MongoDB 学习笔记:Sharded Cluster
本文目录
1 整体架构
2 Shard Key
3 Chunk
1 整体架构
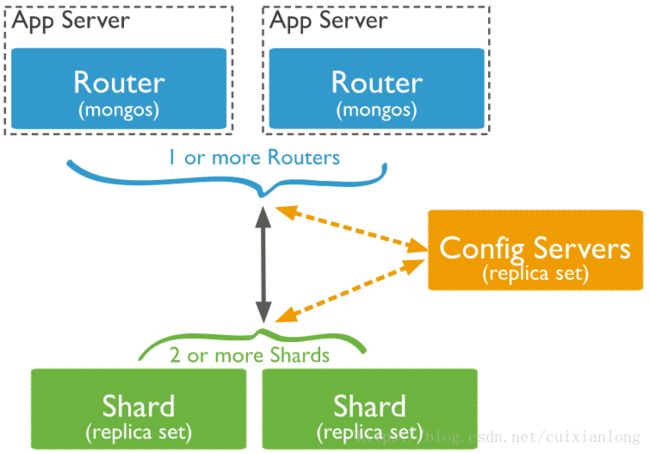
1.1 Shard
Shard用于存储用户数据,每个Shard存储用户数据中的一部分。
当数据量超过Shard整体容量时,可以动态增加Shard节点,从而动态扩展数据容量。
每个Shard节点部署在一台服务器上,每台服务器上可能部署了多个Shard节点。
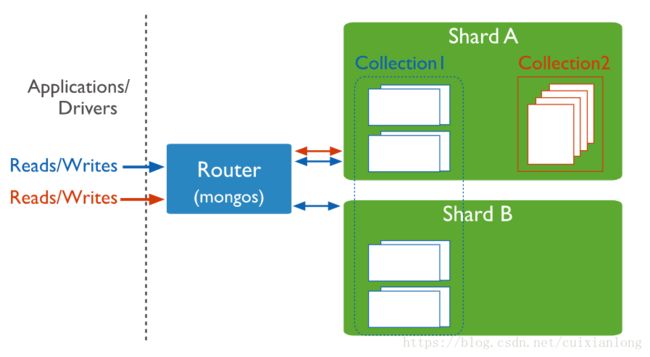
1.2 Router(Mongos)
Router(Mongos)是Sharded Cluster的访问入口,使得集群内部对外透明。
Router本身不存储数据,而是用于请求的路由,将请求分发至相应的Shard节点。
元数据将存储到Config Server,而用户数据将存储到各Shard中。
1.3 Config Server
Config Server用于存储原数据和集群配置。
2 Shard Key
Shard Key(片键)由文档中的一个或多个字段组成,Shard Key 中的字段必须是某个索引的前缀,即至少需要创建一个索引,且该索引以 Shard Key 作为前缀字段,或该索引仅包含Shard Key字段。
MongoDB会根据数据的Shard Key对数据进行一个范围划分,每一个范围内的数据对应一个Chunk。
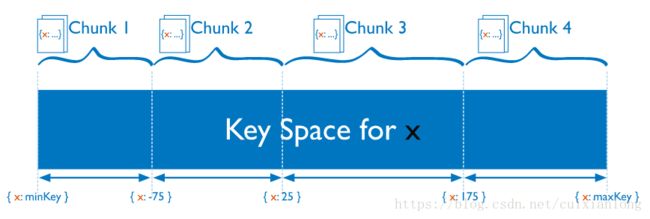
从而决定该文档应该存储在哪一个Shard上,最终决定该文档应该存储在哪一个机器上。
2.1 Sharding Strategy(分片策略)
MongoDB 支持两种分片策略:Ranged Sharding(范围分片) 和 Hashed Sharding(哈希分片)
Ranged Sharding 就是基于 Shard Key 值进行范围划分;
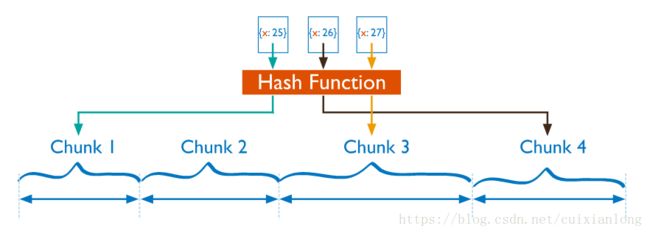
Hashed Sharding 则是将 Shard Key 先进行一次 Hash 操作,得到一个 Hash 值,然后基于该 Hash 值进行范围划分。
2.2 Shard Key 的设计
原则:
(1)尽量让数据均匀分布在各Chunk中,从而均匀分布在各Shard中,减少Chunk拆分和迁移的可能性。
