过程中mining hard samples对检测器的性能很重要。传统方法采用离线方式,增加了手工操作。本文中使用了online hard sample mining method,自适应的对当前训练过程。