solr+zookeeper集群搭建
1.虚拟机(VMware)
2.tomcat7 64位 下载地址: http://tomcat.apache.org/download-70.cgi
3.centos6.4 64位
4.linux下的64位jdk安装包,版本为6或以上
5. solr-4.3.1.tgz包 下载: http://archive.apache.org/dist/lucene/solr/
6. zookeeper-3.4.5.tar.gz包 下载: http://hadoop.apache.org/zookeeper/releases.html
2.tomcat7 64位 下载地址: http://tomcat.apache.org/download-70.cgi
3.centos6.4 64位
4.linux下的64位jdk安装包,版本为6或以上
5. solr-4.3.1.tgz包 下载: http://archive.apache.org/dist/lucene/solr/
6. zookeeper-3.4.5.tar.gz包 下载: http://hadoop.apache.org/zookeeper/releases.html
环境:
虚拟机环境centos6.4 64位系统 三台硬盘50G 内存的虚拟机 网卡模式是NAT(测试环境推荐使用NAT,实际生产时可使用桥接以便外网访问)
环境搭建:
1.安装虚拟机 (这里不做赘述)。
2.虚拟机安装成功后,用java –version命令查看是否自带OpenJdk,若有则卸载此jdk。(这里不做赘述)
3.为虚拟机安装jdk(这里不做赘述)。
4.为每台虚拟机配置结点映射(若不使用域名此步骤可忽略):以虚拟机master为例,修改 /etc/hosts 文件如下图

其中后面的master slave1和slave2是作为别名以便于与network中的HOSTNAME做映射。
ZooKeeper集群中具有两个关键的角色:Leader和Follower。
集群中所有的结点作为一个整体对分布式应用提供服务,集群中每个结点之间 都互相连接,
所以,在配置的ZooKeeper集群的时候,每一个结点的host到IP地址的映射都要配置上集群中其它结点的映射信息。
ZooKeeper采用一种称为Leader election的选举算法。在整个集群运行过程中,只有一个Leader,其他的都是Follower,
如果ZooKeeper集群在运行过程中 Leader出了问题,系统会采用该算法重新选出一个Leader。
因此,各个结点之间要能够保证互相连接,必须配置上述映射。
ZooKeeper集群启动的时候,会首先选出一个Leader,在Leader election过程中,某一个满足选举算的结点就能成为Leader。
整个集群的架构可以参考http://zookeeper.apache.org/doc/trunk/zookeeperOver.html#sc_designGoals
5.修改/etc/sysconfig里的network配置文件(这里以master为例):HOSTNAME=master
二、正式solrCloud集群搭建
Zookeeper Distributed模式集群搭建
首先要明确的是,ZooKeeper集群是一个独立的分布式协调服务集群,“独立”的含义就是说,
如果想使用ZooKeeper实现分布式应用的协调与管 理,简化协调与管理,任何分布式应用都可以使用,
这就要归功于Zookeeper的数据模型(Data Model)和层次命名空间(Hierarchical Namespace)结构,
详细可以参考http://zookeeper.apache.org/doc/trunk/zookeeperOver.html。在设计你的分布式应用协调服务时,
首要的就是考虑如何组织层次命名空间。
Zookeeper集群的机器个数推荐是奇数台,半数机器挂掉,服务是可以正常提供的
现在以master为例搭建zookeeper集群:
1.在根目录下新建soft文件夹,将zookeeper.3.4.5.tar.gz包上传至soft目录下并解压缩.
2.新建/soft/zookeeper-data 文件夹 //zookeeper的数据存储位置
新建/soft/zookeeper-data/logs 文件夹 // zookeeper的日志文件位置
3.将/soft/ zookeeper-3.4.5/ conf 下的zoo_sample.cfg文件名改为zoo.cfg 并修改zoo.cfg文件如下图:

