机器学习 cs229学习笔记6(增强学习 reinforcement learning,MDP)
==========================================================================
上周生病再加上课余的一些琐事,这边的进度就慢下来了,本篇笔记基于 斯坦福大学公开课cs229 的 lecture16,lecture 17
==========================================================================
零:一些认识
涉及到机器人的操控的时候,很多事情可能并不是supervised和unsupervised learning能够解决的,比如说andrew ng之前一直提到的自动控制直升飞机,另一个例子就是下棋,有可能很久之前的一步棋就埋下了后面失败的伏笔,而机器很难去判断一步棋的好坏。这就是增强学习需要解决的问题。
注:这里的Value价值即是很多书上写的Q值,貌似也有点差别,在于Q可能是Q(s,a)的,是给定状态和一个动作之后的V值,但差异不大。
一:马尔科夫决策过程 (Markov decision processes)
马尔科夫决策是一个五元组,![]() ,用一个机器人走地图的例子来说明它们各自的作用
,用一个机器人走地图的例子来说明它们各自的作用
S:状态集:就是所有可能出现的状态,在机器人走地图的例子中就是所有机器人可能出现的位置
A:action,也就是所有可能的行动。机器人走地图的例子假设机器人只能朝四个方向走,那么A就是{N,S,E,W}表示四个方向
P:就是机器人在S状态时采取a行动的概率
γ:叫做discount factor,是一个0到1之间的数,这个数决定了动作先后对于结果的影响度,在棋盘上的例子来说就是影响了这一步
棋对于最结果的影响有多大可能说起来比较模糊,通过后面的说明可能会讲得比较清楚。
R:是一个reward function,也就是可能是一个![]() ,也可能是
,也可能是![]() ,对应来说就是地图上的权值
,对应来说就是地图上的权值
===============================================================================
有了这样一个决策过程,那么机器人在地图上活动的过程也可以表现为如下的形式:
![]()
也就是从初始位置开始,选择一个action到达另一个状态,直到到达终状态,因此我们这样来定义这个过程的价值:
![]()
可以看出越早的决定对价值影响越大,其后则依次因为γ而衰减
其实可以看出,给出一个MDP之后,因为各个元都是定值,所以存在一个最优的策略(ploicy),策略即是对于每个状态给出一个action,最优
策略就是在这样的策略下从任意一个初始状态能够以最大的价值到达终状态。策略用π表示。用
![]()
表示在策略π下以s为初始状态所能取得的价值,而通过Bellman equation,上式又等于:

注意这是一个递归的过程,在知道s的价值函数之前必去知道所有的s'的价值函数。(价值函数指的是Vπ())
而我们定义最优的策略为π*,最优的价值函数为V*,可以发现这两个东西互为因果,都能互相转化。
二.价值迭代和策略迭代(Value iteration & policy iteration)
///////////////价值迭代VI:////////////////////

这个过程其实比较简单,因为我们知道R的值,所以通过不断更新V,最后V就是converge到V*,再通过V*就可以得到最优策略π*,通
过V*就可以得到最优策略π*其实就是看所有action中哪个action最后的value值最大即可,此处是通过bellman equation,可以通过解bellman equation得到
所有的V的值,这里有一个动归的方法,注意马尔科夫决策过程中的P其实是指客观存在的概率,比如机器人转弯可能没法精确到一个方向,而不是指在s状态
机器人选择a操作 的概率,刚才没说清楚
在此说明,也就是说:

是一个客观的统计量。
/////////////策略迭代PI/////////////////////

这次就是通过每次最优化π来使π converge到π*,V到V*。但因为每次都要计算π的value值,所以这种算法并不常用
这两个算法的区别就是过程的区别,但我感觉本质上差别不大。(andrew说有不一样,至少看起来不一样……这个待查)
三.连续状态的MDP
之前我们的状态都是离散的,如果状态是连续的,下面将用一个例子来予以说明,这个例子就是inverted pendulum问题
也就是一个铁轨小车上有一个长杆,要用计算机来让它保持平衡(其实就是我们平时玩杆子,放在手上让它一直保持竖直状态)
这个问题需要的状态有:都是real的值
x(在铁轨上的位置)
theta(杆的角度)
x’(铁轨上的速度)
thata'(角速度)
/////////////////离散化///////////////////////////
也就是把连续的值分成多个区间,这是很自然的一个想法,比如一个二维的连续区间可以分成如下的离散值:

