极速入门 正则表达式
正则表达式极速入门
正则表达式到底是什么东西?
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过Windows/Dos下用于文件查找的通配符(wildcard),也就是*和?。如果你想查找某个目录下的所有的Word文档的话,你会搜索*.doc。在这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。0\d{2}-\d{8}|0\d{3}-\d{7}
元字符
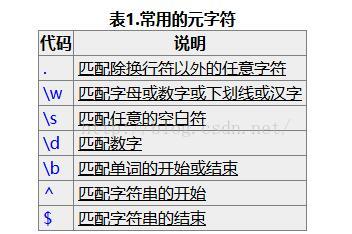
元字符^(和数字6在同一个键位上的符号)和$都匹配一个位置,这和\b有点类似。^匹配你要用来查找的字符串的开头,$匹配结尾。这两个代码在验证输入的内容时非常有用,比如一个网站如果要求你填写的QQ号必须为5位到12位数字时,可以使用:^\d{5,12}$。
这里的{5,12}和前面介绍过的{2}是类似的,只不过{2}匹配只能不多不少重复2次,{5,12}则是重复的次数不能少于5次,不能多于12次,否则都不匹配。
因为使用了^和$,所以输入的整个字符串都要用来和\d{5,12}来匹配,也就是说整个输入必须是5到12个数字,因此如果输入的QQ号能匹配这个正则表达式的话,那就符合要求了。
和忽略大小写的选项类似,有些正则表达式处理工具还有一个处理多行的选项。如果选中了这个选项,^和$的意义就变成了匹配行的开始处和结束处。
字符转义
如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用\.和\*。当然,要查找\本身,你也得用\\.
例如:deerchao\.net匹配deerchao.net,C:\\Windows匹配C:\Windows。
重复
你已经看过了前面的*,+,{2},{5,12}这几个匹配重复的方式了。下面是正则表达式中所有的限定符(指定数量的代码,例如*,{5,12}等):

下面是一些使用重复的例子:
Windows\d+匹配Windows后面跟1个或更多数字
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
字符类
要想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)。
我们也可以轻松地指定一个字符范围,像[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话,/w是包含汉字的)。
下面是一个更复杂的表达式:\(?0\d{2}[)-]?\d{8}。
“(”和“)”也是元字符,后面的分组节里会提到,所以在这里需要使用转义。
这个表达式可以匹配几种格式的电话号码,像(010)88886666,或022-22334455,或02912345678等。我们对它进行一些分析吧:首先是一个转义字符\(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。
分枝条件
不幸的是,刚才那个表达式也能匹配010)12345678或(022-87654321这样的“不正确”的格式。要解决这个问题,我们需要用到分枝条件。正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。就是编程语言中或的意思,听不明白?没关系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\(?0\d{2}\)?[- ]?\d{8}|0\d{2}[- ]?\d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用分枝条件把这个表达式扩展成也支持4位区号的。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用分枝条件时,要注意各个条件的顺序。如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
分组
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作(后面会有介绍)。
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3}匹配1到3位的数字,(\d{1,3}\.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
IP地址中每个数字都不能大于255. 经常有人问我, 01.02.03.04 这样前面带有0的数字, 是不是正确的IP地址呢? 答案是: 是的,IP地址里的数字可以包含有前导0 (leading zeroes).
不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址。IP地址中每个数字都不能大于255.
如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解这个表达式的关键是理解2[0-4]\d|25[0-5]|[01]?\d\d?,我们可以这样理解,先把所有可能写出,即200到249,250到255,000到199这三种形式,这里我们用|符号连接三种可能,2[0-4]\d即表示200到249,25[0-5]即表示50到255,[01]?\d\d?即表示000到199,你理解了吗?
总结
正则表达式比较难理解,应该多花点时间在上面,注意实践,时间出真知嘛.