或者使用域名
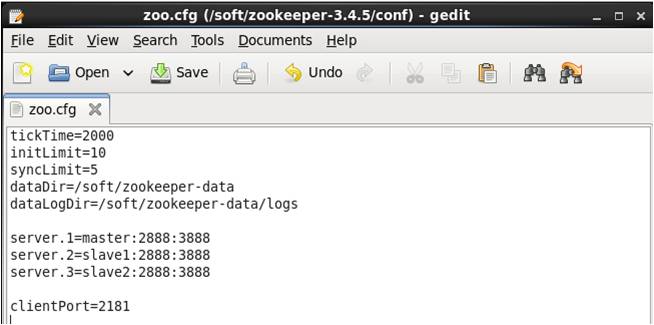
tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是5*2000=10秒。
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
dataLogDir: Zookeeper的日志文件位置。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
4.配置完成后把配置发送到其他两台机子
5.分别在每台机器的/soft/zookeeper-data 下创建myid文件存储该机器的标识码 比如server.1 的标识码就是 “1” myid文件的内容就一行: 1
6.配置完成后依次启动(注意启动前一定要关闭防火墙,否则zookeeper查看启动后的状态会查看不到各自的角色)master、 slave1和slave2的zookeeper服务,启动成功后查看启动状态如下:
master:

slave1:

slave2:

通过状态查询结果可以看出,slave1被选作为了Leader其余的两个结点是Follower。
另外,可以通过客户端脚本,连接到ZooKeeper集群上。对于客户端来说,ZooKeeper是一个整体(ensemble),
连接到ZooKeeper集群实际上感觉在独享整个集群的服务,所以,你可以在任何一个结点上建立到服务集群的连接。
Solrcloud分布式集群搭建
1.将apache-tomcat-7.0.37-windows-x64包上传至soft下并解压
2.在本地解压solr-4.3.1.tgz包,解压后找到solr-4.3.1\example\webapps\solr.war并将solr.war解压至solr文件夹。
3.将solr-4.3.1\example\lib\ext下的jar包放到solr\WEB-INF\lib下。
4.(以其中的一台虚拟机master为例)创建/usr/local/solrcloud目录 /usr/local/solrcloud/config-files目录和/usr/local/solrcloud/solr-lib目录。
5.在/usr/local/solrcloud/config-files目录下放置apache-solr-4.3.1\example\solr\collection1\conf 下的所有文件。
6.在目录/usr/local/solrcloud/solr-lib目录下放置solr\WEB-INF\lib下的所有jar包。
7.将solr上传至/soft/apache-tomcat-7.0.37/webapps下。
8.添加停词,扩展词,ik分词器:下载IKAnalyzer包,将IKAnalyzer解压文件夹下的stopword.dic和IKAnalyzer.cfg.xml复制到tomcat/webapps/solr/WEB-INF/classes下,再新建一个ext.dic,里面的格式和stopword.dic一致。并修改IKAnalyzer.cfg.xml如下所示,可以配置多个停止词或者扩展词库文件(具体详细内容可见http://lucien-zzy.iteye.com/blog/2002087)。
Xml代码

