spring源码阅读(1)- ioc依赖注入之bean解析
首先我们先大致对BeanDefinition做一个宏观功能上的了解:
1、bean的实现类,(可通过实现类的全限定名反射 创建类对象)
2、bean属性数据
3、bean依赖(父类)
4、行为配置-声明周期相关的init-method,destory-method
可见BeanDefinition是实例化bean的核心信息。
而XmlBeanDefinitionReader是spring容器生成beanDefinition途径之一。
下面这个图是XmlBeanDefinitionReader部分类关系图:
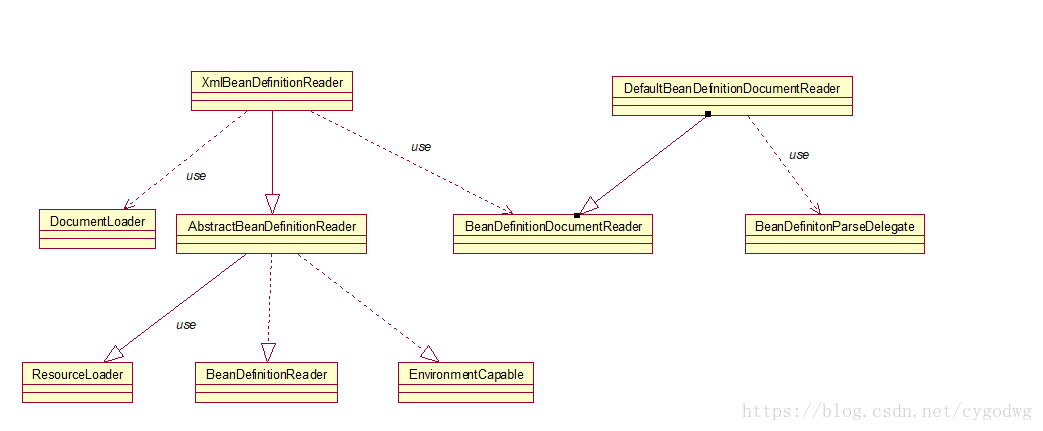
XmlBeanDefinitionReader:是读取并解析xml配置文件生成对应的BeanDefinition列表的重要模块。
XmlBeanDefinitionReader builder = new XmlBeanDefinitionReader(beanFactory);
builder.loadBeanDefinitions(classPathResource);我们从这个代码逐步分析:
1、XmlBeanDefinitionReader的初始化,这里我们获取了几个重要的数据
//解析完read后生成的Document就是这个类来处理,并调用BeanDefinitionRegistry的beanDefinition的注册接口
private Class documentReaderClass = DefaultBeanDefinitionDocumentReader.class;
//这个其实就是Dom解析xml的封装
private DocumentLoader documentLoader = new DefaultDocumentLoader();
public XmlBeanDefinitionReader(BeanDefinitionRegistry registry) {
super(registry);
}
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
this.registry = registry;
// Determine ResourceLoader to use.
if (this.registry instanceof ResourceLoader) {
this.resourceLoader = (ResourceLoader) this.registry;
}
else {
this.resourceLoader = new PathMatchingResourcePatternResolver();
}
// Inherit Environment if possible
if (this.registry instanceof EnvironmentCapable) {
this.environment = ((EnvironmentCapable) this.registry).getEnvironment();
}
else {
this.environment = new StandardEnvironment();
}
}初始化的时候分别确定了处理xml的DocumentLoad,顾名思义就是Document的创建,看源码其实就是对Dom解析xml的封装。
生成的Document再交给DefaultBeanDefinitionDocumentReader解析,从而生成BeanDefinition。
上面是初始化,创建了一些我们解析xml所需要的必要工具。
2 builder.loadBeanDefinitions(classPathResource);
跟着代码跟踪,在XmlBeanDefinitionReader中
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
//从资源中获取输入流
InputStream inputStream = encodedResource.getResource().getInputStream();
InputSource inputSource = new InputSource(inputStream);
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}这里我们看个题外代码
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
InputSource is = new InputSource(new InputStreamReader(logConfigIs));
Document document = db.parse(is);看这个代码是不是很数据,这个就是用org.w3c.dom解析xml。
我们再看上面的那段代码,是不是能看到这个Dom解析xml代码的影子,InputSource是documentBuilder解析的数据源,我们就根据在XmlBeanDefinitionReader中找这个代码。
接着往下看,在DefaultDocumentLoader中
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
Document doc = this.documentLoader.loadDocument(
inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
return registerBeanDefinitions(doc, resource);
}
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
return builder.parse(inputSource);
}这里我们是不是找到了我们要的几个点,创建DocumentBuilderFactory,从工厂创建DocumentBuilder,然后用documentBuild.parse来解析inputSource,生成的结果就是我们要的Document。自此这个类不在继续对Document进行解析了。我们继续向下找
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//这里的documentReader就是DefaultBeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//自此进入了DefaultBeanDefinitionDocumentReader的处理流程了
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
}这个函数进入了DefaultBeanDefinitionDocumentReader的注册bean流程,我们继续看代码
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}这里我们是不是也很熟悉,就是之前生成的Document获取xml根元素
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(this.readerContext, root, parent);
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
}这里我们再看parseBeanDefinitions
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
//对import标签的解析
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//对alias标签的解析
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//对bean标签的解析
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
//对beans标签的解析
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}最后我们跟踪到BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
传入了两个参数,一个是BeanDefinitionHolder,一个是初始化的时候传入的registry
看一下BeanDefinitionHolder
public class BeanDefinitionHolder implements BeanMetadataElement {
private final BeanDefinition beanDefinition;
private final String beanName;
private final String[] aliases;
}这里面已经解析出来了beanDefinition
在看registerBeanDefinition
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
String beanName = definitionHolder.getBeanName();
//这里就调用了传入的registry也就是DefaultListableBeanFactory
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String aliase : aliases) {
registry.registerAlias(beanName, aliase);
}
}
}这里就根据解析出来的beandefiniiton调用初始化XmlBeanDefinitionReader时候传入的工厂DefaultListableBeanFactory的注册beanDefinition和注册别名
我们再来看看DefaultListableBeanFactory下的这些函数
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
synchronized (this.beanDefinitionMap) {
this.beanDefinitionNames.add(beanName);
this.frozenBeanDefinitionNames = null;
this.beanDefinitionMap.put(beanName, beanDefinition);
}
resetBeanDefinition(beanName);
}这里我们注意两个属性:beanDefinitionNames和beanDefinitionMap
beanDefinitionNames是一个ArrayList
beanDefinitionMap是一个ConcurrencyHashMap
自此资源解析结束,资源解析结果是获取了一个ArrayList和一个ConcurrencyHashMap
总结:
XmlBeanDefinitionReader就是对Dom解析xml的封装,将xml文件解析成BeanDefinition保存到DefaultListableBeanFactory下面的两个属性:
ArrayList-beanDefinitionNames,已经加载的bean名称
ConcurrencyHashMap-beanDefinitionMap,以加载的BeanDefinitonMap