python机器学习之SMO算法
SVM算法计算到后面是一个带约束条件的优化问题
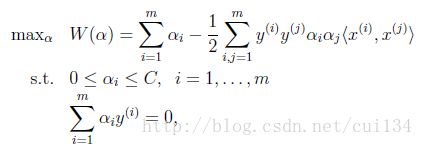
这里的SMO(Sequential Minimal Optimization)序列最小化算法就是一个二次规划优化算法,可以用来解决上面的问题。SMO算法是由John C.Platt在1998年提出的。SMO算法的目标就是求出一些列的alpha和b,一旦求出这些alpha,就可以计算出权重向量,并求出分割超平面。SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到一对合适的alpha,那么就增大其中一个,同时减少另一个。那么为什么每次都要选择两个alpha进行优化呢,我们可以看到以上公式中有一个约束条件:
因此,如果只改变其中一个alpha,那么这个约束条件就无法满足,因此需要选择2个alpha同时进行优化,并且增大其中一个,另一个也要减小相同的大小。这里选择alpha的方式采用启发方式,具体步骤:先通过外循环来选择第一个alpha,选择过程会在两种方式下交替:一种方式是在所有数据集上进行单遍扫描,另一种是在非边界alpha中实现单遍扫描,这里的非边界alpha是指大于0小于C的alpha的值,这里的C是自己设定的,之后,在选择完第一个alpha后,算法会通过一个内循环来选择第二个alpha,通过最大步长的方式来选择第二个alpha,假设Ej是Xj的估计值与实际值的误差,j是第二个alpha的编号,i是第一个alpha的编号,那么则选取Ei-Ej最大的那个alpha来作为第二个优化的值。
代码如下:
首先,定义一个类:
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler): # 构造函数
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #用于存储误差E
self.K = mat(zeros((self.m,self.m)))#计算向量经过核函数的值
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k):#返回计算的误差
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei):#启发方式选择第二个alpha
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #选择Ei-Ej最大的alpha
if k == i: continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #第一次计算的时候,eCache为0
j = selectJrand(i, oS.m)#随机选择
Ej = calcEk(oS, j)
return j, Ejdef updateEk(oS, k):#更新Ek
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):#内循环
Ei = calcEk(oS, i)
#满足该条件,进行优化
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #选择j
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #用于后续更新alpha
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #更新j的误差
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
updateEk(oS, i) #更新i的误差