- <properties>
- <comment>IK Analyzer 扩展配置comment>
- <entry key="ext_dict">ext.dic;entry>
- <entry key="ext_stopwords">stopword.dic;stopword_chinese.dic;entry>
- properties>
Ik分词器配置见http://lucien-zzy.iteye.com/blog/2002087
9.创建solr的数据目录/soft/solr-cores并在该目录下生成solr.xml 这是solr的核配置文件
Xml代码
- xml version="1.0" encoding="UTF-8" ?>
- <solr persistent="true">
- <logging enabled="true">
- <watcher size="100" threshold="INFO" />
- logging>
- <cores defaultCoreName="collection1" adminPath="/admin/cores" host="${host:}" hostPort="8080" hostContext="${hostContext:solr}" zkClientTimeout="${zkClientTimeout:15000}">
- cores>
- solr>
这里,我们并没有配置任何的core元素,这个等到整个配置安装完成之后,通过SOLR提供的REST接口,来实现Collection以及Shard的创建,从而来更新这些配置文件。
10.创建/soft/apache-tomcat-7.0.37/ conf/ Catalina 目录 和/soft/apache-tomcat-7.0.37/conf/Catalina/localhost目录
11.在/soft/apache-tomcat-7.0.37/conf/Catalina/localhost 下创建solr.xml
Xml代码
- xml version="1.0" encoding="UTF-8"?>
- <Context docBase="/soft/apache-tomcat-7.0.37/webapps/solr" debug="0" crossContext="true">
- <Environment name="solr/home" type="java.lang.String" value="/soft/solr-cores" override="true"/>
- Context>
此文件为Solr/home的配置文件
12.修改tomcat/bin/cataina.sh 文件,在最上方加入
JAVA_OPTS="-DzkHost=master:2181,slave1:2181,slave2:2181"
或直接使用ip JAVA_OPTS="-DzkHost=192.168.91.128:2181,192.168.91.129:2181,192.168.91.130:2181"
加入以上内容其实就是指明了zookeeper集群所在位置。
13.将以上配置分别发到其他两台机子。
14.SolrCloud是通过ZooKeeper集群来保证配置文件的变更及时同步到各个节点上,所以,需要将配置文件上传到ZooKeeper集群中:执行如下操作(以下ip均可使用域名进行操作)。
Java代码
- java -classpath .:/usr/local/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 192.168.91.128:2181,192.168.91.129:2181,192.168.91.130:2181 -confdir /usr/local/solrcloud/config-files/ -confname myconf
链接zookeeper的配置内容:
Java代码
- java -classpath .:/usr/local/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -cmd linkconfig -collection collection1 -confname myconf -zkhost 192.168.91.128:2181,192.168.91.129:2181,192.168.91.130:2181
操作如图:

15.上传完成以后,我们检查一下ZooKeeper上的存储情况:
Java代码
- [root@master ~]# cd /soft/zookeeper-3.4.5/bin
- [root@master bin]# ./zkCli.sh -server 192.168.91.128:2181
- ...
- [zk: 192.168.91.128:2181(CONNECTED) 0] ls /
- [configs, collections, zookeeper]
- [zk: 192.168.91.128:2181(CONNECTED) 1] ls /configs
- [myconf]
- [zk: 192.168.91.128:2181(CONNECTED) 2] ls /configs/myconf
- [admin-extra.menu-top.html, currency.xml, protwords.txt, mapping-FoldToASCII.txt, solrconfig.xml, lang, stopwords.txt, spellings.txt, mapping-ISOLatin1Accent.txt, admin-extra.html, xslt, scripts.conf, synonyms.txt, update-script.js, velocity, elevate.xml, admin-extra.menu-bottom.html, schema.xml]
- [zk: 192.168.91.128:2181(CONNECTED) 3]
16.启动tomcat,首先启动master结点上的tomcat
这时候,SolrCloud集群中只有一个活跃的节点,而且默认生成了一个collection1实例,这个实例实际上虚拟的,因为通过web界面无法访问http://192.168.91.128:8080/solr/,看不到任何有关SolrCloud的信息,如图所示:
17.启动其他两个结点上的tomcat
18.查看ZooKeeper集群中数据状态:
这时,已经存在3个活跃的节点了,但是SolrCloud集群并没有更多信息,
访问http://192.168.91.128:8080/solr/后,同上面的图是一样的,没有SolrCloud相关数据。
19.创建Collection、Shard和Replication
创建Collection及初始Shard:
通过REST接口来创建Collection
Java代码
- curl 'http://192.168.91.128:8080/solr/admin/collections?action=CREATE&name=mycollection&numShards=3&replicationFactor=1'
上面链接中的几个参数的含义,说明如下:
name 待创建Collection的名称
numShards 分片的数量
replicationFactor 复制副本的数量
操作如图:

执行上述操作如果没有异常,已经创建了一个Collection,名称为mycollection,而且每个节点上存在一个分片。这时,也可以查看ZooKeeper中状态:

