精讲Spark Streaming集成读取kafka0.10及以上版本
前言
Spark版本:2.1.2
JDK版本:1.8
Scala版本:2.11.8
Linux版本:CentOS6.9
IDEA版本:2017.3
Kafka连接jar包:spark-streaming-kafka-0-10_2.11 (2.1.2)
每次重新搭建环境都或多或少地去网上搜一下,这次终于狠下心把它写出来。
仔细阅读了英文官方文档,又参考了好多博客,花了二天时间才写完。
真没有想到要用这么久,看来会用与写出来形成自己的东西还是有很大差距的啊。
博客以官方文档的意思为主,加上自己的理解和实践,形成此文
想看原汁原味的可以点下面的链接:
http://spark.apache.org/docs/2.1.2/streaming-kafka-0-10-integration.html
添加Kafka依赖
首先Spark添加kafka依赖(Maven):
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>2.1.2version>
dependency>
Spark2.2.X一样用,Spark2.3没有试
Direct Approach方式读取Kafka数据
在实际的应用中,Direct Approach方式可以很好地满足需要,与Receiver-based方式相比,有以下几方面的优势:
- 降低资源
Direct不需要Receivers,其申请的Executors全部参与到计算任务中;而Receiver-based则需要专门的Receivers来读取Kafka数据且不参与计算。因此相同的资源申请,Direct 能够支持更大的业务。
- 降低内存
Receiver-based的Receiver与其他Exectuor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并无那么多的内存。而Direct 因为没有Receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。实际应用中我们可以把原先的10G降至现在的2-4G左右。
- **稳定性更好 **
Receiver-based方法需要Receivers来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receivers却还在持续读取数据,此种情况很容易导致计算崩溃。Direct 则没有这种顾虑,其Driver在触发batch 计算任务时,才会读取数据并计算。队列出现堆积并不会引起程序的失败。
- 其他方面的优势-
比如 简化并行(Simplified Parallelism)、高效(Efficiency)以及强一致性语义(Exactly-once semantics)。
虽然Direct 有以上这些优势,但是也存在一些不足,具体如下:
- 提高成本-
Direct需要用户采用checkpoint或者第三方存储来维护offsets,而不像Receiver-based那样,通过ZooKeeper来维护Offsets,此提高了用户的开发成本。
一个完整的Demo
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
SparkConf conf = new SparkConf().setAppName("demo").setMaster("local[4]");
JavaStreamingContext streamingContext = new JavaStreamingContext(conf, Durations.seconds(8));
Map<String, Object> kafkaParams = new HashMap<>();
//Kafka服务监听端口
kafkaParams.put("bootstrap.servers", "cm02.spark.com:9092");
//指定kafka输出key的数据类型及编码格式(默认为字符串类型编码格式为uft-8)
kafkaParams.put("key.deserializer", StringDeserializer.class);
//指定kafka输出value的数据类型及编码格式(默认为字符串类型编码格式为uft-8)
kafkaParams.put("value.deserializer", StringDeserializer.class);
//消费者ID,随意指定
kafkaParams.put("group.id", "jis");
//指定从latest(最新,其他版本的是largest这里不行)还是smallest(最早)处开始读取数据
kafkaParams.put("auto.offset.reset", "latest");
//如果true,consumer定期地往zookeeper写入每个分区的offset
kafkaParams.put("enable.auto.commit", false);
//要监听的Topic,可以同时监听多个
Collection<String> topics = Arrays.asList("test");
final JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
);
stream.mapToPair(
new PairFunction<ConsumerRecord<String, String>, String, String>() {
@Override
public Tuple2<String, String> call(ConsumerRecord<String, String> record) {
return new Tuple2<>(record.key(), record.value());
}
});
pairDS.print();
jssc.start();
jssc.awaitTermination();
这里默认Spark、Kafka已经安装好了
在Kafka根目录下执行以下命令
启动Kafka
bin/kafka-server-start.sh config/server.properties
启动生产者,Topic命名为test
bin/kafka-console-producer.sh --broker-list cm02.spark.com:9092 --topic test

在IntelliJ IDEA里运行local模式的SparkStreaming
