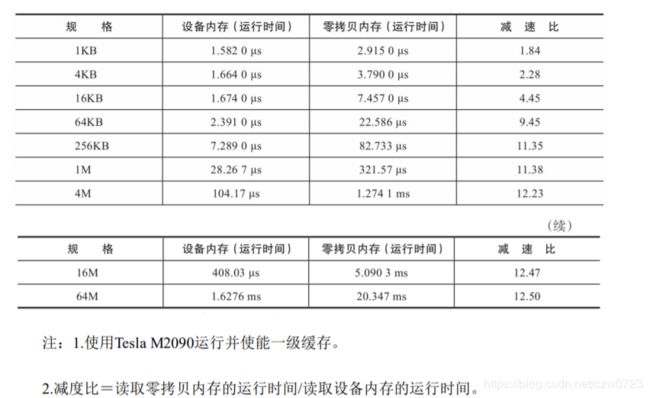
CUDA 零拷贝内存
一个简单的测试程序:
#include
#include
__global__ void sumArraysZeroCopy(float *A, float *B, float *C, const int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i] +1000;
}
void initialData(float *ip, int size)
{
int i;
for (i = 0; i < size; i++)
{
ip[i] = (float)( rand() & 0xFF ) / 10.0f;
}
return;
}
void display(float * f,int num){
for(int i=0;i>>(d_A,d_B,d_C,num+1);
cudaMemcpy(gpuBuf,d_C,sizeof(float)*num, cudaMemcpyDeviceToHost);
display(gpuBuf,num);
display(h_C,num);
} 输出的结果:

这就充分说明了,cuda里面使用的还是主机的内存。。从CUDA权威编程指南里面看到应该就是通过使用PCLe通道搞得。