可以通过Web管理页面,访问http://192.168.91.128:8080/solr/#/~cloud查看SolrCloud集群的分片信息,如图所示:

由上图可以看到,对应节点上SOLR分片的对应关系:
shard1 192.168.91.130 slave2
shard2 192.168.91.129 slave1
shard3 192.168.91.128 master
实际上,我们从master节点可以看到,SOLR的配置文件内容,已经发生了变化,如下所示: 
我们可以再通过REST接口分别在slave1、slave2结点上创建两个collection,分别命名为mycollection1、mycollection2
创建后的访问链接如图:
创建Replication:
下面对已经创建的初始分片进行复制:
master结点 上的分片shard1已经存在slave2,现在我们复制分片到master和slave1上
执行操作:
Java代码
- curl 'http://192.168.91.128:8080/solr/admin/cores?action=CREATE&collection=mycollection&name=mycollection_shard1_replica1&shard=shard1'
Java代码
- curl 'http://192.168.91.129:8080/solr/admin/cores?action=CREATE&collection=mycollection&name=mycollection_shard1_replica2&shard=shard1'
操作如图:

访问链接查看效果图:

此时在master结点的slave2的shard1分片上多了两个副本,名称分别为:mycollection_shard1_replica1和mycollection_shard1_replica2
我们再次从master节点可以看到,SOLR的配置文件内容,又发生了变化,如下所示:
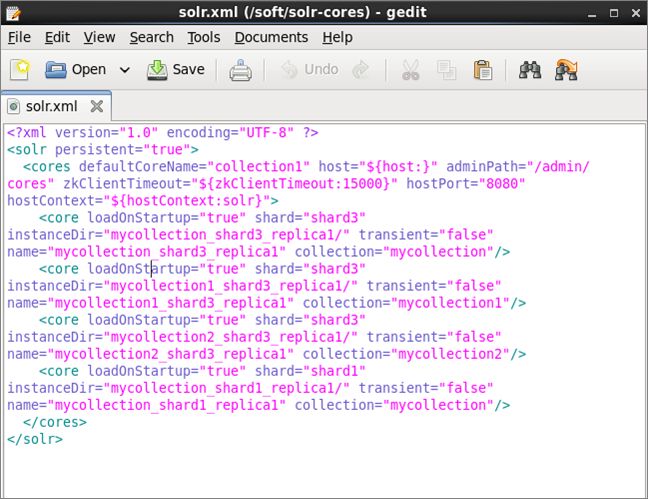
到此为止,我们基于3个物理节点,配置完成了SolrCloud集群多结点的配置。
三、索引操作实例
Java代码
- import java.io.IOException;
- import java.net.MalformedURLException;
- import java.util.ArrayList;
- import java.util.Collection;
- import org.apache.solr.client.solrj.SolrQuery;
- import org.apache.solr.client.solrj.SolrServer;
- import org.apache.solr.client.solrj.SolrServerException;
- import org.apache.solr.client.solrj.impl.CloudSolrServer;
- import org.apache.solr.client.solrj.response.QueryResponse;
- import org.apache.solr.common.SolrDocument;
- import org.apache.solr.common.SolrDocumentList;
- import org.apache.solr.common.SolrInputDocument;
- /**
- * SolrCloud 索引增删查测试
- * @author ziyuzhang
- *
- */
- public class SolrCloud {
- private static CloudSolrServer cloudSolrServer;
- private static synchronized CloudSolrServer getCloudSolrServer(final String zkHost) {
- if(cloudSolrServer == null) {
- try {
- cloudSolrServer = new CloudSolrServer(zkHost);
- }catch(MalformedURLException e) {
- System.out.println("The URL of zkHost is not correct!! Its form must as below:\n zkHost:port");
- e.printStackTrace();
- }catch(Exception e) {
- e.printStackTrace();
- }
- }
- return cloudSolrServer;
- }
- private void addIndex(SolrServer solrServer) {
- try {
- SolrInputDocument doc1 = new SolrInputDocument();
- doc1.addField("id", "421245251215121452521251");
- doc1.addField("area", "北京");
- SolrInputDocument doc2 = new SolrInputDocument();
- doc2.addField("id", "4224558524254245848524243");
- doc2.addField("area", "上海");
- SolrInputDocument doc3 = new SolrInputDocument();
- doc3.addField("id", "4543543458643541324153453");
- doc3.addField("area", "重庆");
- Collection
docs = new ArrayList (); - docs.add(doc1);
- docs.add(doc2);
- docs.add(doc3);
- solrServer.add(docs);
- solrServer.commit();
- }catch(SolrServerException e) {
- System.out.println("Add docs Exception !!!");
