汇编学习笔记:函数调用过程中的堆栈分析
原创作品:陈晓爽(cxsmarkchan)
转载请注明出处
《Linux操作系统分析》MOOC课程 学习笔记
本文通过汇编一段含有简单函数调用的C程序,说明在函数调用过程中堆栈的变化。
1 C程序及其汇编代码
1.1 C程序源码
本文使用的C程序源码如下:
//main.c
int g(int x){
return x + 5;
}
int f(int x){
return g(x);
}
int main(void){
return f(9) + 3;
}这个程序仅含有main函数和两个函数调用,不含输入输出。不难看出程序的运行过程为:
- main函数调用f函数,传入参数9;
- f函数调用g函数,传入参数9;
- g函数返回9+5,即14;
- f函数返回14;
- main函数返回14+3,即17.
1.2 汇编代码
在linux(本文平台为实验楼Linux内核分析)下执行如下编译指令:
gcc -S -o main.s main.c -m32该指令可将main.c编译为汇编代码(而非二进制执行文件),输出到main.s。参数“-m32”表示采用32位的方式编译。
用vim打开main.s文件,可以看到如下图的汇编代码:

在main.s中,有大量的以“.”开头的行,这些行只是用于链接的说明性代码,在实际的程序中并不会出现。为便于分析,可以将这些内容删去,得到纯粹的汇编代码,如下:
g:
02 pushl %ebp
03 movl %esp, %ebp
04 movl 8(%ebp), %eax
05 addl $5, %eax
06 popl %ebp
07 ret
f:
09 pushl %ebp
10 movl %esp, %ebp
11 subl $4, %esp
12 movl 8(%ebp), %eax
13 movl %eax, (%esp)
14 call g
15 leave
16 ret
main:
18 pushl %ebp
19 movl %esp, %ebp
20 subl $4, %esp
21 movl $9, (%esp)
22 call f
23 addl $3, %eax
24 leave
25 ret汇编代码中的pushl/popl/movl/subl/addl操作,末尾的字母“l”代表32位操作。
可以看出,汇编代码一共分为3部分,即3个函数。在main函数中调用了call f指令,在f函数中调用了call g指令,和C程序的逻辑是一致的。但是,不同于C程序的简洁明了,汇编代码在调用call指令之前,还有一系列的赋值(movl)、压栈(pushl)、弹栈(popl)等操作,且其处理对象均为ebp、esp等寄存器。这些操作的含义是本文的重点。
2 函数调用过程中的堆栈分析
2.1 相关的寄存器
本文涉及的寄存器变量如下:
| 寄存器变量 | 含义 |
|---|---|
| eax | 返回值寄存器,用于存储函数返回值 |
| eip | 当前指令地址寄存器,其值为内存中的指令地址,只能通过jmp, call, ret等修改,不可直接修改 |
| ebp | 堆栈底端地址寄存器,其值对应内存中的堆栈底端 |
| esp | 堆栈顶端地址寄存器,其值对应内存中的堆栈顶端,ebp-esp之间即堆栈内容 |
2.2 push和pop指令
故名思议,push和pop操作对应堆栈的压栈和弹栈操作。在push和pop操作时,ebp即堆栈底端的位置不变,而esp即堆栈顶端的位置会改变,操作均在esp处进行。值得注意的是,注意到堆栈在内存中是降序排列,即ebp的值大于esp的值。每进行一次压栈操作,esp均会减小4;每进行一次弹栈操作,esp均会增加4。
因此,pushl %A等价于:
subl $4, %esp ;堆栈顶端指针向下移动4字节(即32位)
movl %A, (%esp) ;将寄存器A的内容存到寄存器esp对应的内存地址类似地,popl %A等价于:
movl (%esp), %A ;将堆栈顶端对应的内存中的内容幅值给A
addl $4, %esp ;堆栈顶端上移4字节2.3 函数调用:call指令和ret指令
2.3.1 call和ret对应的堆栈操作
call f 等价于如下汇编代码:
pushl %eip ;将当前的程序位置压栈
movl f, %eip ;将f函数的入口位置赋给eip,则下一条指令执行f的入口指令。ret 等价于如下汇编代码:
popl %eip 由此可见,函数调用的时候,首先是在堆栈中存入当前的程序位置,再跳转到被调用的函数入口。在返回时,从堆栈中弹出当前的程序位置即可。
在call语句调用结束后,访问eax寄存器,即可得到函数返回值。
值得注意的是,eip指令是不允许直接被调用的,因此上述等价程序并不能直接写在汇编代码中,只能通过call和ret来间接执行。
2.3.2 参数的传入
很容易发现这样的问题:在调用函数f(9)时,调用call即意味着跳转,那么9作为函数参数,应该如何传递给被调用的函数?
