HADOOP学习笔记总结二:分布式计算框架mapreduce
一、mapreduce 设计理念
移动计算不移动数据
1、split数据切片
2、MAP过程
3、shuffle过程
4、reduce过程
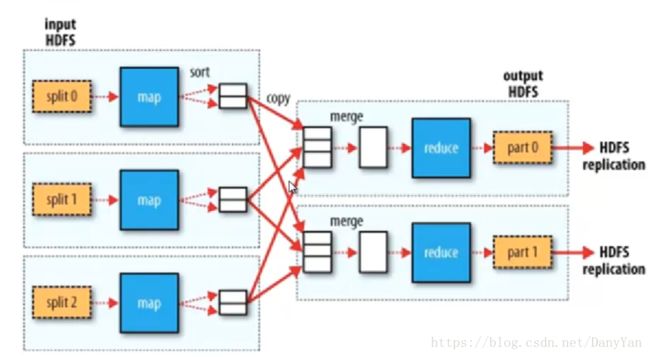

二、shuffler过程

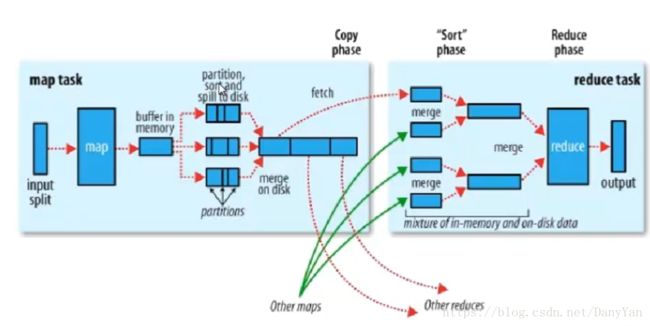
partition过程默认hash模计算,根据reduce 的数量来决定,分好区后,reduce 自已fetch自己的那个部分后,再merge操作,可以解决所谓的数据倾斜问题。
sort排序,为后面的reduce group等操作事先排序,减轻reduce的计算负担
spill to disk 写入磁盘

注意其中的combiner的merge是可以不需要的。


三、split切片
很多人可能认为在hadoop中的split和block是一样的,可能是因为hadoop在默认情况下split的大小和hdfs文件分块大小是一样的导致的。
首先:split是mapreduce 的概念,是对应一个maptask 的输入,而block是hdfs中的文件块。
其次:split默认与block的大小一样,是因为mapreduce的FileInputFormat类中有个getSplits() 方法对文件进行split计算,
算法:
Math.max(minSize, Math.min(maxSize, blockSize))
其中minisize 与maxsize的值可以通过配置文件设置,可以发现,如果blockSize小于maxSize && blockSize 大于 minSize之间,那么split就是blockSize,如果blockSize小于maxSize && blockSize 小于 minSize之间,那么split就是minSize,如果blockSize大于maxSize && blockSize 大于 minSize之间,那么split就是maxSize。

四、maptask与reducetask个数的决定
从shuffle过程的图示中可以知道 ,一个Split对应着一个maptask,所以具体有多少个maptask,得看split的大小,得看上述设置
而reduce的个数,则可以通过应当程序 显示的设置:如job.setNumReduceTasks(100),但具体有哪些因素有关呢?
1、 设置mapred.tasktracker.reduce.tasks.maximum的大小可以决定单个tasktracker一次性启动reduce的数目,但是不能决定总的reduce数目。setNumReduceTasks(100)表示总的 REDUCE的数目。
2、但有个问题,有的时候虽然启动了100个 reduce,但可能只有50个在干活,为什么?
shuffle的过程,根据我们的业务把数据分成若干partition,每个partition的数据由对应的一个reducer来处理,需要根据key的值决定将这条
默认的分区是使用:hashpartitioner方法,可以自定义重写getPartition方法来决定partition的个数:
public class HashPartitioner
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
基中:key的hash值,与numReduceTasks两个 参数决定。