- e.printStackTrace();
- }catch(IOException e){
- e.printStackTrace();
- }catch (Exception e) {
- System.out.println("Unknowned Exception!!!!!");
- e.printStackTrace();
- }
- }
- public void search(SolrServer solrServer, String String) {
- SolrQuery query = new SolrQuery();
- query.setQuery(String);
- try {
- QueryResponse response = solrServer.query(query);
- SolrDocumentList docs = response.getResults();
- System.out.println("文档个数:" + docs.getNumFound());
- System.out.println("查询时间:" + response.getQTime());
- for (SolrDocument doc : docs) {
- String area = (String) doc.getFieldValue("area");
- Long id = (Long) doc.getFieldValue("id");
- System.out.println("id: " + id);
- System.out.println("area: " + area);
- System.out.println();
- }
- } catch (SolrServerException e) {
- e.printStackTrace();
- } catch(Exception e) {
- System.out.println("Unknowned Exception!!!!");
- e.printStackTrace();
- }
- }
- public void deleteAllIndex(SolrServer solrServer) {
- try {
- solrServer.deleteByQuery("*:*");// delete everything!
- solrServer.commit();
- }catch(SolrServerException e){
- e.printStackTrace();
- }catch(IOException e) {
- e.printStackTrace();
- }catch(Exception e) {
- System.out.println("Unknowned Exception !!!!");
- e.printStackTrace();
- }
- }
- /**
- * @param args
- */
- public static void main(String[] args) {
- final String zkHost = "192.168.91.128:2181,192.168.91.129:2181,192.168.91.130:2181";
- final String defaultCollection = "mycollection";
- final int zkClientTimeout = 20000;
- final int zkConnectTimeout = 1000;
- CloudSolrServer cloudSolrServer = getCloudSolrServer(zkHost);
- System.out.println("The Cloud SolrServer Instance has benn created!");
- cloudSolrServer.setDefaultCollection(defaultCollection);
- cloudSolrServer.setZkClientTimeout(zkClientTimeout);
- cloudSolrServer.setZkConnectTimeout(zkConnectTimeout);
- cloudSolrServer.connect();
- System.out.println("The cloud Server has been connected !!!!");
- //测试实例!
- SolrCloud test = new SolrCloud();
- // System.out.println("测试添加index!!!");
- //添加index
- // test.addIndex(cloudSolrServer);
- // System.out.println("测试查询query!!!!");
- // test.search(cloudSolrServer, "id:*");
- //
- // System.out.println("测试删除!!!!");
- // test.deleteAllIndex(cloudSolrServer);
- // System.out.println("删除所有文档后的查询结果:");
- test.search(cloudSolrServer, "zhan");
- // System.out.println("hashCode"+test.hashCode());
- // release the resource
- cloudSolrServer.shutdown();
- }
- }
注:别忘了修改核心配置文件schema.xml,要有id 和 area,注意类型的匹配。
上传配置文件到ZK里
/data/hedanhua/solr-5.2.1/server/scripts/cloud-scripts/zkcli.sh -zkhost 192.168.10.156:2181,192.168.10.155:2181,192.168.10.154:2181/solr -cmd upconfig -collection userinfo -confdir /data/hedanhua/solr-5.2.1/server/solr/configsets/data_driven_schema_configs/conf/ -confname userinfo