安居客二手房信息爬取
本文实现爬取安居客二手房房源信息,并保存到本地csv文本中
爬取网址:https://tianjin.anjuke.com/sale/hexi/(天津河西区二手房房源)
思路
1.构造请求地址:通过分析网站,可发现页面规律
url="https://tianjin.anjuke.com/sale/hexi/p"+str(i)#i为第i页2.页面内容
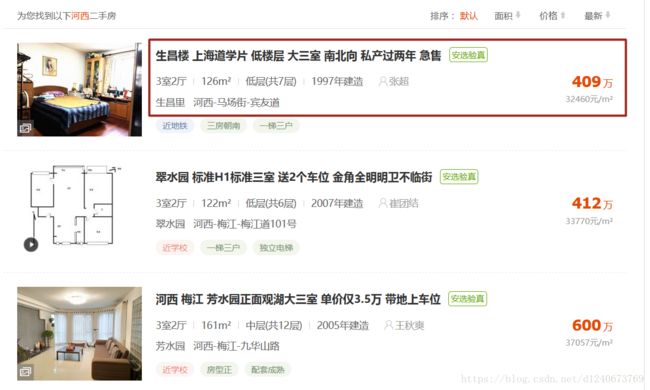
主要爬取框中的信息:如标题、url链接、户型、面积、价格、均价等信息;通过分析页面源代码,可发现这些信息都可以通过正则或者xpath进行提取(本文使用xpath进行提取,提取规则可参考后面代码)。
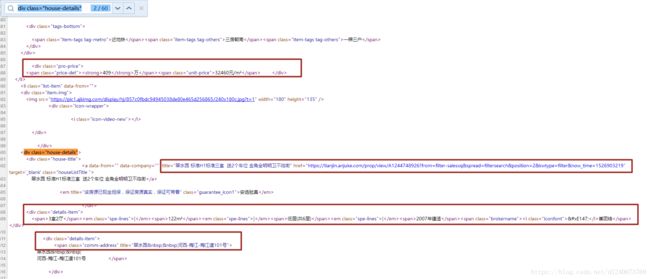
3.实现自动翻页:本文利用while循环,让页码自增,通过判断新打开的页面url是否存在来确定当前打开的页面是否是最后一页。(通过测试,发现当打开不存在的页面时,如https://tianjin.anjuke.com/sale/hexi/p1000,会自动跳转到https://tianjin.anjuke.com/sale/,因此可以通过判断新打开的页面返回的url是否为https://tianjin.anjuke.com/sale/,来决定程序是否结束)
代码
import urllib.request
from lxml import etree
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
class AnJuke():
def __init__(self,url):
self.url=url
def get_data(self):
try:
page_headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240",
"Cookie":"lps=http%3A%2F%2Fwww.anjuke.com%2F%3Fpi%3DPZ-baidu-pc-all-biaoti%7Chttps%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3D%25E5%25AE%2589%25E5%25B1%2585%25E5%25AE%25A2%26rsv_spt%3D1%26rsv_iqid%3D0xcd19993e00074b01%26issp%3D1%26f%3D8%26rsv_bp%3D0%26rsv_idx%3D2%26ie%3Dutf-8%26rqlang%3D%26tn%3Dbaiduhome_pg%26ch%3D%26rsv_enter%3D1%26inputT%3D3712; sessid=07475D2A-2B7F-AB74-9AA7-D2A0A0C9405B; als=0; lp_lt_ut=6117644281897975bfb831788e688228; ajk_member_captcha=18e942dc45afd9f788d4802593f9fae6; ctid=17; isp=true; Hm_lvt_c5899c8768ebee272710c9c5f365a6d8=1526803037; Hm_lpvt_c5899c8768ebee272710c9c5f365a6d8=1526803346; __xsptplusUT_8=1; _gat=1; __xsptplus8=8.2.1526802941.1526805099.14%232%7Cwww.baidu.com%7C%7C%7C%25E5%25AE%2589%25E5%25B1%2585%25E5%25AE%25A2%7C%23%236CuavhY4MOpRuaHFmbyj9N7jDwOnoRLH%23; _ga=GA1.2.1600018811.1526800135; _gid=GA1.2.412546660.1526800135; aQQ_ajkguid=6293A1E9-F0DF-E29D-5EBC-1579C952C81F; twe=2; 58tj_uuid=fca5993b-462b-4bae-a3f9-631c589797d6; new_session=0; init_refer=https%253A%252F%252Fbeijing.anjuke.com%252F%253Fpi%253DPZ-baidu-pc-all-biaoti; new_uv=2"
}
req=urllib.request.Request(self.url,headers=page_headers)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
code=urllib.request.urlopen(req).code
uri=urllib.request.urlopen(req).url
#print(code)
#print(uri)
return code,uri,data
except Exception as e:
print(str(e))
return 0,0,0
def get_house(self):
code,uri,data=self.get_data()
if uri!="https://tianjin.anjuke.com/sale/" and code==200:
html=etree.HTML(data)
house_title=html.xpath('//div[@class="house-details"]/div[@class="house-title"]/a/@title')
#print(house_title)
house_url=html.xpath('//div[@class="house-details"]/div[@class="house-title"]/a/@href')
#print(house_url)
house_huxing=html.xpath('//div[@class="house-details"]/div[@class="details-item"][1]/span[1]/text()')
#print(house_huxing)
house_area=html.xpath('//div[@class="house-details"]/div[@class="details-item"][1]/span[2]/text()')
house_floor=html.xpath('//div[@class="house-details"]/div[@class="details-item"][1]/span[3]/text()')
house_time=html.xpath('//div[@class="house-details"]/div[@class="details-item"][1]/span[4]/text()')
house_location=html.xpath('//div[@class="house-details"]/div[@class="details-item"][2]/span/@title')
house_price=html.xpath('//div[@class="pro-price"]/span[1]/strong/text()')
house_avgp=html.xpath('//div[@class="pro-price"]/span[2]/text()')
#将房价信息写入文本中
n=len(house_title)
if len(house_location)==len(house_huxing)==len(house_area)==len(house_price)==len(house_avgp)==len(house_floor)==len(house_time)==len(house_url)==n:
with open('house_anjuke.csv','a+',encoding='utf-8') as fh:
for i in range(n):
fh.write(house_location[i].replace('\xa0\xa0',':').replace(',',';')+","+house_huxing[i]+","+house_area[i]+","+house_price[i]+"万,"+house_avgp[i]+","+house_floor[i]+","+house_time[i]+","+house_title[i].replace(',',';')+","+house_url[i]+"\n")
return uri
if __name__=='__main__':
try:
url_start="https://tianjin.anjuke.com/sale/hexi/"
with open('house_anjuke.csv','w',encoding='utf-8') as fh:
fh.write("位置,户型,面积,价格,均价,楼层,建造时间,标题,网页链接\n")
i=1
house=AnJuke(url_start)
uri=house.get_house()
while uri!='https://tianjin.anjuke.com/sale/':
print("第"+str(i)+"页爬取完成")
i+=1
print("正在爬取第"+str(i)+"页...")
url=url_start+"p"+str(i)+"/"
house=AnJuke(url)
uri=house.get_house()
except Exception as e:
print(str(e))