hadoop系列文档3-配置Hdfs高可用HA
版权声明:本文为博主原创文章,未经博主允许不得转载。
目录(?)[-]
- 背景
- 架构设计
- 如何配置HAQJM
- 分配每个节点需要安装的服务
- hdfs-sitexml中的配置信息
- Core-sitexml中的配置
- 如何启动
- Step1 启动JournalNode集群
- Step2 格式化NameNode
- Step3 转成Active
- Zookeeper应用自动灾难恢复
- Step1 首先你得配置好Zookeeper集群
- Step2 hdfs-sitexml配置
- Step3 core-sitexml配置
- Step4 初始化HA
- Step5 启动dfs
- Step6 测试zk是否能自动切换主备Namenod
背景
早在Hadoop2.0.0之前,在一个HDFS集群中,只有一个NameNode,如何这个NameNode因为某种原因挂掉了(SPOF),那么整个集群将不可用。
参考文章
http://www.cnblogs.com/meiyuanbao/p/hadoop2.html
http://blog.csdn.net/skywalker_only/article/details/40300839
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
架构设计
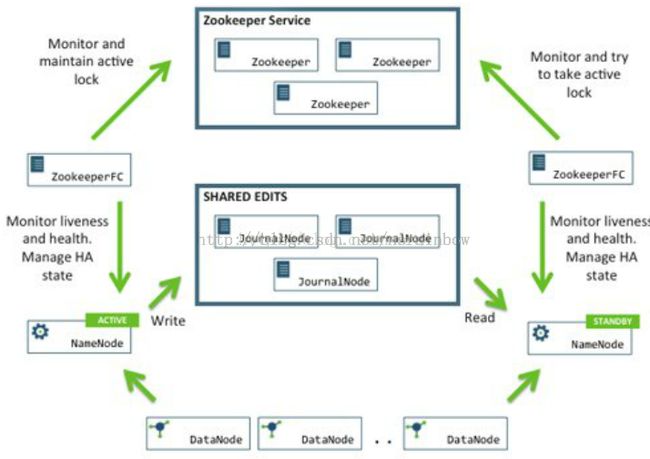
在一个典型的HA集群中,两台独立的机器被配置成NameNodes。在任意时间,有且只允许以个活动的NameNodes,另外一个备用。这个活动的NameNode对集群内所有的客户端的操作的负责,另一个备用的只是简单的扮演一个slave,维持足够的状态以便在必要的提供一个快速得故障转移。
为了使备用的节点能和活动的节点有保持同步的状态,这两节点引入一个新的进程,名为“JournalNodes”。当活动节点的命名空间内有任何改动时,那么在这些JNS中会永久的记录下修改的内容。然后备用的节点会从JNS中读取这些修改,并且不断地观察这些变化。然后备用节点将会看到这些改变,并且应用到自己的命名空间中去。在故障转移之前,备用的节点将会确保已经从JournNodes中读取了所有的修改内同在使自己演变成活动的节点之前。这将会确保在灾难发生之前,命名空间的状态是完全同步的。
为了提供快速得故障转移,让备用的节点获取集群中最新的块的位置是必要的。为何实现这个目的,DataNodes被配置成包含两个NameNodes的位置,并且可以发送块位置的信息和心跳包给彼此。
正确配置HA集群使Namenodes中的一个在同一时间只允许运行一个也是至关重要的,否则,命名空间的状态将会很快的被两个所紊乱,将会导致数据丢失和其他不正确的结果。为了确保性能组织称之为“split-brain scenario”的发生,JournalNodes将会只允许在同一时刻只有一个单独的NameNode是可写的状态。在灾难期间,那个将成为活动节点的NameNode将只是简单得接管写入JournalNodes的权限,这将会有效地阻止另一个节点继续得保持活动的状态,保证了新的节点在灾难期间安装的运行。
如何配置HA(QJM)
注意,在此之前,请先确保已经安装Hadoop集群,已经安装zookeeper集群。
分配每个节点需要安装的服务:
在上述基础上,介绍关系配置信息
hdfs-site.xml中的配置信息
dfs.nameservices 命名空间的逻辑名称。如果使用HDFS Federation,可以配置多个命名空间的名称,使用逗号分开即可。
-
-
dfs.nameservices -
mycluster
dfs.ha.namenodes.[nameservice ID] – 命名空间中namenodes的id
-
dfs.ha.namenodes.mycluster -
nn1,nn2
dfs.namenode.rpc-address.[nameserviceID].[name node ID] 每个namenode监听的RPC地址。如下所示
-
dfs.namenode.rpc-address.mycluster.nn1 -
machine1.example.com:8020 -
dfs.namenode.rpc-address.mycluster.nn2 -
machine2.example.com:8020
dfs.namenode.http-address.[nameserviceID].[name node ID] 每个namenode监听的http地址。如下所示
-
dfs.namenode.http-address.mycluster.nn1 -
machine1.example.com:50070 -
dfs.namenode.http-address.mycluster.nn2 -
machine2.example.com:50070
dfs.namenode.shared.edits.dir 这是NameNode读写JNs组的uri。通过这个uri,NameNodes可以读写edit log内容。URI的格式"qjournal://host1:port1;host2:port2;host3:port3/journalId"。这里的host1、host2、host3指的是Journal Node的地址,这里必须是奇数个,至少3个;其中journalId是集群的唯一标识符,对于多个联邦命名空间,也使用同一个journalId。配置如下
-
dfs.namenode.shared.edits.dir -
qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster
dfs.client.failover.proxy.provider.[nameservice ID]这里配置HDFS客户端连接到Active NameNode的一个java类。
-
dfs.client.failover.proxy.provider.mycluster -
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods配置active namenode出错时的处理类。当active namenode出错时,一般需要关闭该进程。处理方式可以是ssh也可以是shell。
如果使用ssh,配置如下
-
-
dfs.ha.fencing.methods -
sshfence -
-
dfs.ha.fencing.ssh.private-key-files -
/home/exampleuser/.ssh/id_rsa
下面是我自己配置好的文件:

Core-site.xml中的配置
-
-
fs.defaultFS -
hdfs://mycluster
-
dfs.journalnode.edits.dir -
/path/to/journal/node/local/data
下面是我自己的配置:

如何启动
在这之前,先停掉正在运行的hadoop集群。
Step1 启动JournalNode集群
- hadoop-daemon.shstart journalnode
因为我们配置的JournalNode集群是

所以在134.133.131上,使用上述命令如下图
成功启动后,你会看到有如下进程:

类似得在132,133上都启动,如下图

然后在我们部署JournalNode的集群上会有我配置的文件夹
Step2 格式化NameNode
注意官方指明:

如果是一个新的HDFS集群,还要首先执行格式化命令“hdfs namenode -format”,紧接着启动本NameNode进程。
如果存在一个已经格式化过的NameNode,并且已经启动了。那么应该把该NameNode的数据同步到另一个没有格式化的NameNode。在未格式化过的NameNode上执行命令“hdfs namenode -bootstrapStandby”。
如果是把一个非HA集群转成HA集群,应该运行命令“hdfs –initializeSharedEdits”,这会初始化JournalNode中的数据。
所以根据我们的实际情况,我们已经有一个格式化过的NameNode.
a. 启动原先已经存在也就是135的namenode使用命令 hadoop-daemon.sh start namenode
hadoop-daemon.sh start namenode
b.格式化我们第二个namenode也是134
hdfsnamenode -bootstrapStandby

c.启动134的namenode
hadoop-daemon.sh start namenode

此时如果配置正确,打开浏览器172.21.99.134:50070和172.21.99.135:50070将会看到两个namenode的配置界面,并且状态都是standy状态

****注意,这边如何通过http方式访问不了,切记要关闭防火墙
参考
http://blog.csdn.net/bslzl/article/details/7937899
Step3 转成Active
hdfs haadmin -transitionToActive nn1
成功启动如下图
Zookeeper应用自动灾难恢复
整个流程的示意图:
Step1 首先你得配置好Zookeeper集群
并且至少有3个奇数节点,这样才能允许有 n-1 /2个故障。
Step2 hdfs-site.xml配置
-
dfs.ha.automatic-failover.enabled -
true
Step3 core-site.xml配置
-
ha.zookeeper.quorum -
zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181
Step4 初始化HA
- hdfs zkfc -formatZK
Step5 启动dfs
- hadoop-daemon.sh start zkfc
此时会有如下的进程出现

Step6 测试zk是否能自动切换主备Namenod
查看 135 的http网页

查看 134的 httP网页

手动把135的namenode 进程结束
发现已经自动切换成功