AutoEncoder自动编码器
###AutoEncoder
AutoEncoder解决的是特征提取问题,在研究中发现,如果在原有的特征中加入自动学习得到的特征可以大大提高分类精确度。
1 . 给定无标签数据,用非监督学习学习特征:

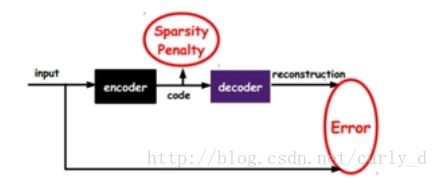
如图,我们将input输入一个encoder编码器,就会得到一个code,再经过decoder,decoder就会输出一个信息,那么如果输出的信息和一开始输入的input很像,那我们可以认为这个code的靠谱的,所以通过调整coder和decoder的参数,使得重构误差最小,这时候我们就得到了input信号的一个表示,也就是code,因为无标数据,所以误差来源就是我们直接重构后与原输入对比得到。
2 . 通过编码器特征,然后训练下一层,这样逐层训练:
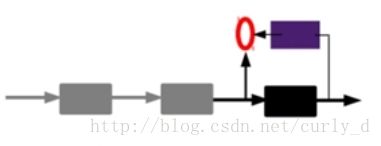
第一层的code会作为第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达。
3 . 有监督微调:
经过上面的方法,我们就可以构建多层模型,模型越抽象越好,就像人的视觉系统一样。
4 . 当然AutoEncoder还不能用来分类数据,因为它只是用来重构和复现原始输入,为了实现分类,还需要在AutoEncoder的最顶层添加一个分类器(SVM, logistic regression等),然后通过标准多层神经网络进行监督训练。
###Sparse AutoEncoder
我们可以继续加上一些约束条件到新的deep learning方法,如在AutoEncoder的基础上加上L1的Regularity限制(L1主要约束每一层中的节点大部分为0,这就是sparse AutoEncoder.
input: X c o d e : h = W T X X code: h = W^TX Xcode:h=WTX
loss: L ( X : W ) = ∣ ∣ W h − X ∣ ∣ 2 + λ ∑ j ∣ h j ∣ L(X:W) ={||Wh -X||}^2 +\lambda \sum_j|h_j| L(X:W)=∣∣Wh−X∣∣2+λ∑j∣hj∣
###Denoising AutoEncoder
降噪自动编码器DA是在自动编码器的基础上,将训练数据中加入噪声,所以自动编码器必须学习去除噪声获取原数据的能力。因此,就这就迫使编码器学习输入信号的更加鲁棒的表达,这也是它泛化能力好于其它编码器的原因。DA可以通过梯度下降法去训练。

自编码器中会用到一种参数初始化方法: Xavier Initialization。该初始化方法会根据某一层网络的输入输出节点数量自动调整最适合的随机分布。让初始化权重不大或不小,正好合适。从数学的角度讲,就是
让权重满足0均值,方差为 2 n i n + n o u t \frac{2}{n_{in}+n_{out}} nin+nout2。随机分布可以是均匀分布或高斯分布。
def xavier_init(fan_in, fan_out, constant = 1):
low = -constant * np.sqrt(6.0/(fan_in + fan_out))
high = constant * np.sqrt(6.0/(fan_in + fan_out))
return tf.random_uniform((fan_in,fan_out),minval=low, maxval=high,dtype=tf.float32)
上面代码,通过tf.random_uniform 创建了一个均匀分布,区间为: ( − 6 n i n + n o u t , 6 n i n + n o u t ) (-\sqrt{\frac{6}{n_{in}+n_{out}}},\sqrt{\frac{6}{n_{in}+n_{out}}}) (−nin+nout6,nin+nout6)
上述均匀分布方差可以根据公式计算: D ( x ) = ( m a x − m i n ) 2 12 = 2 n i n + n o u t D(x) = \frac{(max - min)^2}{12} = \frac{2}{n_{in}+n_{out}} D(x)=12(max−min)2=nin+nout2
###代码
import numpy as np
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plot
import sklearn.preprocessing as prep
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
import os
#Xavier均匀初始化
def xavier_init(fan_in, fan_out, constant = 1):
low = -constant * np.sqrt(6.0/(fan_in + fan_out))
high = constant * np.sqrt(6.0/(fan_in + fan_out))
return tf.random_uniform((fan_in,fan_out),minval=low, maxval=high,dtype=tf.float32)
#降噪自编码器
#n_input 输入变量数 n_hidden 隐藏层层数 transfer_function 隐藏层激活函数 optimizer 优化器 scale 高斯噪声系数
class AdditiveGaussianNoiseAutoDecoder(object):
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,optimizer
=tf.train.AdamOptimizer(learning_rate=0.001),scale=1):
with tf.Graph().as_default():
self.n_input = n_input;
self.n_hidden = n_hidden;
self.transfer = transfer_function;
self.scale = tf.placeholder(tf.float32)
self.training_scale = scale
network_weights = self.initialize_weights()
self.weights =network_weights
with tf.name_scope("raw_input"):
self.x = tf.placeholder(tf.float32,[None,self.n_input])
img_x = tf.reshape(self.x, [-1, 28, 28, 1])
#tf.summary.histogram('raw_input', self.x)
tf.summary.image('input', img_x, 10)
#对输入x添加高斯噪声,即self.x + scale*tf.random_normal((n_input,))然和权重相乘加上偏置,再用激活函数处理
with tf.name_scope("noise_adder"):
self.scale = tf.placeholder(tf.float32)
self.noise_x = self.x + self.scale*tf.random_normal((n_input,))
with tf.name_scope("Encoder"):
self.hidden = self.transfer(tf.add(tf.matmul(self.noise_x,self.weights['w1']),self.weights['b1']))
with tf.name_scope("reconstruction"):
#重构层是线性的
self.reconstruction = tf.add(tf.matmul(self.hidden,self.weights['w2']),self.weights['b2'])
img_reconstruction = tf.reshape(self.reconstruction, [-1, 28, 28, 1])
