Scrapy爬取ammmi图片
Scrapy爬取ammmi图片
相关配置:
python version:3.7
IDE:Pycharm
environment:windows10
Framework:Scrapy
相关链接:
Website:
github:https://github.com/daorenfeixueyuhua/PythonStudy.git
ProjectName:ammmi
前期设计:
base_url: https://www.ammmi.com/category/dongmantupian
// 获取某类图片的网页的列表
x = response.xpath('//div[@class="mi_cont "]//ul/li/h3/a/@href').extract()
下一列:
base_url+'page/pagesize'
图片种类名称:
// 获取图片种类名称
x = response.xpath('//h2[@class="titletips"]/text()').extract_first()
// 获取图片url
图片下载:
x = response.xpath('//a[@class="NavLinks"]/@href').extract_first()
// 命名图片
picture_name = x[58:-4]
web_name = 'ammmi'
save_directory= '../resource/' + web_name + '/' + title + '/' + picture_name + '.jpg'
// Item设计
Item(title,picture_name,download_url,save_directory)源码:
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class AmmmiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 图片标题
title = scrapy.Field()
# 图片名
picture_name = scrapy.Field()
# 图片下载地址
image_url = scrapy.Field()
# 图片保存地址
image_path = scrapy.Field()
# pass
ammi_sipder.py
import scrapy
from ammmi.items import AmmmiItem
class AmmiSipder(scrapy.Spider):
# spider name
name = 'ammmi'
# 表示允许爬虫爬的网站
allowed_domains = ['www.ammmi.com']
count = 0
page_num = 1
web_name = 'ammmi'
base_url = 'https://www.ammmi.com/category/dongmantupian'
start_urls = ['https://www.ammmi.com/category/dongmantupian']
def parse(self, response):
# 获取图片urls
img_list = response.xpath('//a[@class="NavLinks"]/@href').extract()
if len(img_list):
for img in img_list:
item = AmmmiItem()
item['title'] = response.xpath('//h2[@class="titletips"]/text()').extract_first()
item['picture_name'] = img[58:-4]
item['image_url'] = img
self.count += 1
# if self.count >= 50:
# return
yield item
page_list = response.xpath('//div[@class="mi_cont "]//ul/li/h3/a/@href').extract()
if len(page_list) == 0:
return
else:
for page in page_list:
# 进入某类图片html
yield scrapy.Request(page, callback=self.parse)
# 控制图片种类,并保证结束
if self.page_num >= 30:
return
self.page_num += 1
# 下一分页类图片
yield scrapy.Request(self.base_url + '/page/' + str(self.page_num), callback=self.parse)
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from scrapy.exceptions import DropItem
import os
from scrapy.utils.project import get_project_settings
from scrapy.pipelines.images import ImagesPipeline
class AmmmiPipeline(object):
def process_item(self, item, spider):
# r = requests.get(item['download_url'])
# path = '../resource/'
# if 'resource' not in os.listdir('../'):
# os.mkdir(path)
# dirs = os.listdir(path)
# if item['title'] not in dirs:
# os.mkdir('../resource/'+item['title'])
# with open(item['save_directory'], 'wb') as f:
# f.write(r.content)
return item
class AmmmiImagesPipeline(ImagesPipeline):
IMAGES_STORE = get_project_settings().get("IMAGES_STORE")
def get_media_requests(self, item, info):
yield scrapy.Request(item['image_url'])
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
# if not image_paths:
# raise DropItem("Item contains no images")
# if item['title'] not in os.listdir(self.IMAGES_STORE):
# os.mkdir(self.IMAGES_STORE + '/' + item['title'])
# 更改文件名
# os.rename(self.IMAGES_STORE + "/" + image_paths[0], self.IMAGES_STORE + "/" + item['title'] + '/' + item['picture_name'] + '.jpg')
# 更改图片路径名
# item['image_path'] = self.IMAGES_STORE + "/" + item['title'] + '/' + item['picture_name']
# item['image_paths'] = image_paths
return item
注:item_completed去掉注释部分,即可实现按图片title目录分类保存图片,但是很抱歉,此处存在一个bug,只能保存一张不图片(若那位大佬发现,请告诉我,感激不敬,谢谢)。
settings.py
BOT_NAME = 'ammmi'
SPIDER_MODULES = ['ammmi.spiders']
NEWSPIDER_MODULE = 'ammmi.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'ammmi.pipelines.AmmmiPipeline': 300,
'ammmi.pipelines.AmmmiImagesPipeline': 300,
}
IMAGES_STORE = "../Images"
效果展示:

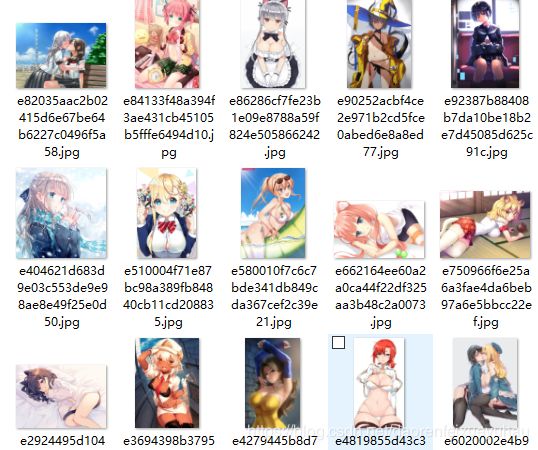
感兴趣的朋友,可以在github上克隆运行使用!
能力有限,不足之处,还请多多包涵!
谢谢!