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #外循环
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0#非0表示alpha经过优化
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #遍历所有值
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#遍历非边界值
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #遍历完所有值
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas训练结果如下:
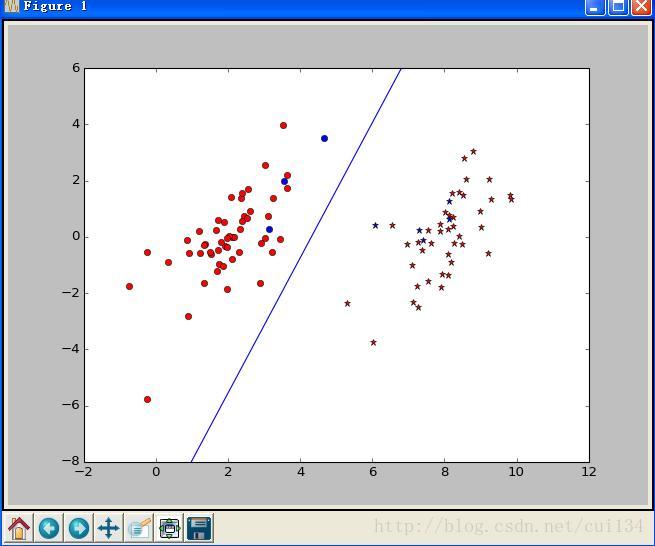
蓝色点代表支持向量,w矩阵就是由这些支持向量计算来的,因此,在训练完成后,可以通过支持向量来对未知向量进行分类。
对于复杂的数据而言,有些数据是不能够像上图一样能够线性可分的。
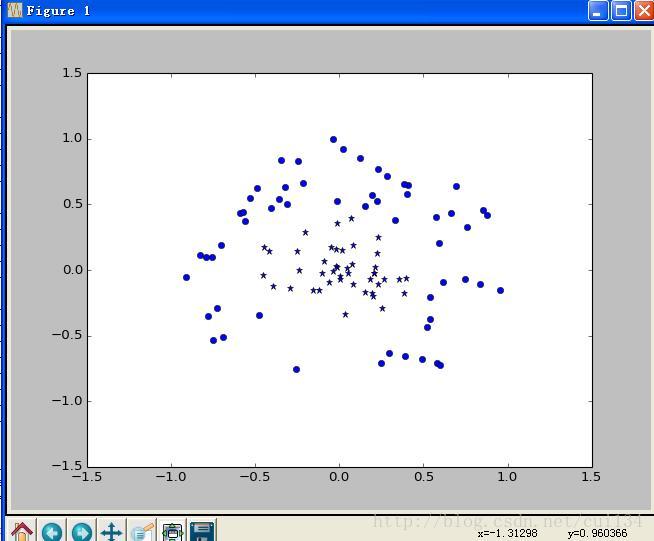
因此,我们可以把训练数据映射到一个高维的空间去,也许在这个高维空间,可以线性可分。这里实际上就是对向量进行一个变换。但是我们不需要把向量变换到高维之后在进行内积,因为根据泛函的有关理论,只要一种核函数K(xi,yi)满足Mercer条件,它就对应某一变换空间中的内积。
这里介绍一个常用的核函数,径向基核函数:
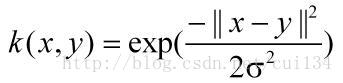
代码如下:
def kernelTrans(X, A, kTup): #核函数计算
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #线性核函数
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #计算经过核函数计算后的值
else: raise NameError('Houston We Have a Problem -- \
That Kernel is not recognized')
return K下面利用径向基核函数对上图进行分类
def testRbf(k1=1.3):
dataArr,labelArr = loadDataSet('testSetRBF.txt')
for i in range(100):
if labelArr[i]==1:
pl.plot(dataArr[i][0],dataArr[i][1],'b*')
else:
pl.plot(dataArr[i][0],dataArr[i][1],'bo')
pl.xlim([-1.5,1.5])
pl.ylim([-1.5,1.5])
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #得到支持向量的点
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)==1:
pl.plot(dataArr[i][0],dataArr[i][1],'r*')
else:
pl.plot(dataArr[i][0],dataArr[i][1],'ro')
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m)
pl.show()结果
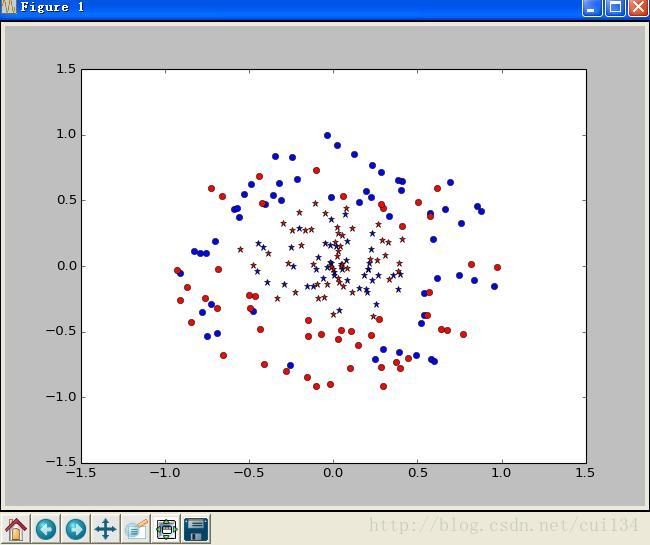
如图,蓝色是训练数据,红色是测试数据,可以看出,经过蓝色数据的训练之后,尽管测试数据不是线性可分,SVM仍可以对测试数据很好的分类。