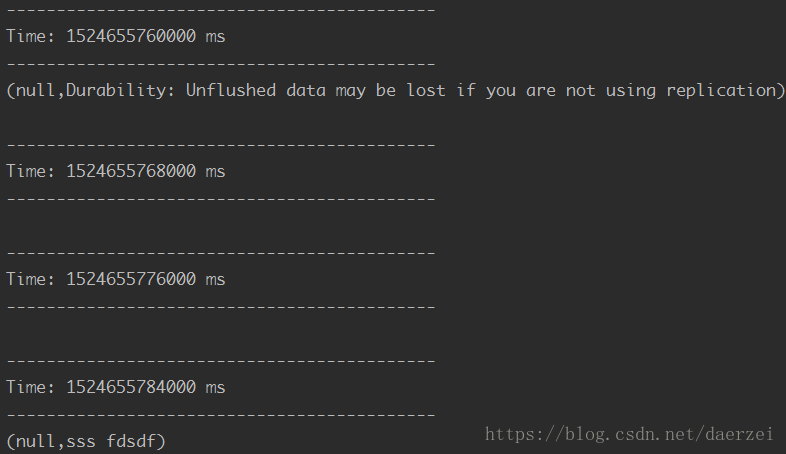
OK,到这里实现已经实现了,Direct 方式有什么优点,有什么不同,程序中各个参数是什么意思相信你大致都明白了,做一个Demo,或者解决问题应该都没有问题吧有问题可以留言哈。
上面讲的基本使用加面试已经就够用了, 有时间就继续看,赶项目就去Coding吧。
下面讲的都是一些参数啊,原理啊什么的,更深入些。
LocationStrategies(本地策略)
新版本的Kafka消费者API会将预先获取的消息写入缓存。因此,Spark在Executor端缓存消费者(而不是每次都重建)对于性能非常重要 ,并且系统会自动为分区分配在同一主机上的消费者进程(如果有的话)
一般来讲,你最好像上面的Demo一样使用LocationStrategies的PreferConsistent方法。
它会将分区数据尽可能均匀地分配给所有可用的Executor。
题外话:本地化策略看到这里就行了,下面讲的是一些特殊情况。
- 情况一
如果你的Executor和kafka broker在同一台机器上,可以用PreferBrokers,这将优先将分区调度到kafka分区leader所在的主机上。
题外话:废话,Executor是随机分布的,我怎么知道是不是在同一台服务器上?除非是单机版的are you明白? - 情况二
分区之间的负荷有明显的倾斜,可以用PreferFixed。这个允许你指定一个明确的分区到主机的映射(没有指定的分区将会使用连续的地址)。
题外话:就是出现了数据倾斜了呗
Kafka的最大分区数
消费者缓存的数目默认最大值是64。如果你希望处理超过(64*excutor数目)kafka分区,配置参数:spark.streaming.kafka.consumer.cache.maxCapacity
是否禁止Kafka消费者缓存
如果你想禁止kafka消费者缓存,可以将spark.streaming.kafka.consumer.cache.enabled修改为false。禁止缓存缓存可能需要解决SPARK-19185描述的问题。一旦这个bug解决,这个属性将会在后期的spark版本中移除(Spark2.2.1的Bug)。
缓存的唯一性
Cache是根据topic的partition和groupid来唯一标识的,所以每次调用createDirectStream的时候要单独设置group.id。
消费者策略:
新的Kafka消费者API有许多不同的方式来指定主题。它们相当多的是在对象实例化后进行设置的。ConsumerStrategies提供了一种抽象,它允许Spark即使在checkpoint重启之后(也就是Spark重启)也能获得配置好的消费者。
ConsumerStrategies允许订阅确切指定的一组Topic。ConsumerStrategies的Subscribe方法通过一个确定的集合来指定TopicConsumerStrategies的SubscribePattern方法允许你使用正则表达式来指定Topic,
注意,与0.8集成不同,在SparkStreaming运行期间使用Subscribe或SubscribePattern,应该响应添加分区。
最后,ConsumerStrategies.Assign()方法允许指定固定的分区集合。
所有三个策略(Subscribe,SubscribePattern,Assign)都有重载的构造函数,允许您指定特定分区的起始偏移量。
如果上述不满足您的特定需求,可以对ConsumerStrategy进行扩展、重写
到这里Direct方式参数和原理也讲完了,下面bibi了一堆其他的没用的,至少不常用,如果你还有耐心的话可以留着看其他更重要的部分,如果你还有心情的话想看还可以看看(博客写到这里我真是没有心情了,太难翻译了,休息一下再写吧)
创建一个RDD(Creating an RDD)
这部分官网罗里罗嗦一大堆,没看明白什么意思,看了好多博客,又跑了几次程序才明白是怎么回事。
意思就是原来是通过时间来取数据的,比如说一次取个5秒的数据什么的,这个方法是根据条数来取的,比如说一次取个100条,但是没有看明白的是:这不是SparkStreaming吗?怎么成RDD了?RDD怎么进行流式数据处理啊?然后下面又给出了一个例子
OffsetRange[] offsetRanges = {
// topic, partition, inclusive starting offset, exclusive ending offset
//参数依次是Topic名称,Kafka哪个分区,开始位置(偏移),结束位置
OffsetRange.create("test", 0, 0, 100),
OffsetRange.create("test", 1, 0, 100)
};
//注意,这里返回的是一个RDD
JavaRDD<ConsumerRecord<String, String>> rdd = KafkaUtils.createRDD(
sparkContext,
kafkaParams,
offsetRanges,
LocationStrategies.PreferConsistent()
);
获取偏移
在进行流式批处理的时候根据条数取数据还是有点用的,官网给出了一个例子
stream.foreachRDD(new VoidFunction<JavaRDD<ConsumerRecord<String, String>>>() {
@Override
public void call(JavaRDD<ConsumerRecord<String, String>> rdd) {
//获取偏移
final OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
rdd.foreachPartition(new VoidFunction<Iterator<ConsumerRecord<String, String>>>() {
@Override
public void call(Iterator<ConsumerRecord<String, String>> consumerRecords) {
OffsetRange o = offsetRanges[TaskContext.get().partitionId()];
//获取Topic,Partition,起始偏移量,结束偏移量
System.out.println(