(2)尽量保证范围查询可以落在较少的Shard中,以避免Scatter/Gather操作,提升性能。
例如:当希望以用户ID(一组递增数字)作为Shard Key。
但由于用户ID是递增数字,导致新用户的数据总是落在最后一个Chunk中,进而可能导致不断拆分和迁移后面的Chunk数据。
因此,在设计Shard Key的时候,可以创建一个单独的字段SK,该字段内容如下(+号标识连接):
SK = 1 + 用户ID最后一位 + 用户ID
即,当用户ID为10055123时,SK值为1310055123。
这时,新增用户的SK值前两位将从10-19依次变化,相当于将用户ID分成了10个大组,分别对应不同的Chunk,起到了分散数据的作用。即满足(1)的要求。
当经常通过用户ID查询某用户的数据。上述设计也可以保证相同用户的数据会保存在同一个Chunk中,即保证了相同的用户数据会保存在同一个Shard中。当请求某个用户的数据时,查询会被路由至相应的Shard执行,而不会让所有Shard都查询是否有该用户数据,然后再汇集返回给调用者。即满足(2)的要求。
3 Chunk
MongoDB会根据Shard Key将数据对应保存在不同Chunk上,每个Chunk保存一部分数据。
每个Chunk有一定容量上限,当Chunk内数据超过该上限,该Chunk将会被拆分成两个Chunk,拆分后的Chunk将对应更小范围的Shard Key值。
当某个Chunk仅对应一个Shard Key时,将无法被拆分,即每个Chunk以Shard Key作为最小单位,进行数据的保存。
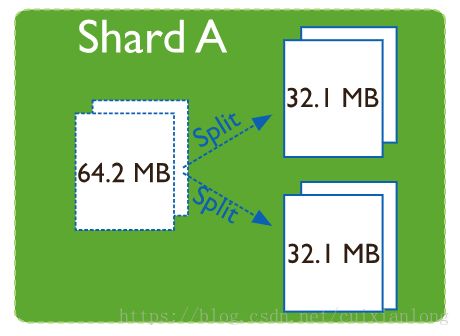
每个Chunk属于一个Shard,每个Shard包含一个或多个Chunk。
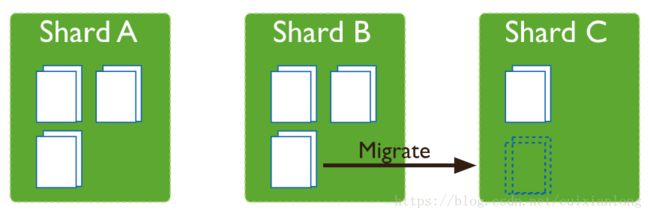
当各Shard上的数据量不均衡时,超过某个阈值,将会引发Chunk的迁移操作,数据量过多的Shard中的部分数据,将会以Chunk为单位,迁移至其它Shard中,以达到各Shard相对均衡的状态。
当Shard Key设计完成后,有时,需要根据Shard Key对Chunk进行预设。
从而,在初始阶段,就将Chunk进行了初始拆分,且确定了每个Chunk的边界,以减少前期频繁的Chunk拆分及迁移。