答案是:参数的传入也通过堆栈来进行。
在汇编代码中,注意call f指令之前有如下语句:
subl $4, %esp
movl $9, (%esp)这两条语句实际上等价于pushl $9,因此,在调用call语句之前,9这个参数就已经被压入堆栈中。进入函数f时,堆栈顶端为前一个eip,堆栈第2项即为参数9。因此,只需访问4(%esp)即可获取相应的参数。
当然, 我们从实际代码中还会发现如下问题:
1. 在函数f中,并未调用4(%esp),而是调用了8(%ebp)获取参数9。
2. 在对9进行压栈后,并未进行弹栈操作。
其原因在于被调用函数中会建立子堆栈,详见2.4节。
2.4 被调用函数的堆栈关系:enter和leave指令
在本文的汇编代码中并没有enter指令,但enter指令等价于如下汇编指令:
pushl %ebp
movl %esp, %ebp这实际上是每个函数入口的两条语句。
而leave指令则等价于:
movl %ebp, %esp
popl %ebp注意到函数g中并没有leave语句,只有popl %ebp语句。这是因为函数g中没有修改esp,因此只需将ebp弹栈。
enter语句在函数入口处,将ebp压栈,并将esp赋给ebp。这样,ebp指针被下移到esp处,相当于构建了一个新的空堆栈。应该注意,原堆栈的内容并没有被覆盖,而是在ebp的上方。此时构建的新堆栈即为函数的子堆栈,函数通过ebp区分函数内部的变量和外部的变量。
leave语句在函数结束处,在ret语句前。它首先将ebp的值赋给esp,而ebp的值正是在enter语句中,由原先的esp赋给ebp的。因此,movl %ebp, %esp语句可以将esp恢复到函数调用前,call语句调用后的状态。接下来,调用pop语句将ebp恢复到函数调用前的状态,即可调用ret语句返回。
这样,就可以回答上一节中的两个问题:
1. 在enter之后,形成了一个新的堆栈,ebp成为原函数堆栈和被调用函数堆栈的分界点。ebp的正前方4(%ebp)是前一个函数的运行位置指针,再往前8(%ebp)即为函数参数的位置。
2. 由于leave语句的存在,函数堆栈可以直接恢复到函数调用前的状态,不需要依次进行弹栈。
3 汇编程序运行过程
综上,我们可以得到汇编语言的整体运行过程,和运行过程中的堆栈变化。假设ebp和esp的初始值为100,运行过程按顺序如下(null表示堆栈空间已开辟,但尚未存入数值):
| eip | 所在函数 | 语句 | eax | ebp | esp | 堆栈内容(括号内是ebp前方的内容) | 下一个eip |
|---|---|---|---|---|---|---|---|
| 18 | main | pushl %ebp | — | 100 | 96 | 100 | 19 |
| 19 | main | movl %esp, %ebp | — | 96 | 96 | 100 | 20 |
| 20 | main | subl $4, %esp | — | 96 | 92 | 100,null | 21 |
| 21 | main | movl $9, (%esp) | — | 96 | 92 | 100,9 | 22 |
| 22 | main | call f | — | 96 | 88 | 100,9,22 | 09 |
| 09 | f | pushl %ebp | — | 96 | 84 | 100,9,22,96 | 10 |
| 10 | f | movl %esp, %ebp | — | 84 | 84 | (100,9,22),96 | 11 |
| 11 | f | subl $4, %esp | — | 84 | 80 | (100,9,22),96,null | 12 |
| 12 | f | movl 8(%ebp), %eax | 9 | 84 | 80 | (100,9,22),96,null | 13 |
| 13 | f | movl %eax, (%esp) | 9 | 84 | 80 | (100,9,22),96,9 | 14 |
| 14 | f | call g | 9 | 84 | 76 | (100,9,22),96,9,14 | 02 |
| 02 | g | pushl %ebp | 9 | 84 | 72 | (100,9,22),96,9,14,84 | 03 |
| 03 | g | movl %esp, %ebp | 9 | 72 | 72 | (100,9,22,96,9,14),84 | 04 |
| 04 | g | movl 8(%ebp), %eax | 9 | 72 | 72 | (100,9,22,96,9,14),84 | 05 |
| 05 | g | addl $5, %eax | 14 | 72 | 72 | (100,9,22,96,9,14),84 | 06 |
| 06 | g | popl %ebp | 14 | 84 | 76 | (100,9,22),96,9,14 | 07 |
| 07 | g | ret | 14 | 84 | 80 | (100,9,22),96,9 | 15 |
| 15 | f | leave | 14 | 96 | 84 | 100,9,22 | 16 |
| 16 | f | ret | 14 | 96 | 88 | 100,9 | 23 |
| 23 | main | addl $3, %eax | 17 | 96 | 88 | 100,9 | 24 |
| 24 | main | leave | 17 | 100 | 100 | — | 25 |
| 25 | main | ret | 17 | — | — | — | — |
其中,leave语句的堆栈变化由两步组成,以15行的语句为例,实际应拆开为:
| eip | 所在函数 | 语句 | eax | ebp | esp | 堆栈内容(括号内是ebp前方的内容) | 下一个eip |
|---|---|---|---|---|---|---|---|
| — | — | 调用leave前 | 14 | 84 | 80 | (100,9,22),96,9 | 15 |
| 15 | f | leave第一步 | 14 | 84 | 84 | (100,9,22),96 | 15 |
| 15 | f | leave第二步 | 14 | 96 | 84 | 100,9,22 | 16 |
可以用图形表示出函数堆栈的调用关系,以03行的状态为例,调用图如下:
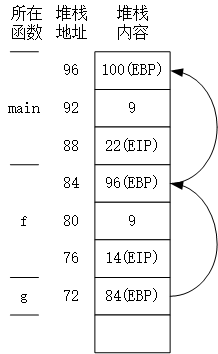
4 小结
本文分析了函数调用过程中的堆栈变化情况,从中可以看出计算机的运行原理:
1. 计算机中的程序采用冯诺依曼结构,即存储程序式结构。程序指令、数据均存在内存中,通过相关的寄存器进行寻址访问。
2. C语言中的函数会被编译为汇编语言中的代码段,以顺序执行为主。不同函数在内存中有不同的入口。
3. 执行到call语句的时候,会把程序当前状态压栈,并跳转到被调用函数的入口。执行到ret语句时,则弹栈并返回调用函数处继续执行。
4. 在函数内部,会构建一个子堆栈,在子堆栈中存入上级堆栈的基地址,以便返回。ebp是子堆栈和传入参数的分界线。
5. 堆栈链是函数调用运行的关键所在。