但是这样做的效果并不好,因为用一个离散的去表示连续空间毕竟是有限的离散值。
离散值不好的另一个原因是因为curse of dimension(维度诅咒),因为连续值离散值后会有多个离散值,这样如果维度很大就会造成有非常多状态
从而使需要更多计算,这是随着dimension以指数增长的
//////////////////////simulator方法///////////////////////////////
也就是说假设我们有一个simulator,输入一个状态s和一个操作a可以输出下一个状态,并且下一个状态是服从MDP中的概率Psa的分布,即:

这样我们就把状态变成连续的了,但是如何得到这样一个simulator呢?
①:根据客观事实
比如说上面的inverted pendulum问题,action就是作用在小车上的水平力,根据物理上的知识,完全可以解出这个加速度对状态的影响
也就是算出该力对于小车的水平加速度和杆的角加速度,再去一个比较小的时间间隔,就可以得到S(t+1)了
②:学习一个simulator
这个部分,首先你可以自己尝试控制小车,得到一系列的数据,假设力是线性的或者非线性的,将S(t+1)看作关于S(t)和a(t)的一个函数
得到这些数据之后,你可以通过一个supervised learning来得到这个函数,其实就是得到了simulator了。
比如我们假设这是一个线性的函数:
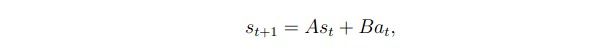
在inverted pendulum问题中,A就是一个4*4的矩阵,B就是一个4维向量,再加上一点噪音,就变成了:其中噪音服从![]()
![]()
我们的任务就是要学习到A和B
(这里只是假设线性的,更具体的,如果我们假设是非线性的,比如说加一个feature是速度和角速度的乘积,或者平方,或者其他,上式还可以写作:)
![]()
这样就是非线性的了,我们的任务就是得到A和B,用一个supervised learning分别拟合每个参数就可以了
四.连续状态中得Value(Q)函数
这里介绍了一个fitted value(Q) iteration的算法
在之前我们的value iteration算法中,我们有:
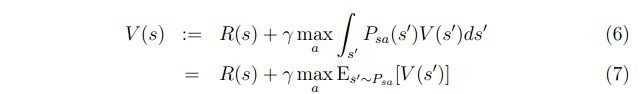
这里使用了期望的定义而转化。fitted value(Q) iteration算法的主要思想就是用一个参数去逼近右边的这个式子
也就是说:令
![]()
其中![]() 是一些基于s的参数,我们需要去得到系数
是一些基于s的参数,我们需要去得到系数![]() 的值,先给出算法步骤再一步步解释吧:
的值,先给出算法步骤再一步步解释吧:

算法步骤其实很简单,最主要的其实就是他的思想:
在对于action的那个循环里,我们尝试得到这个action所对应的![]() ,记作q(a)
,记作q(a)
这里的q(a)都是对应第i个样例的情况
然后i=1……m的那个循环是得到是最优的action对应的Value值,记作y(i),然后用y(i)拿去做supervised learning,大概就是这样一个思路
至于reward函数就比较简单了,比如说在inverted pendulum问题中,杆子比较直立就是给高reward,这个可以很直观地从状态得到衡量奖励的方法
在有了之上的东西之后,我们就可以去算我们的policy了: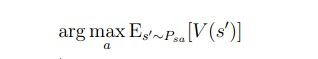
五.确定性的模型
上面讲的连续状态的算法其实是针对一个非确定性的模型,即一个动作可能到达多个状态,有P在影响到达哪个状态
如果在一个确定性模型中,其实是一个简化的问题,得到的样例简化了,计算也简化了
也就是说一个对于一个状态和一个动作,只能到达另一个状态,而不是多个,特例就不细讲了