#tf.summary.histogram('reconstruction', self.reconstruction)
tf.summary.image('reconstruction', img_reconstruction, 10)
with tf.name_scope("loss"):
self.cost = 0.5*tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction,self.x),2))
with tf.name_scope("train"):
self.optimizer = optimizer.minimize(self.cost)
init = tf.global_variables_initializer()
self.sess = tf.Session()
self.writer = tf.summary.FileWriter(logdir='logs_3',graph=tf.get_default_graph())
self.merged = tf.summary.merge_all()
self.sess.run(init)
print("begin to run session....")
def partial_fit(self,X):
cost,opt,summary = self.sess.run((self.cost,self.optimizer,self.merged),feed_dict={self.x:X,self.scale:self.training_scale})
return cost,summary
def calc_total_cost(self,X):
return self.sess.run(self.cost,feed_dict={self.x:X,self.scale:self.training_scale})
#将隐藏层的输出结果,获得抽象后的高阶特征表示
def transform(self,X):
return self.sess.run(self.hidden,feed_dict={self.x:X,self.scale:self.training_scale})
#返回自编码器高阶特征输入,将其作为重建原始数据
def generate(self,hidden=None):
if hidden == None:
hidden = np.random.normal(size=self.weights['b1'])
return self.sess.run(self.reconstruction,feed_dict={self.hidden:hidden})
def Reconstruction(self,X):
#tf.summary.image('input', X, 100)
recons = self.sess.run([self.reconstruction],feed_dict={self.x :X ,self.scale:self.training_scale})
#recons = self.sess.run([self.reconstruction],feed_dict={self.x :X ,self.scale:self.training_scale})
return recons
def initialize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(xavier_init(self.n_input,self.n_hidden),name='weight1')
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden],dtype=tf.float32),name='bais1')
all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden,self.n_input],dtype=tf.float32),'weight2')
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input],dtype=tf.float32),'bais2')
return all_weights
AGN_AC = AdditiveGaussianNoiseAutoDecoder(n_input=784,n_hidden=400)
#使用sklearn preprocess的数据标注化操作(0均值,标准差为1)预处理数据首先在训练集上
# 估计均值和方差,然后作用到训练集和测试集 (X-mean)/std
def standard_scale(X_train,X_test):
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train,X_test
def get_random_block_from_data(data , batch_size):
start_index = np.random.randint(0,len(data) - batch_size)
return data[start_index:(start_index+batch_size)]
mnist = input_data.read_data_sets('D:/tensorflow/pys/test1/tmp/tensorflow/mnist/input_data',one_hot=True)
X_train, X_test = standard_scale(mnist.train.images,mnist.test.images)
n_samples = int(mnist.train.num_examples)
train_epochs = 10
batch_size = 128
display_step = 1
for epoch in range(train_epochs):
avg_cost = 0
total_batch = int(n_samples/batch_size)
for i in range(total_batch):
batch_xs = get_random_block_from_data(X_train,batch_size)
cost,summary = AGN_AC.partial_fit(batch_xs)
AGN_AC.writer.add_summary(summary, i)
avg_cost += cost/batch_size
#avg_cost /= total_batch
avg_cost /= total_batch
if epoch%display_step == 0:
print("epoch:%.04d, avg_cost=%.9f" %(epoch+1,avg_cost))
print("total cost:",str(AGN_AC.calc_total_cost(X_test)))
n = 10 # how many digits we will display
plt.figure(figsize=(30, 4))
for i in range(n):
ax = plt.subplot(3, n, i + 1)
plt.imshow(X_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
noise_x = AGN_AC.sess.run(AGN_AC.noise_x,feed_dict={AGN_AC.x :X_test[i].reshape(1, 784) ,AGN_AC.scale:AGN_AC.training_scale})
#rec = AGN_AC.Reconstruction(X_test[i].reshape(1, 784))
plt.imshow(np.array(noise_x).reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + 2*n)
rec = AGN_AC.Reconstruction(X_test[i].reshape(1, 784))
plt.imshow(np.array(rec).reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
AGN_AC.writer.close()