Python爬虫学习三——re库
Python爬虫学习三——re库
- Python爬虫学习三re库
- re简介
- re基本语法
- re库的使用
- 1 re库主要函数
- 2 match对象
- 3 贪婪匹配和最小匹配
bs库是提取网页内容的一种方法,另外一种提取网页感兴趣内容的方法就是使用re库,通过匹配得到对应的字符串。
1 re简介
re、regex、regular expression、正则表达式,一个意思。正则表达式是用来简洁表达一组字符串的表达式。正则表达式使用的是特征,和python一样具有简单优雅的特点。正则表达式的应用十分广泛,最常见也最容易视而不见的地方就是文本搜索,如word中搜索高级选项中就有使用正则表达式一项,勾选之后可以使用正则表达式来搜索具有某种特征的文本内容。
初看正则表达式,如”-?\d+$”,会有“这确定不是乱码?”的疑问,深入学习之后,就会发现一个新世界。本人水平有限,本文仅介绍简单的正则表达式。对了,上述乱码似的正则表达式表示的是整数形式的字符串。
re库是python中的默认库,无论你安装基本的python环境还是anaconda等集成环境,都已经安装了re库,可以使用import re来测试。
2 re基本语法
正则表达式语言由字符和操作符构成。常用的正则表达式操作符有:


下面,结合几个范例,具体介绍上述操作符:
PYTHON++操作符表示前一个字符的1次或无限次扩展,因此上面的正则表达式对应的字符串是’PYTHON’、’PYTHONN’、’PYTHONNN’…等等,’N’的次数可以有无限次。
a\d{:3}\d表示数字,{}表示前一个字符出现的次数,这里出现了表格中没有的冒号,{:3}和{0,3}表示的意思一致,因此上述正则表达式对应的字符串是以a开头,后接3个以下数字的字符串。
经典的正则表达式实例:
'^[A-Za-z]+$' ### 26个字母组成的字符串
'^[A-Za-z0-9]+$' ### 26个字母和数字组成的字符串
'^[0-9]*[1-9][0-9]*$' ### 正整数形式的字符串
'[1-9]\d{5}' ### 中国境内邮政编码,6位
'[\u4e00-\u9fa5]' ### 中文字符串
'\d{3}-\d{8}|\d{4}-\d{7}' ### 国内电话号码3 re库的使用
re库采用原生字符串类型(raw string)表示正则表达式。原生字符串是不包含对转义字符再次转义的字符串,看起来有点绕,如’\\d’表示’\’后面接数字,如果不是原生字符串,就只是表示数字。string类型也可以表示正则表达式,但更为繁琐,因此建议使用raw string。
3.1 re库主要函数
re库主要有以下函数:
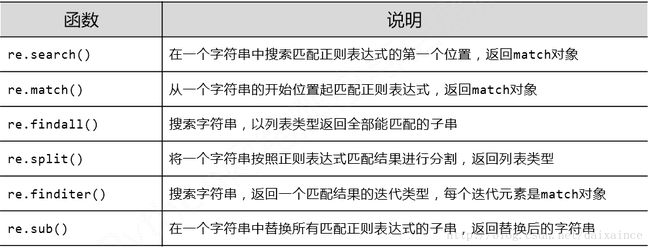
上述函数的原型为:
re.search(pattern, string, flags=0)
re.match(pattern, string, flags=0)
re.findall(pattern, string, flags=0)
re.split(pattern, string, maxsplit=0, flags=0)
re.finditer(pattern, string, flags=0)
re.sub(pattern, repl, string, count=0, flags=0)pattern表示正则表示的字符串
string表示待匹配的字符串
flags表示正则表达式使用时的控制标记,主要有re.I,忽略正则表达式的大小写;re.M,表示’^’能够将给定字符串的每行作为匹配的开始;re.S,表示’.’能够匹配所有字符,默认匹配除换行符外的所有字符。
maxsplit表示最大分割数,剩余部分作为最后一个元素输出
repl表示替换所用的字符串
count表示匹配的最大替换次数
re库中的主要函数还有另外一种替代用法,就是使用re.compile函数,以search函数为例,可以用以下代替:
str = 'BIT 100081'
pattern = r'[1-9]\d{5}'
reg = re.compile(pattern)
match = pat.search(str)re库的函数返回对象不少都是match对象,下面单独介绍match对象。
3.2 match对象
match对象是一次匹配的结果,包含匹配的很多信息,match对象主要有四个属性:
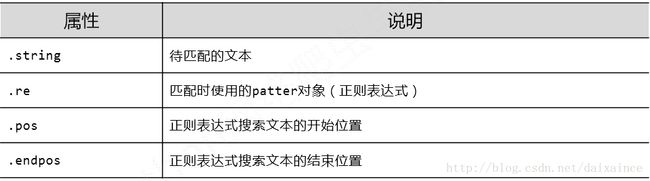
主要方法也是四个:

使用最多的是group方法,通常match.group(0)表示匹配的第一个字符串。match也可用于if的判断,匹配成功,则if match结果为真。
3.3 贪婪匹配和最小匹配
re库匹配中,会遇到这种情况:’PY.*N’在匹配’PYANBNCNDN’时有多种匹配,那么,具体匹配哪一种呢?
re库中的匹配默认使用贪婪匹配,即输出匹配最长的子串,可以通过增加’?’的方式使其进行最小匹配,如将上述改为’PY.*?N’,则得到最短的匹配子串。不仅在’*’中可以,在’+’、’?’、’{m,n}’后面都可以增加’?’以进行最小匹配。只要长度输出可能不同,就可以增加,使其输出最小匹配。