学渣讲消息队列之RabbitMQ从敲门到入门(第一讲)
学渣讲消息队列之RabbitMQ从敲门到入门(第一讲)
- 学渣讲消息队列之RabbitMQ从敲门到入门第一讲
-
- 消息队列简介
- 消息队列的应用场景
- 1异步处理
- 2应用解耦
- 3流量削锋
- 4日志处理
- 常见消息队列的比较
- 1从社区活跃度
- 2持久化消息比较
- 3综合技术实现
- 4高并发
- 5比较关注的比较 RabbitMQ 和 Kafka
- RabbitMQ Server的安装
- RabbitMQ Server的启动与停止
- 启用RabbitMQ Server的Web管理界面
- 关于作者
-
消息队列简介
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。其中较为成熟的MQ产品有IBM WEBSPHERE MQ等等。(解释源自:百度百科 - “rabbitmq”,若链接失效,请访问https://baike.baidu.com/item/rabbitmq/9372144?fr=aladdin)
消息队列的应用场景
(此部分转自CSDN博客 - ThisSeven - “消息队列使用的四种场景介绍”,若链接失效请访问http://blog.csdn.net/seven__________7/article/details/70225830,如若侵权请告知,我将立即删除)
以下介绍消息队列在实际应用中常用的使用场景。异步处理,应用解耦,流量削锋和消息通讯四个场景。
1、异步处理
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端

(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
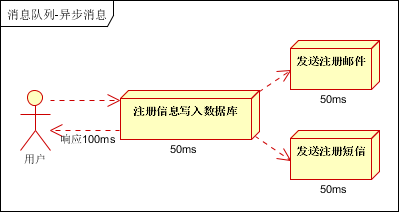
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100)
小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:

按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍
2、应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图

传统模式的缺点:
- 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败
- 订单系统与库存系统耦合
如何解决以上问题呢?引入应用消息队列后的方案,如下图:

- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦
3、流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
- 可以控制活动的人数
可以缓解短时间内高流量压垮应用
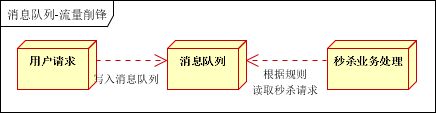
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面
- 秒杀业务根据消息队列中的请求信息,再做后续处理
4、日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下
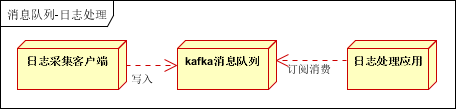
- 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列
- Kafka消息队列,负责日志数据的接收,存储和转发
- 日志处理应用:订阅并消费kafka队列中的日志数据
常见消息队列的比较
(此部分转自SOJSON在线技术博客 - “我为什么要选择RabbitMQ ,RabbitMQ简介,各种MQ选型对比”,若链接失效请访问http://www.sojson.com/blog/48.html,如若侵权请告知,我将立即删除)
1、从社区活跃度
按照目前网络上的资料,RabbitMQ 、ActiveMQ 、ZeroMQ 三者中,综合来看,RabbitMQ 是首选。
2、持久化消息比较
ZeroMQ 不支持,ActiveMQ 和RabbitMQ 都支持。持久化消息主要是指我们机器在不可抗力因素等情况下挂掉了,消息不会丢失的机制。
3、综合技术实现
可靠性、灵活的路由、集群、事务、高可用的队列、消息排序、问题追踪、可视化管理工具、插件系统等等。
RabbitMQ / Kafka 最好,ActiveMQ 次之,ZeroMQ 最差。当然ZeroMQ 也可以做到,不过自己必须手动写代码实现,代码量不小。尤其是可靠性中的:持久性、投递确认、发布者证实和高可用性。
4、高并发
毋庸置疑,RabbitMQ 最高,原因是它的实现语言是天生具备高并发高可用的erlang 语言。
5、比较关注的比较, RabbitMQ 和 Kafka
RabbitMQ 比Kafka 成熟,在可用性上,稳定性上,可靠性上, RabbitMQ 胜于 Kafka (理论上)。
另外,Kafka 的定位主要在日志等方面, 因为Kafka 设计的初衷就是处理日志的,可以看做是一个日志(消息)系统一个重要组件,针对性很强,所以 如果业务方面还是建议选择 RabbitMQ 。
还有就是,Kafka 的性能(吞吐量、TPS )比RabbitMQ 要高出来很多。
RabbitMQ Server的安装
本系列文章主要以RabbitMQ为例,因此这里只介绍RabbitMQ的在Windows下的安装过程。
因为RabbitMQ是由ERLANG语言实现,因此需要先行安装ERLANG。
- 1、访问ERLANG官方下载页面(若链接失效请访问:http://www.erlang.org/downloads),下载OTP 20.2程序。(截至本文发布,最新版为20.2)
32位安装包地址:http://erlang.org/download/otp_win32_20.2.exe
64位安装包地址:http://erlang.org/download/otp_win64_20.2.exe
下载完成后一路”下一步”就可以了。如果不是采用这种方法安装,请自行配置环境变量,新增条目”ERLANG_HOME”,值为”D:\erl9.2”(这里以ERLANG的安装目录为”D:\erl9.2”为例)。
- 2、访问RabbitMQ Server官方下载页面(若链接失效请访问:http://www.rabbitmq.com/download.html),下载RabbitMQ Server程序。(截至本文发布,最新版为3.7.3)
这里推荐采用安装包的方法安装:
from Bintray:https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.7.3/rabbitmq-server-3.7.3.exe
from Github:https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.3/rabbitmq-server-3.7.3.exe
还是一路”下一步”就可以了。
也可以采用压缩包的安装方法:
from Bintray:https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.7.3/rabbitmq-server-windows-3.7.3.zip
from Github:https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.7.3/rabbitmq-server-windows-3.7.3.zip
采用这种方法安装,请下载压缩包后解压。
安装完成后,可以在环境变量”Path”里新增”D:\RabbitMQ Server\rabbitmq_server-3.7.3\sbin”这个值,便于后面操作。
RabbitMQ Server的启动与停止
启动:用管理员身份运行”cmd“,输入
rabbitmq-service start,如果出现如下图所示:

表示RabbitMQ Server启动成功。停止:用管理员身份运行”cmd“,输入
rabbitmq-service stop,如果出现如下图所示:

表示RabbitMQ Server已成功停止运行。
启用RabbitMQ Server的Web管理界面
用管理员身份运行”cmd“,输入rabbitmq-plugins enable rabbitmq_management,如果出现如下图所示:

表示RabbitMQ Server已成功启用Web管理程序。(处于安全原因已将部分信息打码)
在安装完plugins后需要重新启动RabbitMQ Server,之后打开浏览器,访问地址:http://localhost:15672,会看到如下的登陆界面:
用户名和密码都输入guest,点击Login即可登陆,通过Web端查看和控制RabbitMQ。
关于作者
作者是一名即将毕业的大四学生,自学爬虫并作为数个爬虫项目的主要开发者,对各种爬虫有一定的了解和项目经验,目前正在自学分布式爬虫的内容,也将在后面陆续为大家更新。同时作者也是一个狂热的信息安全爱好者,如果有想要和作者交流经验或者想要提出意见的朋友,欢迎在下方留言,我会及时回复大家的。感谢大家的支持。