o.topic() + " " + o.partition() + " " + o.fromOffset() + " " + o.untilOffset());
}
});
}
});
存储偏移
不按官方的翻译了,这段的大致意思是:要想在任何情况下(注意是任何情况)都保证Kafka的数据都只被消费一次你还需要存储一下Kafka的偏移量,有三种方式来存储Kafka的偏移量。
- 第一种方式:
Checkpoint(Spark的一个持久化机制)
这种方式很容易做到,但是有以下的缺点:
多次输出,结果必须满足幂等性(什么意思自己Google)
事务性不可选
如果代码变更不能从Checkpoint恢复,不过你可以同时运行新任务和旧任务,因为输出结果具有等幂性
- 二种方式:Kafka自身
Kafka提供的有api,可以将offset提交到指定的kafkatopic。默认情况下,新的消费者会周期性的自动提交offset到kafka。但是有些情况下,这也会有些问题,因为消息可能已经被消费者从kafka拉去出来,但是spark还没处理,这种情况下会导致一些错误。这也是为什么例子中stream将enable.auto.commit设置为了false。然而在已经提交spark输出结果之后,你可以手动提交偏移到kafka。相对于checkpoint,offset存储到kafka的好处是:kafka既是一个容错的存储系统,也是可以避免代码变更带来的麻烦。然而,Kafka不是事务性的,所以你的输出必须仍然是幂等的。
stream.foreachRDD(new VoidFunction<JavaRDD<ConsumerRecord<String, String>>>() {
@Override
public void call(JavaRDD<ConsumerRecord<String, String>> rdd) {
OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
// some time later, after outputs have completed
((CanCommitOffsets) stream.inputDStream()).commitAsync(offsetRanges);
}
});
- 第三种方式:自定义存储位置
对于支持事务的数据存储,即使在故障情况下,也可以在同一事务中保存偏移量作为结果,以保持两者同步。如果您仔细检查重复或跳过的偏移范围,则回滚事务可防止重复或丢失的邮件影响结果。这给出了恰好一次语义的等价物。也可以使用这种策略甚至对于聚合产生的输出,聚合通常很难使幂等。
// The details depend on your data store, but the general idea looks like this
// begin from the the offsets committed to the databaseMap fromOffsets = new HashMap<>();for (resultSet : selectOffsetsFromYourDatabase)
fromOffsets.put(new TopicPartition(resultSet.string("topic"), resultSet.int("partition")), resultSet.long("offset"));}
JavaInputDStream<ConsumerRecord<String, String>> stream = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Assign(fromOffsets.keySet(), kafkaParams, fromOffsets));
stream.foreachRDD(new VoidFunction<JavaRDD<ConsumerRecord<String, String>>>() {
@Override
public void call(JavaRDD<ConsumerRecord<String, String>> rdd) {
OffsetRange[] offsetRanges = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
Object results = yourCalculation(rdd);
// begin your transaction
// update results
// update offsets where the end of existing offsets matches the beginning of this batch of offsets
// assert that offsets were updated correctly
// end your transaction
}});
##SSL/TLS配置使用
全称是传输层安全性协定,用于Spark与Kafka进行安全通信
启用它只需要 在执行createDirectStream / createRDD之前设置kafkaParams这仅仅应用与Spark和kafkabroker之间的通讯
Map<String, Object> kafkaParams = new HashMap<String, Object>();
// the usual params, make sure to change the port in bootstrap.servers if 9092 is not TLS
kafkaParams.put("security.protocol", "SSL");
kafkaParams.put("ssl.truststore.location", "/some-directory/kafka.client.truststore.jks");
kafkaParams.put("ssl.truststore.password", "test1234");
kafkaParams.put("ssl.keystore.location", "/some-directory/kafka.client.keystore.jks");
kafkaParams.put("ssl.keystore.password", "test1234");
kafkaParams.put("ssl.key.password", "test1234");
有什么问题欢迎评论啊
辛苦写了这么多如果觉得有用就点个赞吧,您解决问题我,我增加积分哈