车型识别“A Large-Scale Car Dataset for Fine-Grained Categorization and Verification”
论文的目标如题,对车型进行精细分类,作者构建了一个比较大型的车辆数据库CompCars,涵盖不同视角,包含车辆内部及外部特征,由监控视频获得的数据和从网络上下载的数据组成。文章做了车辆型号识别,认证和属性预测三部分,训练好的模型GoogLeNet_cars在Caffe Model Zoo中。
CompCars数据库
网络数据库包含163个品牌1716个车型,共136,727张整车图片,27,618张车辆局部图片,监控图像数据库包含50,000张正面车辆图片,与之前数据库相比,CompCars包含车辆分层,车辆属性,不同视角和车辆局部图片。
数据库中车辆数据结构,属性,视角及车辆局部图片分布介绍如下。
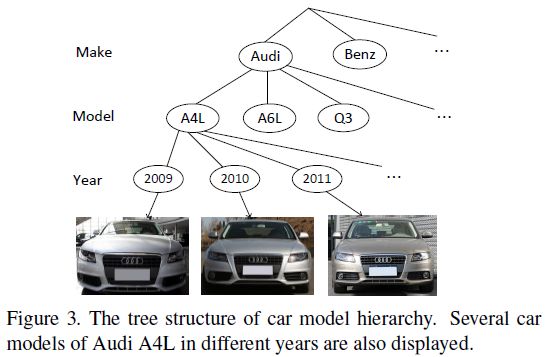
数据结构:车辆数据结构为树形结构,包括三层,即车辆品牌,模型和出厂时间,不同年份生产的车辆只有细微差别,树形结构如下图所示:
车辆属性:每个型号的车辆使用五个属性标记,即最大速度,排量,车门数目,座位数目以及车型。定义了十二个车型,包括MPV, SUV, hatchback, sedan, minibus, fastback, estate, pickup, sports,crossover, convertible, and hardtop convertible,如下图所示。
属性又分为内部属性和外部属性两类,外部属性包括车门数目,座位数目以及车型。
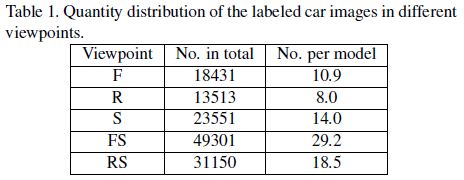
视角:包含5个视角,即front (F), rear (R), side (S), front-side(FS), and rear-side (RS).不同视角图片的数量如下表所示:
车辆局部:收集了每个型号车辆的8个局部图片,包括4个外部局部图片(i.e. headlight, taillight, fog light, and air intake)和4个内部局部图片(i.e. console, steering wheel, dashboard, and gear lever),车辆局部图片示例如下所示:

实验
设计了三个应用实验,即精细车辆分类,属性预测和车辆认证。作者从CompCars选择了78,126张图片,并将数据库分成了三部分,PartI包含431个车型共30,955张整车图像及20,349张车辆局部图像。PartII包含111个车型共4,454张图像。PartIII包含1,145个车型共22,236张图像。车辆分类使用PartI,属性预测使用PartI训练,PartII测试,车辆认证使用PartIII。
训练使用Overfeat模型,ImageNet预训练,使用车辆图像微调。
1.车辆精细分类,将车辆分为431类,每个型号不同年份归为一类,分别使用整车图像和车辆局部图像实验。
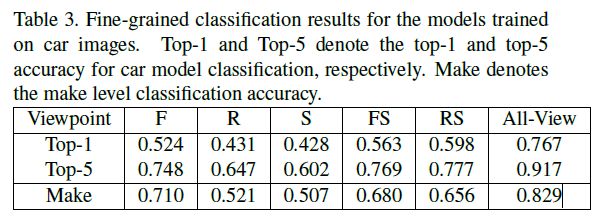
对于整车分类,使用了五个视角的图片进行实验,FS和RS获得的效果比较好,使用所有视角微调的结果最好,不同视角微调结果比较如下表所示。
下图显示了在全连接层触发高响应的节点。

模型的扩展性能较好,在网络图像上训练的模型用于监控图像获取的数据获得较好的识别结果。
对于车辆局部图像,分别使用8个部位的车辆图像对CNN进行训练,实验结果显示“尾灯”的效果最好,使用投票方法对8个部位的识别效果进行综合评判,也得到了比较好的结果,如下表。

2.车辆属性预测
对最大速度,排量,车门数目,座位数目以及车型进行预测,其中最大速度,排量是连续值,下图显示了几张图片的预测结果。
3.车辆认证
使用实验1中的分类模型提取特征,之后在PartII数据集上使用Joint Bayesian训练认证模型。最后使用PartIII进行测试。将测试数据分为易,中,难三部分,每部分包含2000对图像,其中1000对正样本,1000对负样本。
Joint Bayesian在人脸认证上首先应用,将特征x公式化为两个高斯变量之和,即
x=μ+ε
等式右边前者是身份信息,右边是类内方差。给定类内类间方差估计,Joint Bayesian估计两物体的联合概率,即 P(x1,x2|HI) , P(x1,x2|HE) ,两个概率的方差服从高斯,即,
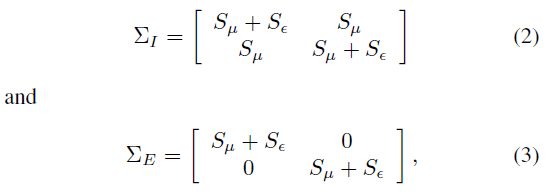
测试时,估计似然比,

第二个方法是CNN+SVM,SVM使用图像对的特征作为输入,是一个二值分类器。1表示匹配图像对,0表示未匹配。100,000图像对训练。
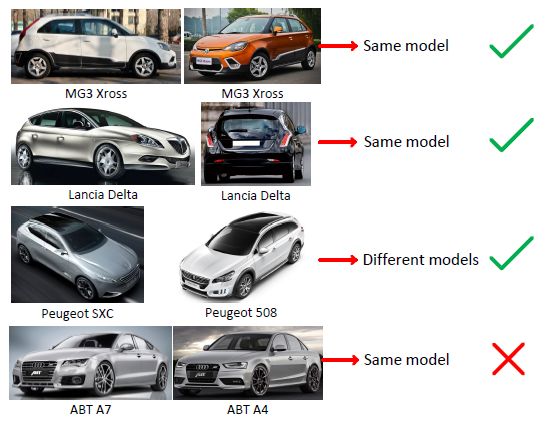
下图显示了使用CNN+Joint Bayesian认证的结果
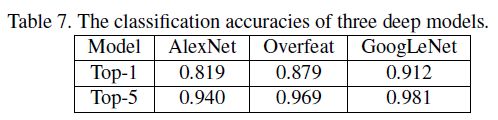
4.与AlexNet,GoogleNet车型识别结果对比如下表所示